多余的序
对于DAX,目前涉及到的很多概念及称谓(还在不断增加中),我总结了好久,都没有如愿。
软件是方便人用的,如果是让人越来越弄不明白,甚至走入迷途而不出来,这绝对不是DAX的初衷……。肯定是哪里出了问题!
到目前为止,关于DAX,我们其实就只聊了一个“列表"的慨念:
(1) 强调了一切DAX都是关于列表的;
(2) 介绍了列表的值列表和列表两种形态,以及它们的简单地区分方法--凡是使用了某个列表中全部列值(全集)的称为列表,反之,仅包含列表中部分列值的列表称之为值列表;
(3) DAX中列表与值列表的"引用、定义"的语义表达方式;
(4) 以及两种列表形态的运用(分别用于筛选+计算)等,即DAX中如何引用列表与定义值列表(具有行的行为的值列表),以用于DAX的筛选与计算…。
所有这些知识,其实是在学习与DAX沟通的方式,这是很重要的内容。 如果你搞不清或不知如何写一个正确的DAX公式。那么,很可能是由于你对于如何引用列表与定义值列表无从下手。如有必要,请回头再回顾一次该系列前面的内容,以加深理解。
如果你说,我只是想了解一下某个业务的结果、解决一下当前业务需求就好,或者只是想快捷式掌握这门语言。你可以模仿与业务相关的DAX公式,或者使用DAX三步经典运用(导入数据、简单建模与会写基本的元度量、数据输出)即可。这是DAX的第一个阶段,事实上,这已经能让你解决70%左右的业务问题。
想要在DAX的世界里更进一步,则需要较大的付出与较长的时间实残,80%以上的人停留在这一阶段。
DAX的学习本身也是一个漏斗式的形状,前面需要理解的知识很多。你也许会问,那能不能简单点?可以,但是目前“臣妾”还做不到。DAX需要相当多的啰嗦!比如很多知识不需要一下子全了解,但起码需要你全部过滤一次 ,有一个大致的认识。
如果你是高手、高高手、或高大上、土豪,吃惯了大鱼大肉,不屑于这些简单的饭菜,那我这道菜(系列)也应该不是为你准备的。
为啥这么啰嗦?一次性啰嗦完,免得后面更啰嗦……。
接下来,我们需要搞清楚DAX计算的第一步:DAX如何在CALCULATE ( )定义的列表数据模型下计算,即数据模型里的DAX是如何进行列表计算的,以及如何操纵列表编写DAX计算。顺便分析一些在实际运用上经常遇到的一些问题。
在本部分以及接下来的一个部分,你可以参阅英文版的《DAX的圣经》一书的第3、4、5章中内相关内容。
第16式:CALCULATE的计算材料:列表
DAX 使用了一些独特的编程概念和模式,所以难以被充分利用和理解。传统的学习某种语言的方法对于DAX来说可能并不是最好的方法。因此,我们一直在讨论并提供与DAX沟通的有关列表的概念和理论,以便在你以后的 Power BI 工作中提供帮助。
其实我们已经明白:一个最基本的数据模型是由列表(包含列表类型)和列表关系组成,对于DAX计算,主要就是操纵列表的计算。这包括 DAX列表关系的数据模型以及基于它的列表筛选、列表计算,而组织列表的筛选和计算的两种方式概括为:引用列表和定义值列表。所以,DAX的关键是学习如何引用列值以及定义值列表。
1、理解DAX(CALCUALTE)的列表
其实有一条很清晰的思考列表的线索可供参考:
(1)整个数据模型由一个个关系列表构成;
(2)这些列表主要用于筛选和计算,因此,也就是有两类列表:即用于筛选的列表和用于计算的列表;
(3)由于DAX操纵列表的主要手段是运用函数功能。因此,自然地,所有DAX对应的函数可归为两类函数:用于筛选的函数以及用于计算的函数(包括时期函数这种即可用于计算又可用于筛选的函数),虽然这种分类并不一定对,但对于你理解DAX有很大帮助);
(4)所有这些列表,要体现在DAX公式中,需要引用列表以及定义值列表两种方式。一般来说,一个正常的DAX计算式或计算单元,引用的是指显式的列表(可能包含隐式的行行为,引擎能自动识别并执行的行为),定义的值列表为显式的行行为(可能包含隐式的列表行为--筛选或计算,引擎依据外部定义的显式执行行为)。
例如,如果要将隐式行(值列表)筛选转换为等效的显式列筛选,需要CALCULATE函数转换,而值列表转换为显式的列表,则需要表函数转换或使用任何函数的嵌套(接下来的内容将会介绍)。
你不必太当心"隐式"与"显式"。总之,只要引用列表与定义值列表都是正确的(比如放置在函数的正确的参数位置,该是列表不能值列表……。这己经就很不容易了)。
DAX 提供了对列表的操纵能力:加载来自几乎任意不同位置的列表--其实是业务维度或元素,然后建立列表之间的关系连接、筛选组合以实现列表的“合纵连横”,来获取需要的列表子集(虽然还没有说到列表的关系,但我们已提到过几次了)用于计算。
其中的“DAX对列表的操纵能力,即直接或通过函数引用列表与定义值列表构建DAX计算式”这一功能是核心,这也是是离业务数据的“最近的一公里”。这其中了解如何创建有效的DAX 度量值,将帮助你最大限度地利用你的数据。
只要你理解了DAX的列表概念,对于只有Excel初级或者从没有学过任何代码的人,都可以开始学习power BI。你也可以理解为:一大堆关于DAX的语法、函数、上下文(即行、列筛选,下同)等,最后都是关于列表的。
2、列表组成方式
虽然,我们习惯于舒适的单元格或表方式的观察,但在理解数据模型的列式特点时,请以一个一个列表的构成形式去观察和思考。有时候实在是有点弄不明白列表间的关系时,你可以设置一个列表业务结构统计表,例如下图:
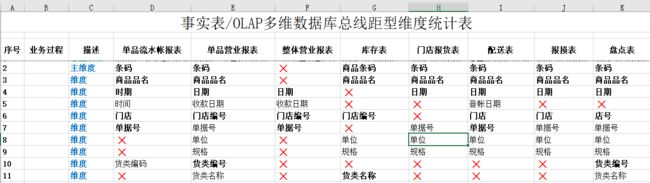
如果需要将这些列表建模以用于业务需要,那么,起码要求:这些维度表中应该包含最细的粒度,并始终保持粒度的一致性,以及考虑是否能搭建列表间的关系,并考虑这些列表维度是不是足够满足业务需求。
例如,针对前面图示的简单建模思考,下一步还需要了解你工作的分析流(即列表映射转化为业务的架构)。
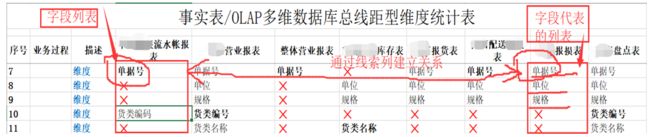
将常用的列表统计在一起,以便于有一个整体性的业务规划架构图表:知道哪些维度列表是属于哪个业务,哪些维度列表组合起来又是哪个业务系列或系统等等(维度建模里叫总线矩型设置)。 当然,如果你非常熟悉你的业务数据,是不需要这些准备的。
一般地,为了有一个全局的、易理解的界面,你可以回到列表关系数据视图,这里是DAX数据模型全景区(严格的说应该叫:关系型数据仓库,它存储的是列表)。下图:数据模型的列表存放区域:
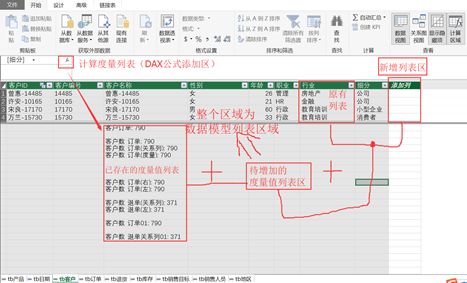
在整个你所见到的数据模型里,包括:原列表、计算列、度量值列表、Power BI里的新表和参数表列表等,以及所有这些列表的关系和类型,它们共同组成数据模型。
你迫不及待的想说,这其实只是数据模型里的各个部分的组合嘛。由于数据摸型的只读性、整体性特点,其实是可以考虑将所有的列表放置在一起 (数据模型本身就是一个整体的样子)。
不过,第一,这可能会使管理不便(至少,由于各列表的行值不同、行值较小的列表需要更多的空值填充,横向的列表也会太长,不利于列表属性管理。也会分不清数据来源并分别维护,例如一旦更新,则全部数据都直接一次性全部被更新而无法干涉)。
第二,所有的DAX计算更多的时候并不总是整个数据模型等……。
3、列表行为与业务事实对应
既然数据模型由一个一个列表组成,那么,选择一个或多个列表的列值和选择一个或多个列表对于DAX来说本质上是等效的(并没有区别)。我们往往需要的是度量值的输出结果,而度量值的结果则可能是数据模型中一个或多个列表的组合变化、综合影响的结果,这与我们复杂的业务需求相映射对应。
因此,维度(列表)建模能够将业务需求(表现为数据行为)定义为一个数据模型,以及将列表数据看做数据行为然后映射为现实中的事实场景。
这就像古时候的算账先生,给你一个账本,一个算盘,要你算出一片“天地”来.....。不过是现在的账本与算盘都进化为列表数据与电脑及软件工具了而已。比如,一个数据模型可以代表一个或多个业务行为,因而业务问题的处理可以转化为对数据模型中列表数据的处理(在数据模型中探索数据,利用维度来观测特定度量值,并分析数据行为以驱动业务)。
所有这些,也就是前面所说的数据世界就是:列表(维度)+度量。
4、Excel OLAP Cube 工具
为了理解列表模型的这种列表组合特点,我们使用Excel OLAP Cube工具,直接从多维数据“立方体”中取得数据,可能更能直观的了解到这种组合方式特点(仅仅作为了解这种特点而已,因为两者并不是一回事)。
你需要点击任意透视表,分析-->OLAP 工具-->转换为公式,将透视表完全转换为数据单元格,如下图:
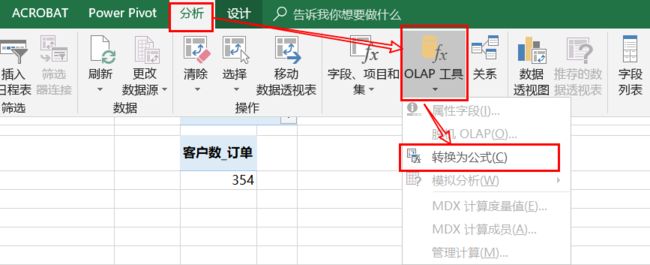
转变后,在透视表里已被修改的字段将恢复为到原来的数据模型列的字段名。Excel给出了一组Cube类函数,分别对应透视表的行、列、值结果。CUBE函数非常直观,其结构如下:
CUBE函数( 数据列表,列表表达式1,列表表达式2……,列表表达式N )
其中列表的表达式可以是列表字段,也可以是度量值,最终它们给出的组合结果实际就是从数据模型被筛选出来的结果。每一个公式代表一个数据模型里的一个列表或列表值。换句话说,由Cube公式指定的结果,可以任意移动组合、复制,只要复制该公式就行。
图示:列表模型的多维度Cube结构可以移动组合、复制......。
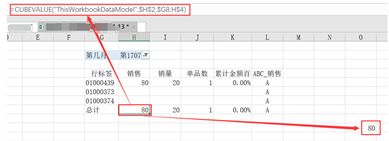
由Cube公式指定的结果,任然接受筛选器筛选(在转换前事先放置好),并可再添加筛选器。图示:列表模型的多维度Cube结构的筛选更新。
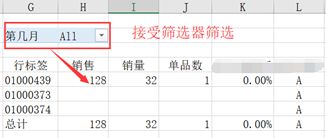
同样,改变公式里的参数值就改变了筛选条件,也就改变了对应的结果值;当然,删掉某个公式,该公式指代的值也将被删除。
由Cube公式特点可知,值由行、列、筛选器共同决定,其结果就是内部的列表筛选。我们试着将绝对引用单元格换成列表(或度量值),上图中$G5来自:’商品信息表’里的[条码]列中的01000439这个条码,$I4对应的是度量值--[销量]。代替后结果一样。
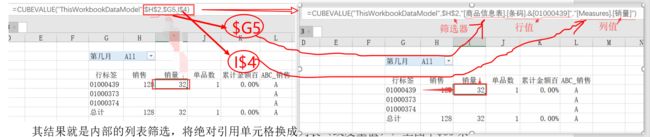
图示说明:Cube公式值由行、列、筛选器共同决定(本质为列表筛选)。
Cube中的"“数据列表”总是用 "ThisWorkbookDataModel"来表示,称为:当前工作薄数据模型。也就是说,它每次都需要先遍历整个工作薄数据模型,再筛选出列表结果。从这点上说,Cube出结果会相对较慢。
运用OLAP Cube的以上特点,可以将我们想要的数据任意的组合在一起。以满足我们一些特殊的需求。
通过以上介绍,我们知道,数据模型可以输出任一多维的Cube值。但这种由公式指代的cube值,一旦需要改变,只能修改公式。在实际运用中,我们需要的是具有动态性、多样式、不确定性的列表筛选,并根据需要随时能更改列表维度与度量值。这就需要超级透视表:Powerpivot以及另一个操作列表的列表函数计算:DAX。
DAX原理与Cube一样,引用列表筛选以获得需要的列表组合计算,它的基本公式:
CALCULATE(计算列表,列表筛选1,…,列表筛选N)
所以,这里的CALCULATE的含义是“引用或定义列表集计算”。
我们已经知道,数据模型是一组由关系链连接的列表(一列或多列数据的组合),也叫表格模型或列表数据。在Excel中,我们通常将列中的一行引用为一个单元格(一条记录),但在数据模型里,因为没有行的概念,它以列表(表格)来组织数据。
在数据模型里你见到的一个个表(同一个事实体的列表集)本身就已经是一个数据模型,因而直接可以在这个列表模型下计算,尽管这是最简单的形式,却包括数据模型的基本元素—列表。当然只有一个列值的也称为列表,它是一个值的列表。
5、单元格与列表
在Excel中,您可以对单元格执行计算,即用行、列坐标来引用单元格。例如,你可以编写如下的公式:
=(A1 * 0.85)+ B2*0.25
在DAX中,由于并没有单元格的概念以及不存在交叉的坐标。DAX适用于列表,而不是单元格。所以,每当你写DAX表达式时,它们只会引用表或列表(‘ 或 [ 开始)。我们将这种列式的数据称为“格式表”(表格格式或列表数据)。
格式表或列式数据的概念在Excel中并不新鲜。实际上,如果您将Excel里某个单元格数据区域范围定义为列表.( CTRL+A再CTRL+T,或直接快捷键CTRL+L)处理后,就可以在Excel中像列表引用一样编写引用表或列表的表达式。你还可以使用“开始”-->套用表格格式-->任选一个格式,弹出一个“创建表”的会话框,然后确定,来将数据转换为表格格式。
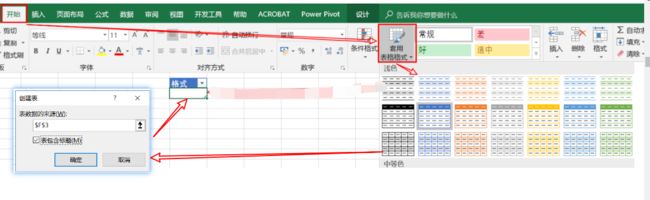
单元格与表格格式的名称:

上图的右边,将单元格转化为数据格式后,会自动出现列名:列表,因为数据模型表必须至少需要一个列表--用一个字段名指代)。如图,你会看到[xinID]列计算将引用同一表中的列表来定义计算列表达式,而不是工作簿中的单元格。
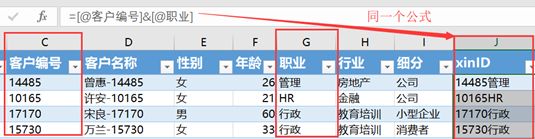
使用Excel的列式计算,注意到列的编写方式为:[@列名称],使用该方式,你不需要为每个单元格都指定这个表达式,而只需单击单击任何一个单元格书写代码,Excel会为自动赋予正确的整列的值。
当然,在Excel里,可以使用标准单元格引用(这种情况下,上述单元格的公式将写成:C2&G2 ,然后复制到整列)。而使用列引用的优点:可以在列的所有单元格中自动使用相同的表达式(内部自动完成列的一次性计算)。
注意到上述公式计算正确。那么,对于列的编写方式:[@列名称],其意义应包含具备显式的列表筛选行为以及隐式的行筛选行为。所以,这里的@ 符号表示为:“定义当前列表的值(相当于添加行筛选)”。
当然,你已经知道,DAX的计算列引用。例如,在DAX中,编写上述公式为:
xinID=‘订单表‘’[客户编号]&‘订单表‘[职业]
另一方面,在DAX中,引用列表需要指定表名称,因为DAX计算所在的数据列表集,会有许多不同的组合方式(并不总在一个表里计算)。而在Excel中,你无需提供表名,因为Excel公式在当前这个表上工作(也就是我们将要说到的当前列表集,计算列表始终是所在的活动列表中创建,这其实相当于DAX的计算列)。
DAX中的许多函数功能与Excel里相同函数的功能相同。DAX的语法不同于Excel的一个最重要方面是:引用列表的方式。前面说到,@表示“定义当前列表中的列值”。如果在Excel中要引用整个列(即该列中的所有行),这可以通过引用[字段名称],即删除@ 符号来实现。
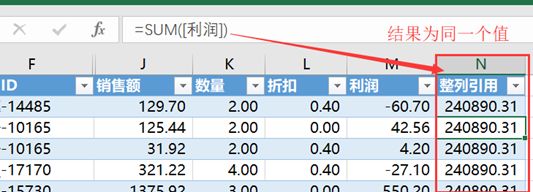
你应该会发现一个问题,如图:公式处理后的[整列引用] 列的值在所有行里值是相同的,因为它是整个[利润]列的总计(该总计列值被填充到整列)。你可以回到该系列的第1、2部分,使用前面关于该计算列问题的解释(比如嵌套CALCULATE显式化处理)。
你会发现,Excel里的列表数据,也是一种数据模型。某种意义上,Powerpivot(DAX数据模型)只是Excel的一个额外功能插件而已。Excel本身具有列表功能,只是在数据量、存储、不同列表关系连接、建模计算等问题上,原有的Excel设置无法满足。
我们说,在DAX里,虽然列表改变与列表值的改变本质上是一样的(都指向列表范围的改变)。但是,你必须让DAX明白:你使用的是一个或多个值的列表,还是列表里的某一个或多个值的列值。所以,我们使用引用列表以及定义值列表两种方式来指代。
难于理解、也是需要强调的是:这仅仅是一种方式。因为一旦你指明使用的是列表中的某个或多个值(整个列值的列表或部分列值的值列表),那么,其实引擎使用的还是由这些值而构成的列表(因为引擎能识别的只有列表。即便不是如此,也需要通过CALCULATE显式转换、或FILTER等表函数处理成列表,数据结果也是结果列表,因此,你不能将其导出为单元格式的ExceⅠ值数据。你也可以理解值列表只是一个过渡的中间列表形态而矣),即一个或多个值的新列表(因为DAX里并没有行值的概念)。
很多学习DAX的人,都卡在了这个比较绕口的问题上。
在Excel中公式工作时,可以一步一步执行计算步骤。最简单的:你在写完一个函数公式后,一个习惯性动作就是写完公式,然后下拉或双击下拉填充数据到整列。该动作在DAX中,它会根据定义出的新列表进行自动计算填充。可以理解为:在DAX里,是按列式计算的。
比如,一个列表组合(即列表集)可能很多度量公式中都会用到它,从而你可能会使用DAX来定义它(例如度量值列表),以固定住这个列表集。
例如,很多时候,都需要回到数据模型Sales表的[销售]列计算,那么,你可能的做法是使用某个聚合函数功能来引用该列表,如:SUM(Sales[销售])。之后,使用哪些列表与[销售]列去关联、组合、筛选以便获得该SUM(Sales[销售]元度量在不同情形下的结果。
有了这种观念后,你仔细想想,其实一个业务场景中,关键的元度量(配合求和、平均、计数等聚合计算方式)并不多。所以,我们的建议是,可以将经常需要的元度量事先设置好。
目前,在Powerpivot里有几类列表(见前面的列表视图示意图):原数据模型里的元列表、新建列列表、度量值列表,以及Power BI里支持的新表(新建列表或新建表)、参数表。这些列表在需要的时候再拿出来(直接计算或再与其他列表组合成新的列表集计算,也就是列表间的“合纵连横”)。
根据业务需要,你将使用不同列表组合来达到你的计算需求。所以DAX非常好学,不需要IT基础甚至是太多Excel基础,懂得如何组合列表就行。所以,所谓DAX能力,实际上就是你组织列表(引用列表与定义值列表)的能力!
就像有人给管理的一个定义:管理就是把合适的人放在正确的位置,做正确的事。我们借助这句话来给DAX操作(组织)列表的计算下一个通俗的定义:所谓DAX计算就是:选择合适的列表,引用或定义在正确的位置,做正确的计算。
我们似乎有了一种感觉:DAX似乎不存在IT能力之间的差异,如果您习惯于SQL语言,已经处理了许许多多的表,在DAX里只是列表组合而已。因为DAX中的计算关键就是查询一组由关系和函数连接的列表。从这个意义上来看,DAX似乎只是:找到需要的列表。在这点上,作为IT人,你将在DAX使用中只是比别人早一点认识到“表”的概念(还不是列表的概念),仅此而已。
由于列式特点的不易理解,DAX的列表计算,往往会让你始终怀疑、纠结于它是否真的是你需要的结果?这是由于你并没有弄明白DAX里的列表,它看起来像是摆在你面前的一堆模糊的数据……。
由于业务场景的不一样,列表内容的不同,以及列表组合的方式和条件更是多姿多彩。在Excel里使用函数公式,是不必担心它是如何工作的,总之,使用同样的公式,则会有同样的结果。比如,在Excel’里,一个最简单的公式是直接引用单元格;如 G2=B2。这时,你可能会问:
“什么是最简单的 DAX 公式?”
这个问题的最佳答案是:“不需要自行创建的公式”。也就是,比如你通过使用标准聚合函数直接引用某个列表所能完成的操作。几乎所有数据模型都可以被聚合函数进行筛选和计算。
例如,前面介绍的Sales[销售]列的 SUM 函数用于累加该列中的所有列值数字。简单说,也就是一个函数直接引用一个列表:函数名(列表)的方式,就是最简单的DAX计算公式。
销售:=SUM('订单'[销售额])
这种公式是元度量,同时也是最简单的、最早学会的DAX公式。你可以在它的基础上添加筛选、条件就会生成各种派生度量,最常见的方式是用于CALCUALATE()的第一参数:计算式。因此,一个函数直接引用一个列表:函数名([列表])的方式也是构成DAX计算的基本单元。
这同时也是我们学习DAX最基础的第一个阶段:运用一个函数引用一个列表,写出一个元度量。
该公式表示汇总计算所在列表的列值(SUM函数功能),因为它计算的总是整个列表--比如,所在数据模型的可见列表集的值或透视表的汇总值。
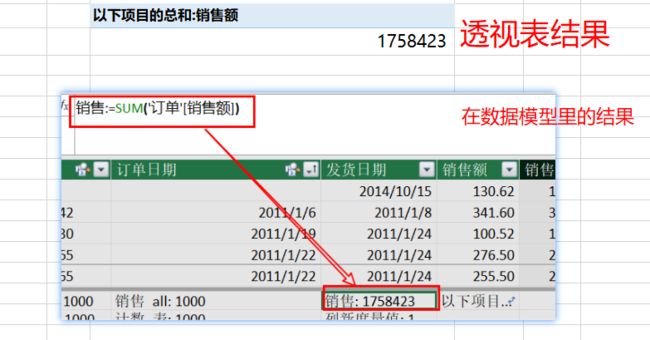
但是,这或者并不是我们的需求:总在这个所有列表集(数据模型)里计算。如果只有这种需求,那完全不必要深入学习DAX了,到这里你已经出师了。
实际的情况是,我们需要改变这个数据模型,从而改变计算结果。所以,我们需要一个重要的概念:DAX的筛选。虽然在前面已多次提到这个概念,在对于列表有了前面的介绍以及基于对列表的明确认识后,是时候在这里做个正式的简单介绍了,以帮助你了解DAX的其中一个最重要的概念:筛选(另一个是计算)。
第17式:CALCULATE的值列表与列表筛选
1、DAX的计算环境介绍
(1)很多时候,我们往往只需要在一个比较少的数据模型的列表内计算。也就是说,我们需要的(比如某个业务场景)是从原数据模型里,引用或定义出部分列表组成新的数据模型子集来计算就可以了,这就是DAX的列表筛选。通俗的说:我们需要的就是列表范围的改变,它涉及列表数量的改变或列表本身值范围的改变,我们称之为:列表筛选。
让我们从理解什么是“当前”列表筛选开始。任何DAX表达式都需要在一个筛选(也包括全集筛选)下进行计算,即总是筛选后再计算。很多人习惯于称筛选出DAX计算所在的列表集为计算公式的“环境”(正式点的称为:当前列表结构)。例如,考虑一个很简单的度量公式:
[Sales Amount] := SUMX( Sales, Sales[Quantity] * Sales[UnitPrice] )
你已经知道,这个公式在Sales表中计算Sales[Quantity]*Sales[UnitPrice]--数量值乘以价格值的总和。你可以将该度量拖入透视表中,并查看结果,如图所示。
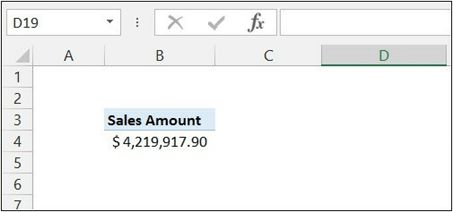
请记住:这是在没有任何筛选的情况下,[Sales Amount]度量显示了销售总额。
这个数字看起来几乎没有一丁点意义(或者偶尔会使用一次)。但是,你仔细想想,最关键的问题是:该公式它到底计算的是什么?而且我们也需要从这个问题入手来了解列表筛选。当然,其实它应该计算:销售额的总和,本来就如此,这很容易理解。
接下来,该计算结果总是一个最大的数值。我们说这个数字值实际上并没有多大用处(很少使用这个结果值)。正如那一个个躺在数据模型里的度量值结果:“不用时是根草,有用时才是宝”。
那么,什么样的结果值才是有用的呢?
其实,这可以用我们熟悉的透视表来回答这个问题。前面直接拖拽出度量的透视表结果是一个总数值。接下来,我们使用一些列表来分解这个总体,并开始处理这个分解的结果时,这个数据透视表就会变得有用了。
例如,可以使用产品颜色,将其拖放在透视表的行中,而透视表会突然显示一些有意义的业务洞察,如图所示。
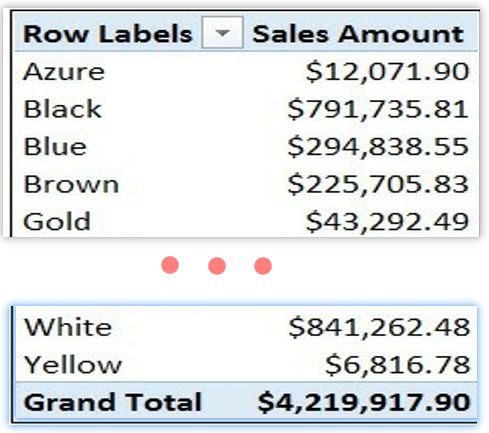
该销售额的总和,已按[颜色]列的颜色列值内容划分并计算出对应的值,这看起来已经有了一些意义:除了总数(最后一行的总计)还在,现在它显示了行值以及每个行值的总和(数据区列值),以及所有其他的值,而且每个值都有表示为:一个计算总值被瓜分为多个更小的有意义的值。
然而,如果你再仔细想想,应该注意到,奇怪的事发生了,这也是我们心中的疑问:[Sales Amount]的结果并不是按我们想象的方式来计算(本认为它们总是一个值)。
问题来了,我们自始至终从未指定过计算必须在数据模型的该子集(被颜色列分解)上工作。换句话说,并没有明确指定公式按这种方式来处理数据的子集。但是,为什么公式在不同的行(透视表行单元格)中却计算出了每个行对应不同的值?
答案很简单,事实上:因为DAX计算公式是在当前计算的背景(当前筛选环境)下工作。你可以把一个公式的当前列表筛选,看作是公式计算所在的单元区域(当前列表环境,你可以借助前面的CUBE多维函数来理解它)。由于products[color]--产品颜色被放置在透视表的行上,因而透视表中的每一行上将出现所有products[color]列的列值(不同的颜色名),相当于从这整个数据库中,筛选出该产品列的子集:即特定的color颜色行。这才是公式所在的列表环境区域(当前列表子集),度量计算就发生在这个列表子集里,而不再是原来的整个数据模型表!
也就是说,这是在公式计算之前,就已经应用于数据库的一组筛选器。当公式计算任何一个[Sales Amount]值时,它不是在整个数据库中计算,因为这时候,它并没有查询整个数据模型所有行的选项(行为)。
例如,当DAX公式计算到值为White--白色的行时,只有White--白色对应的产品是可见的。因此,计算只针对那些白色产品对应的列表值的销售。这时候,所有[Sales Amount],实际上成为计算白色产品的[Sales Amount],而不是整个数据模型里的[Sales Amount]了!当计算透视表中的其他某一行时,同样,也只针对那些颜色对应的产品的行。
任何DAX公式都定义了一个计算(如元度量计算)。但是,DAX在一个当前筛选中对这个计算进行了改变(一般是列表集的改变),从而定义了最终的计算值。所以,相同的DAX公式,但是值却是不同的,因为DAX针对的可能是不同的数据子集在计算。
你可以理解为,在所有DAX计算之前,存在一个筛选过程,只有等所有筛选发生后才会计算。这是DAX里一个最大的计算执行顺序:先筛选再计算。
(2)“ 空白 ”值的情况:
我们提到过一个情况,有时候计算式出现结果为空白的情况,这并不是公式错误,而是因为该计算是在当前的数据模型里计算(针对的是整个列表计算),可能当前的计算列表全集并不满足计算条件(公式定义需要的是某种子集列表条件)。当你将其拖入透视表,设置好适当的行、列筛选后,就会计算正确。
(3)Grand total--小计汇总值。
唯一的情况下,如果公式的行为方式已经被定义为Grand total—求全集最大的总数。在这个级别上,因为没有筛选,它将针对整个数据模型计算(比如没有任何筛选的透视表里的值,或数据模型里计算的值)。所以,在透视表的总计值,往往并不是透视表当前可见的行、列对应的值。
在这些示例中,为了简单起见,我们使用了透视表。显然,这与使用列表查询等方式来定义一个当前列表筛选是一样的,以后的内容中你将进一步了解它。现在议'"只考虑数据透视表,以便对概念有一个简化和直观的理解。
接下来,让我们再次在上图的透视表里把[年份]放置在该透视表的列上,以使透视表更丰富一些。如图。
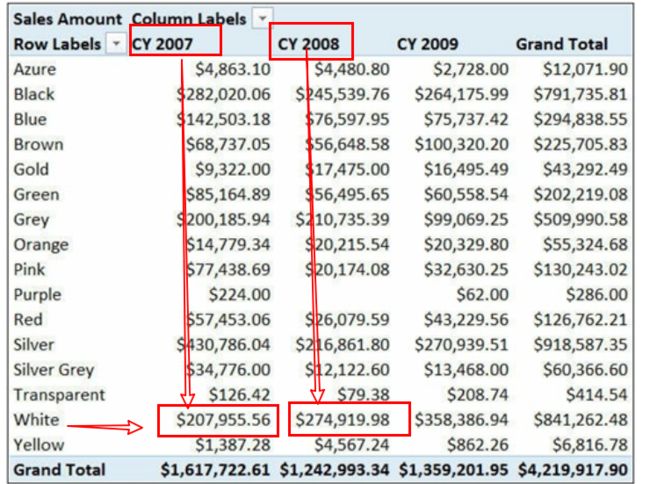
图中值单元的销售金额现在按颜色和年份两个列内容划分。
首先,通过前面说明的DAX规则,应该清楚了一点: 添加[年份]列后,即使任然还是同一个公式,但现在的每个单元格里的结果已经都是不同的值(与前一个图的值不一样了)。这是因为数据透视表被行和列这两个筛选条件所共同定义。当然这又是一个新的计算列表集了。
事实上,你很清楚的知道:2008年White--白色产品的销售与2007年的White--白色产品的销售是两个不同的值,同理,2007年的白色产品与2007年的Yellow--黄色产品的销售也是两个不同的值......,依次类推,行、列中只要不是同一个交叉坐标(指向同一个单元格),其值就会不同\\字段集和列上的字段集共同交叉定义出筛选子集。
下图结果说明了:筛选是由行和列上的字段集共同定义的。(注意:这里所指的行列筛选都是列表筛选,并不是DAX计算的行、列筛选)。
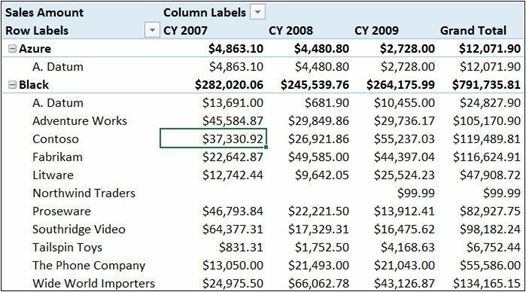
图中每个单元格都有不同的值,因为行上有两个字段,color 和 brand name--颜色和品牌名称。即行和列上的完整字段集定义了筛选结果。例如,上图中突出显示的单元格的行列筛选分别对应于color=Black、brand=Contoso以及Calendar=Year 2007。
请注意,无论字段是在行、列或在切片器、页面筛选器上,亦或者在任何其他类型的筛选器中,甚至是使用查询创建,这都不重要。因为,所有这些筛选器都只是为了有助于定义出一个的前筛选集,所有这些筛选共同的结果就是DAX公式用来计算的列表集。
将字段放置在行、列或筛选器上等,只是一种列表筛选的方式而矣, DAX计算值的方式并没有任何变化。
结合前面我们谈到的关于所谓外部筛选(直接列表筛选)和内部筛选(公式内部定义的筛选)。也就是说,外部列表筛选是不会影响内部公式的计算方式的,它影响的只是计算列表范围的改变(公式在不同的新的列表集里计算,其计算运行方式该是怎样还是怎样)。
现在,让我们看看全貌。在下图中,在一个切片器上添加了产品类别,在筛选器上添加了月份名称,并选择了12月份。
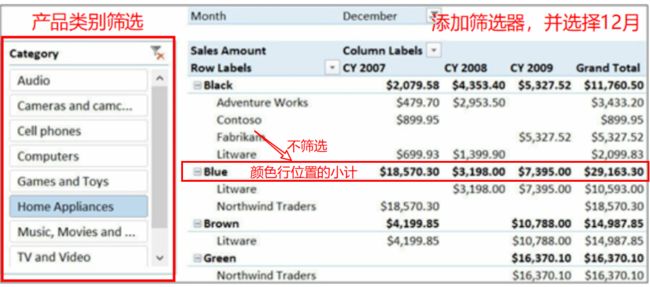
这是一个典型的透视表结果报告,筛选在多方面被引用,包括切片器和筛选器。
显然,在这一点上,计算在每个单元格中的值具有由行、列、切片器和筛选器共同定义的“当前列表筛选”。所有这些筛选器都有助于在公式计算之前,DAX将引用数据模型的列表,并定义出“当前列表筛选”。
此外,重要的是要了解,不是所有的单元格都具有相同的筛选器子集,不仅是在本身的值方面,而且在对应的各个字段方面也是如此。
例如,在上图中的列位置的[Grand total]度量只包含类别、月份和年份的筛选器,但是它并不包含颜色和品牌的筛选器。因为颜色和品牌的字段在行上,它们不筛选[Grand total]--总计数。这同样适用于小计,数据透视表中的颜色:这些单元格值没有来自制造商的筛选,唯一有效的筛选来自行位置的Color--颜色。
我们将此类筛选称为列表筛选。顾名思义,列表筛选将筛选表或列表。任何一个DAX公式,由于你的业务维度需求不同都会有不同的值,这取决于DAX用来进行计算的当前筛选列表。这种行为虽然很直观,但需要去很好的理解它。你可以借助你对于Excel透视表的了解,这并不难。
现在,你已经了解了什么是一个"当前列表筛选",知道以下DAX公式表达式应该解读为“当前筛选条件下对可见的销售金额的求和”:
[Sales Amount] :=SUMX( Sales,Sales[Quantity] *Sales[UnitPrice] )
稍后你将学习到如何读取、修改和清除列表筛选。到目前为止,已经足够了解这个事实:即当前列表筛选始终存在于数据透视表的任何单元格或报告、查询中的任何值里。无论在哪种情况下,你总是需要考虑当前列表筛选,以便理解DAX公式是如何计算的。
很多人用过Excel,可能没有注意过,你在Excel里任何一个sheet表里增、删行列数(操作行列单元格),其实sheet表里本身的行列总数是不变的(比如Execl2003的6万行的限制)。DAX数据模型也一样,无论你如何折腾列表,原有的数据列表模型总是不变的(具有完整性)。
这里。你可能会产生出一个疑问,既然数据模型列表是不变的,那么,参与计算的列表是什么?在哪里?要弄清这个问题,你需要继续查看后面的本系列知识点:列表关系,高级列表筛选,虚拟列表、元列表之间的区别及关系,物化以及DAX内部列表引擎的简单工作原理等。
所以,了解DAX的列表(列式)数据特点,是DAX的基础和核心。下面介绍列表的两种形态的运用方式方法。
2、值列表的行筛选以及行、列表筛选的共存。
这部分内容,我们在本系列的第一部分中已学习,不过未做专门介绍,这里再整理几点:
(1)计算列里的定义值列表计算。
我们谈到过DAX的行行为:DAX从第一行开始迭代:它创建了包含该行的行值筛选,并对表达式进行了计算,然后它移到第二行,再次对表达式求值,依此循环,直到计算完表中的所有行。如果有一百万行,你可以认为,DAX运行了100万个行筛选来使公式计算了100万次。显然这并不是实际发生的情况,否则,DAX将是一种非常缓慢的、不值得学习的计算语言。
但不管怎样,从DAX逻辑的角度来看,这就是它的工作原理。我们对于行筛选的最初认识也源于此。
接着,我们试着更准确一些来解释行筛选:行筛选是一个始终包含一行(引擎认为的一行,后面将解释为基数)的筛选,而DAX在创建过程中会自动定义它。比如计算列,你可以使用其他技术创建一个行筛选,这将在后面内容里讨论。
但是,解释行筛选的最简单方法是回到计算列,在这些列中,引擎总是自动创建行筛选。我们称这种不需要我们定义、引擎自动执行的行筛选为“隐式行筛选”。
(2)度量的引用列表计算。
假设你想要在一个度量中而不是在计算列中定义公式。比如其中一列为[SalesAmount]--销售额,另一列为[ProductCost]--产品成本,你可能会写出以下表达式:
[GrossMargin]:=Sales[SalesAmount] -Sales[ProductCost]
在该公式中,我们引用了两个列表,其中Sales[SalesAmount],这是一个列名,引用的是Sales表中SalesAmount列的全部列值。这个定义缺少什么呢? 你应该还记得,从以前的公式参数中,这里缺少的信息是:从哪里获取当前SalesAmount和[ProductCost]列的行值?当在计算列中编写此代码时,由于存在隐式行筛选,DAX知道在计算表达式时要使用的行(行的行为)。但是,这时的度量结果是什么呢? 没有迭代、没有当前行,也就是说,没有行筛选。
因此,它在语法上是错误的,你甚至不能写出该公式。当试图计算它时,你将会收到错误提示。因此,请记住,一个列本身并不具有每个行值(数据列表不具有行的概念)。但是,对于表的每一行(横向对应的多个行称为表的一行)都是一个不同的值(数据模型不允许存在相同的行)。因此,如果想要获得单个列值,则需要定义要使用的行(横向对应的一行或多个行)。这将是后续的关系主键(唯一值列表)的内容。
从目前我们学习到的知识,指定要使用的行的唯一方法就是行筛选(值列表筛选)。因为在这个度量中没有行筛选,因而公式是错误的,DAX拒绝计算。这是我们已讨论过的内容。
(3)行、列筛选关系共存
行筛选和列表筛选是是DAX唯一的计算环境。因此,它们也是修改公式结果的唯一方法。任何DAX公式将包含并执行这两个不同的筛选:行筛选和列筛选。我们将这两个筛选合称为“计算筛选”。因为它们是改变公式的计算方式的筛选,并为相同的公式提供不同的结果(这也是解释相同的公式能提供各种不同结果的原因)。
用一句话来总结:任何DAX计算都同时包含行、列表筛选。即行、列筛选关系共存。
认识这一点是非常重要的。事实上,你总是很难同时思考两个筛选,但公式的结果总是取决于这两种筛选。因此,很多时候,你可能认为某个DAX非常正确,并相信它是对的。但是,通过DAX知识的不断加深,你会发现,如果你不记得两个筛选的共存关系,书写DAX将是一大挑战。因为,其中任一种筛选都可能改变公式的结果,这意味着,任何一个筛选的错误,也将导致整个公式错误。
在计算列中定义:SUM (Sales[SalesAmount]) 公式。我们知道,它针对完整的数据模型表计算,并返回每个行的同一个值的结果。
这个例子用行、列表筛选共存的关系来解释:它们共同作用于公式的结果,但使用了不同的方式。计算列中使用SUM、MIN和MAX等聚合函数时,只使用列表筛选(显式的引用元列表),而忽略行筛选。也就是说,DAX只使用该列表筛选(这时只有列表筛选)来确定列值(行筛选似乎总等于列表筛选,而被忽略)。
进一步,由SUM函数定义的:SUM (Sales[SalesAmount]),当然还是一个值列表,即同时也存在值列表的行筛选行为,不过该行行为每次执行筛选时,都针对的是整列的列值(也就是只有列表,而忽略了列值,或者说列值每次都没有变化,即使是每次都存在行筛选),因而每一次的结果并不是每一行的不同值。关键在于,这两种筛选在一起工作,并以各自不同的方式改变公式的结果。你不能使用直觉逻辑来判断它。
现在,让我们更详细说明:当前DAX公式计算时发生了什么?
你已经学会了这个公式的意义是什么:“当前筛选条件下的销售金额总和”。因为这是在一个计算列中,DAX函数公式逐行计算,因此,它遵循计算规则:为第一行创建一个行筛选,然后调用公式计算,一直到遍历整个表的所有行……。
它还符合:公式计算了“当前筛选”中所有销售额的总和。所以,真正的问题是:“当前的筛选是什么? 答:当前完整的数据模型表。因为该DAX计算公式之外没有任何数据透视表或任何其他类型的筛选。实际上,当没有活动筛选存在时,DAX将“当前完整的数据模型表”作为定义的计算列表(整个列表)计算。
即使有行筛选,SUM也会忽略它(因为总是相同的行筛选),因而,影响它计算的关键只有列表筛选,而当前筛选现在是完整的数据模型表。因此,会得到一个相同的销售总额(所有行的总值)。
(4)行筛选的定义方式
这一部分内容,在前面的本系列第一部分中已简单说明。我们知道,修正第(3)项中的这个计算公式的正确方法有:
第一种方法:使用聚合计算函数定义。
在该情况以及类似的某些情况下使用任何聚合计算函数,上述公式改为:
[GrossMargin] :=SUM( Sales[SalesAmount] ) - SUM(Sales[ProductCost] )
我们使用了SUM函数来定义了新的行筛选,在引用列表筛选上,同时定义了行筛选,公式得以修正。
当然,使用函数定义一个唯一值结果的值列表的情况:
(1)之前提到的VALUES函数(值结果方式)
(2) MAX、MIN函数(因为MAX、MIN的最大、最小值结果其实就是唯一值的自身值)等。后续会深化这类函数的学习。
因为DAX计算主要是创建度量值,一个最简单的度量是:一个函数引用一个列表,例如:SUM(表[列]),都包含引用的显式列表以及定义的隐式行筛选,因而能正确计算。
第二种方法:使用迭代器函数定义行筛选
前面,我们了解到:在定义计算列时,DAX会自动创建行筛选(具备隐式行筛选)。在这种情况下,引擎将逐行计算DAX表达式。另外,使用迭代器也能在DAX表达式中创建行筛选。
前面已提到:所有的X-后缀类函数、FILTER等都是迭代器。也就是说,它们是定义遍历表并计算每一行的表达式,最后使用不同的算法聚合结果。你可以理解为:行行为是这类迭代函数本身添加在内部的函数功能。例如,看看下面的DAX表达式:
[IncreasedSales]:=SUMX( Sales,Sales[SalesAmount] *1.1)
SUMX是一个迭代器(定义值列表的函数),它遍历Sales表的每一行,并计算那些销售额增加了10%(*1.1)的销售额,最终返回所有这些值的和。为了计算每一行的表达式,SUMX在Sales表上创建了行筛选,并在迭代期间使用它。在包含当前迭代行的行筛选中,DAX将计算内部表达式(SUMX的第二个参数)。
需要注意的是,在整个计算流程中,SUMX的不同参数使用不同的筛选。让我们深入分析一下相同的表达式:
=SUMX(Sales, ←外部环境
Sales[SalesAmount]*1.1) ←外部筛选+新的行筛选。
第一个参数Sales是引用来自数据模型的列表筛选(例如,它可能是一个透视表单元,另一个度量,或查询结果列表的一部分等,你可以分别写出该参数下的公式),而第二个参数(表达式)是使用外部筛选加上新创建的行筛选来计算的。
重要的是要记住,原始的筛选表达式仍然有效:迭代器只是添加一个新的行筛选:它们不以任何方式修改现有的筛选。
我们换用一种稍微易于理解的方式来理解:
该公式中的Sales[SalesAmount] *1.1是一个值列表(这是通过*1.1来定义的,使用值的运算符,无论列表是何种类型,引擎都将以公式定义的类型来处理它,因为只有值列表才能使用值运算符,例如+、-、* 、/ 等 )。
因此,SUMX( Sales,Sales[SalesAmount] *1.1)中,SUMS的第一参数是一个表,第二个参数是一个值列表(值列表或元度量),你可以理解为,用一个值列表去筛选一全集列表,然后计算。
如果公式不需要改变原有值列表的值,即去除*1.1,该公式本来的面目为:
[Incre asedSales]:=SUMX( Sales,Sales[SalesAmount] ) (解释见下面案例的类似公式)
我们使用SUMS以及类似函数的行为来进一步解释行筛选(即所谓迭代)行为:
SUMX()将循环遍历一个列表(这里是Sales表),它在每一步执行一个计算,然后将每个步骤的结果聚合加起来。这是最初的、简单的解释,但它在透视表行、列上产生了一些关键的结果,这却是非常直观的。
SUMX的官方描述:“返回一个表中每一行的表达式的总和”。这其实暗示了其内部计算原理。奇怪的是,展示并理解这种行为的最好方法是,需要从一些没用的反面的例子开始,然后建立起正确的理解。对于所有的例子,我们使用下面的简单表,Table1:
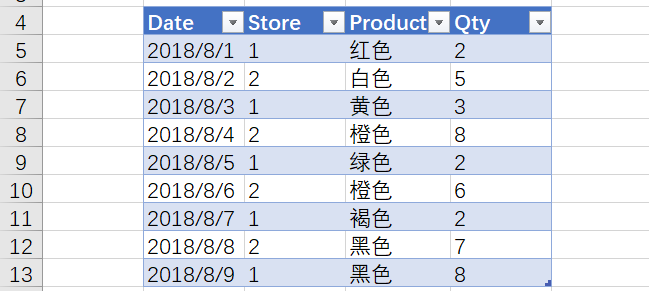
我们定义如下5个公式:
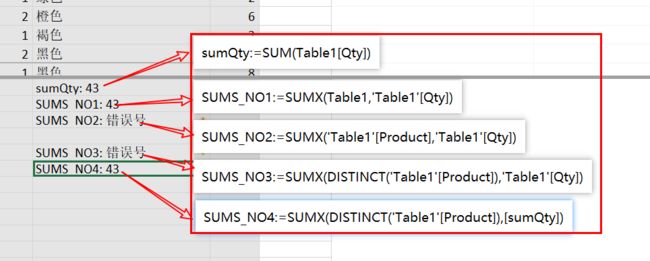
不适用的例1,引用整个表(在整个表里)(跟前面的公式类似)
SUMX(Table1, Table1[Qty])。
返回:43,这是Qty列的总数。你不妨使用SUM(Qty)。
原因:它遍历Table1表(如在透视表中,则为当前透视表的筛选结果集)的每一行,并在每个步骤中添加Qty值,就像前面描述说的那样。
无用的例子2,使用一个列表:
SUMX(Table1[Product], Table1[Qty])
返回:一个错误
原因:Table1[Product]不是一个多列的表,而是一个列。而SUMX要求一个表作为第一个参数。
无用的例子3:通过对一个列的不同值--DISTINCT()求和。
我们使用DISTINCT()引用Product--产品列,因为它返回一个单列的表。 SUMX(DISTINCT(Table1[Product]), Table1[Qty])
返回:一个错误
原因:DISTINCT([Product])中的结果是一个单列的值列表,仅仅是 [Product]列的值列表。从筛选的角度也许更利于理解:这里,你不能使用一个全集的列表(Table1[Qty])去筛选该全集列表的值列表(部分列值的列表):(DISTINCT(Table1[Product])。当然如果希望保留第一个参数的定义,可行的方式是,将第二参数也改为值列表,例如,已定义好的度量(值列表)。也就是说,第二个参数可以是一个度量值列表。
更妙的是,不仅能保留你使用的是DISTINCT(),而且这个方法也可以访问其他的列。首先,我们先来定义[SumQty]度量:
[SumQty] = SUM(Table1[Qty])
然后再用这个方法重新尝试之前的例子,替代第二参数中的列表:
SUMX(DISTINCT(Table1[Product]), [SumQty])
返回:43,是的,返回正确的总数。
但这一次,“为什么”需要特别关注。请记住,对于第一个参数[Product]列的每个值,SUMX计算其在第二个参数中的表达式,然后将其添加到它的运行总数中。
第一步:由DISTINCT定义的DISTINCT([Table1[Product])值列表(注意与VALUES函数的区别),被SUMX引用为列表(引用其全部列值),即[Product]--产品列中全部唯一值的单列表:
第二步:SUMX将筛选Table1表(不仅仅是[Product]列!)的单列列表中的第一个值,[Product] = 红色。然后,计算出该表里的对应[SumQty]的和,返回2。
第三步::橙色和褐色的过程重复前两步第一步的过程,返回8+6和2:
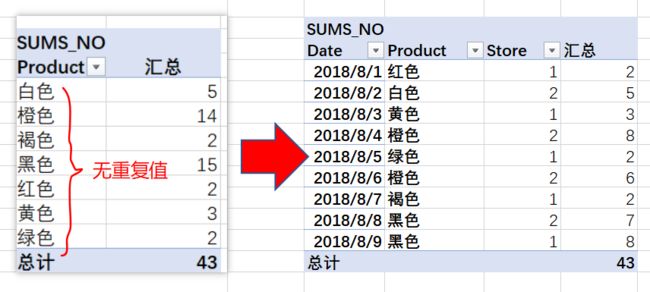
最后一步:SUMX随后添加了它获得的全部7种颜色的结果的聚合,结果是43。
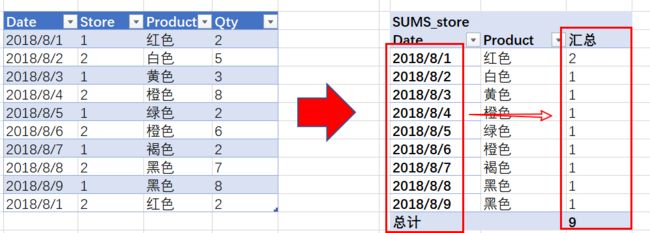
很多时候需要得到一个相同的结果,即[SumQty]度量的总和可以独立完成。既然,现在你知道它是如何运作的,我们来做点别的。这是一个有用的例子!让我们定义另一个度量,比如求唯一的每个[Store]--商店的计数:
[Count_Store] = COUNTROWS ( DISTINCT(Table1[Store]))
于整个Table1,结果返回2,因为只存在2个唯一值。

然后,我们使用该度量作为SUMS的第二个参数的度量:[SUMS_store]=
SUMX(DISTINCT(Table1[Product]), [Count_Store])
与前面的示例相同,从DISTINCT获取一列结果; 筛选出白色,如图所示:
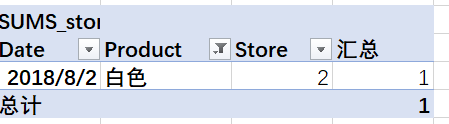
[SUMS_store]度量标准计算出2家不同的商店售出了红色。
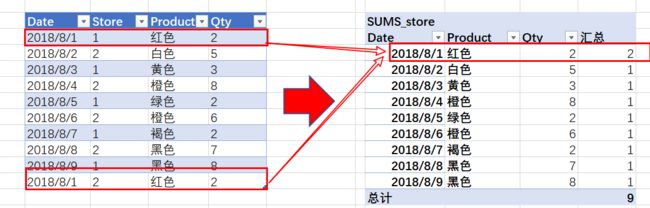
然后,单独的[SUMS_store]结果:
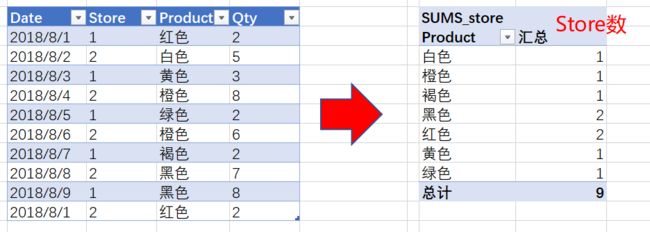
图示知道:只有一家的Store卖白色、2家的Store卖红色与黑色......。
最后:把前面几步的结论加起来:1+1+1+2 + 2 + 1 +1= 9。SUMX返回9,这基本上意味着它们销售的Store--商店和Product---产品有9种不同的组合。理解会很有用,但它属于读者应该自己实验的部分。这里略过。需要提示的是:
(1)SUMX对当前透视的响应与其他任何内容一样。因此,如果你只划分到某一特定时期,结果将只反映该时期对应的Store--商店。即 [Count_Store]筛选结果将关联到其他计算所在的其他列表。
(2)类似函数:AVERAGEX、MINX、MAXX,和 COUNTAX都以相同的方式工作。因此,像SUMX一样迭代,只是步骤中应用不同的聚合方式。
(3)SUMX中引用的字段不必显示在透视视图中。本例中,SUMX与[Store] 和 [Product]列关联。但如果关心的可能是被[Region]列筛选成几行,然后被[Date]列划分成几行,而这一度量仍然有效。
(4)你可能会将SUMS函数与SUM比较,这在后续的内容中会提到。这里先给出一个最好的建议:避免在 SUMX 函数中写复杂的条件语句, 如 "IF 语句"。请考虑以下2公式:
商品总销售额超过100的计算:
=SUMX(Sales,
IF(Sales[销售金额] >100, Sales[销售金额]))
优化建议版:
=CALCULATE(
SUMX(Sales,Sales[销售金额]),
Sales[销售金额]>100)
前面定义行筛选的几个规则通常都是有效的,但有一个特别重要的例外:
如果某个行筛选的前面已经包含一个相同的表的行筛选,则新创建的行筛选将隐式掉先前存在的行筛选。我们简单讨论一下这个问题。即:
第三种方法:使用EARLIER函数定义“当前”行筛选。
在同一个表上有许多嵌套列表筛选的情况很常见,但类似的嵌套行筛选的场景可能看起来很少见。但实际上,这种情况经常发生。在DAX中,定义“当前”行筛选是一个很重要的概念,让我们以一个例子来讨论这个概念。
假设你希望计算每一种产品的价格,以及相对于任何其他产品的价格。这将产生一种基于价格的产品排名。
为了解决这个问题,我们使用了前面学过的FILTER函数。可能还记得:FILTER是一个迭代器,它循环遍历表的所有行,并返回一个包含满足第二个参数定义的条件的新表。
例如,如果需要检索表的产品价格高于100美元,可以使用:
= FILTER(产品表,产品表[价格]>100)
细心的读者会注意到,因为FILTER是一个迭代器(具有行行为),因为表达式产品表[价格]>100可以被计算,如果有且仅当一个有效的行筛选存在于产品表中。否则,单位价格的有效值将是不确定的。FILTER是一个迭代器函数,它在第一个参数中为表的每一行创建一个行筛选,这使得在第二个参数中的计算条件成为可能。现在,让我们回到我们最初的例子,创建计算列:
产品表[价格分级]=COUNTROWS(FILTER(产品表,产品表[价格]>当前产品价格))
计算出比当前价格高的产品的数量。我们暂时使用名称“当前产品价格”作为当前产品的价格,然后很容易看到该DAX公式将采取一切必要的行动:
(1)FILTER只返回价格高于当前值的产品;
(2)COUNTROWS计算这些产品;
(3)真的如前面两步那样则没有问题。唯一剩下的问题是,用有效的DAX语法来表示、替换这个“当前产品价格”。使执行运用“current--当前行的值”,也就是说,当DAX计算这一列时引用列中当前行的值。这其实并不简单。
因为在产品表中定义这个新的计算列。因此,DAX在一个行筛选中计算该表达式。但是,表达式使用了一个FILTER,它在同一个表(产品表)上将创建一个新的行筛选。实际上,前一个表达式中使用的:产品表[价格]是筛选器,其内部将迭代当前行的单价。
因此,这个新的行筛选隐式了计算列引入的原始行筛选。你看到问题了吗?即我们希望访问的是当前的单元价格,但不希望使用最后引入的行(筛选产品表[价格])。相反,希望使用前面已有的计算列中的行筛选。
对于CALCULATE(计算列表,筛选1,+筛选2+...+筛选N)里的and”并“关系的列表筛选,理解起来很容易:这是一组列表筛选器,最后的筛选结果才是”当前“列表(表示的是列表的范围)。要表示”当前“行,这只能与列表的值列表有关,无论定义的”当前“行是什么,它总是一个值列表(表示为某个列表的列值范围)。上面的公式我们将其加个解释图:

要理解这个图,我们单独把这个定义方式拿出来,然后提醒你需要记住的几点:
(1)它针对的是同一个列表里的行筛选,右边始终是一个引用的元列表(提供全部列值)
(2)左边是该列的一个值列表。因此,左部分无论如何定义,它要不是该列表的一个或多个值,要不就是该列表的某个列值范围。因此,它需要中间有一个操作符(本例中为“>”)来定义它。
与多个列表筛选表示方式不同,但它是表示“当前”行筛选(当前值列表)的方式。我们说,一个列表上不能同时有多个筛选(行筛选或列表筛选),“当前”行筛选相当于在同一个列表上有两个行筛选(一个隐式的行筛选,一个定义的行筛选),但又很需要这种表示方式,我们当然不能每次都使用“当前”的某某行(这里是暂时借用的名称:“当前产品价格”)来指代这种"当前行"的行为。
DAX提供了一个函数来表示这种"当前行"的行为:即EARLIER函数。EARLIER的功能是定义:当前行,以表示当前行筛选而不是最后一行来检索列值。因此,我们终于找到可以替换“当前产品价格”的表示方法:EARLIER(产品表[价格])。公式为:
产品表[价格分级]=
COUNTROWS(
FILTER(产品表,产品表[价格] > EARLIER(产品表[价格])+1)) //为了排名,我们加了+1 只要将该度量拖拽到透视表中,可以看到产品表中定义的计算列,该列将按降序对单价进行了排序。这其实是EARLIER嵌套的行筛选行为。
我们建议仔细研究和理解这个小示例,因为它是一个非常好的测试,可以检查使用和理解行筛选的能力,以及如何使用迭代器(在本例中是FILTER)创建它们,以及如何通过使用EARLIER方法访问外部的值。
EARLIER是DAX里最奇怪的函数之一。许多用户在使用EARLIER时候总感到疑惑,这也许是因为没有考虑到行筛选行为,而且也没有考虑到通过在同一个表上创建多个迭代来嵌套行筛选的事实。实际上,EARLIER是一个非常简单的函数,它将会在很多场景下有用。
EARLIER接受第二个参数,即跳过的步骤数(默认数为1,即前一次行行为,你可以设置跳过两个或多个行筛选)。此外,还有一个名为EARLIEST的函数,它允许直接访问为表定义的最外层的行筛选。
坦白说,EARLIER 或EARLIEST的第二个参数都不会经常使用到:虽然有两个嵌套的行筛选的场景很常见,但是有三个或更多的场景是很少发生的事情。
值得注意的是,如果想要将上述计算的值转换为一个更好的排序(也就是说,从1开始并依次增加1的值,即创建一个序列1、2、3……),我们将计算产品表改为计算[价格]列就行了。你可以通过在前面章节中的函数学习,来帮助我们写出公式:
产品表[价格分级] = COUNTROWS(
FILTER(VALUES( 产品[价格] ),
产品表[价格] >EARLIER(产品表[价格] ))) +1
我们建议你学习和理解EARLIER,因为将经常使用它。然而,重要的是要注意到在许多场景中可以使用变量来代替—以避免使用EARLIER。因为在当前行的单独形态的右边部分,其实是一个值列表(“常量”),因此可以使用变量来定义它。此外,谨慎使用变量会使代码更容易阅读。这取决于你的选择。例如,可以使用这个表达式来计算之前的计算列:
产品表[价格分级] =VAR CurrentPrice = 产品表[价格]
RETURN
COUNTROWS(FILTER(VALUES( 产品表[价格]),产品表[价格] > CurrentPrice)) +1
在这个最后的例子中,使用一个变量将当前的产品表[价格]存储为CurrentPrice变量,稍后将使用它来执行比较。可以为变量提供一个名称以使代码更容易阅读,这样不必每次读写表达式时需要理解遍历行筛选传递的计算。你可以查阅《变量系列文章》。
第18式:CALCULATE的函数法引用列表与定义值列表
前面已提到:DAX是一种函数式语言,而DAX由列表元素构成。
一般来说,函数语言基本上可看作是由某种调用数据的方式组成,DAX操纵的是列表,因此,DAX计算就是函数对于列表的调用。通过函数来操纵列表(列表或值列表)是DAX内部计算的重要方式,这些函数在DAX的内部计算中也相当重要。
结论是:DAX(CALCUATE)的一切都是一个个列表之间的调用组合计算,再调用、再组合、再计算,不断组合不断计算......。你甚至可以理解为:在Excel和DAX中都不存在循环、迭代和跳转等等的概念,DAX就是用函数引用列表、定义值列表以产生不同的列表集,然后依据这个产生的列表集计算出结果。你需要重点学习如何使用播放器播放音乐,而不是研究播放器里面的构造......。
在接下来的内容中,你将了解到在DAX中值列表(标量)函数和列表函数之间的"引用‘’与"定义"的区别以及运用。
1、列表函数与值列表函数
为了方便,我们基于列表的两种形态,将操纵列表的函数也分为两类(这在“列表理解的线索”中已提到):
(1) 列表(表)函数;
(2) 值列表(包含标量值)函数。
Excel中大多数函数在DAX中仍然有效,但DAX另外还有本身的一些专有函数。关于函数我们需要了解:
(1) 函数是内部己封装好的某个功能模块,你需要某个功能时要能知道该使用哪个函数,反之亦然。例如,LASTDATE函数,语法为:LASTDATE(时期表[时期列])),功能是“返回最后一个非空时期”,这可以用来求:某个当前时期的最后一天。例如你希望求"每个客户当前最近一次购物的时期",则可以使用LASTDATE这个函数(再关连到客户维度)。
关于DAX函数,在《DAX函数专题系列》中将会详细说明。
(2) 函数的格式与任何其它函数(如ExceI中函数)一样,表示为:函数名( 参数1+参数2…参数N)。其中( )里的参数是向函数里直接或间接调用外部数据。针对DAX,所有函数的参数都是列表(即列表或值列表两种列表形态之一)。
如:LASTDATE(日期表[时期])--求日期表的[日期]列中最后的时期。该函数的参数引用一个列表,然后该列表被传递给LASTDATE函数。或者说,LASTDATE函数“引用日期表的[日期]列”并基于其函数功能计算,其计算后的值列表结果又可以作为列表或值列表(如果是该值列表的全部列值--则是作为列表被引用,如果是该值列表的部分列值--则是作为值列表被定义)。
再如:上部分中我们提及的公式模型:COUNTROWS(VALUES(Sales [列1]) )::VALUES的功能是引用(提取):Sales表的[列1]列中的所有唯一值。VALUES()只有一个参数--通常为一个列表,该参数引用外部Sales表中名称为[列1]列的全部列值数据提供给VALUES,基于VALUES函数功能,由它定义得到该[列1]列表中所有唯一值的行(不重复的列值)的结果值列表(这时,列值发生变化--范围已缩小)。
所以,对于VALUES函数而言,[列1]是被引用的列表(引用的是该列的全部列值)。而对于COUNTROWS函数而言,引用的则是VALUES()的结果(值列表),而不再是直接的[列1]列。因为该结果值列表的列值全部被提供给COUNTROWS函数,再基于此函数功能计算。因此,这时候该结果值列表对于COUNTROWS函数而言则是被引用的"列表",而不再是值列表……。
当然,对于整个结果,它是一个值列表,例如你可以直接定义它为一个值列表计算:COUNTROWS(VALUES(Sales [列1]) ) =1,3 * COUNTROWS(VALUES(Sales [列1]) ) 等。
我们理解为:VALUES(Sales[列1])的结果是Sales[列1]这个元列表的值列表(即[列1]列全集里的子集列表),但同时又是COUNTROWS()的列表(这时被引用的是“值列表全集”)。
很显然,你可以简单理解为:只要使用了某个列表的全部列值,我们称之为:引用的是列表。而且,整个COUNTROWS(VALUES())的结果值列表,所以,还可以继续作为列表参数被引用或值列表参数被定义,这其实就是DAX公式中经常遇到的函数嵌套的情况。在一些较为复杂的DAX中,理解这种列表与值列表之间的微妙区别显得特别重要。
一般情况下,函数嵌套无论多少,其最内层函数引用的总是元列表,每嵌套一次,总以列表引用计算(在行、列筛选之后),并以值列表作为结果。
我们不厌其烦地讲这个案例,虽然有些"绕口令"似的,但对于加深你了解列表与值列表的"引用"与"定义"的区别,理解列表的这两种形态:并不是固定不变的,以及不同的函数以及在不同的参数位置,其形态会发生变化。例如弄清这些,对于学习DAX非常重要。
(3) 熟悉一些常用的函数包含的内容:函数功能、参数以及返回结果。我们通常以这些关键内容作为函数分类的依据。
我们先来学习如何使用表函数(这里主要指产生结果为一个或多个列表的函数,注意这与操纵一个或多个列表存在明显区别:操纵列表--比如引用列表或定义值列表,这是操纵列表的方式或过程,而表函数是指能产生列表结果的函数功能,这是指列表结果。而且,这通常有一个专门的称呼:DAX列表查询。当你编写一个DAX查询(产生列表结果。后面会接着讨论),而不是定义一个度量或计算列的DAX表达式时,表函数是很有用的。
这里只介绍表函数的概念,但不提供涉及这些函数的详细解释。后续会陆续介绍,并对表函数作深入分析。在这里,我们只解释表函数在DAX中的作用,以及如何在常见的场景中的运用,包括在定义值列表(标量)DAX表达式中使用它们。
2、列表结果(返回结果为列表)
由于数据模型里的数据是一个个单列表,因此你不能直接将列式数据直接导出为以单元格区域存储的ExceI表。以后你不要再提问:"我如何将Power Bl数据模型里的数据导出为Excel"此类的问题。这需要特殊处理:
(1 ) 将结果值列表格式化(比如输出为PDF、CSV等)。
例如,在Power BI中的图表结果中:导出数据-->选择文件名及保存类型,将结果保存为CSV文件。
导出为PDF格式:
使用Excel打开该文件,然后进行后续操作:
(2) 转换为值列表结果输出:比如最常见的透视表,使用Power BI的复制(一列或一个表)等。
然后粘贴到Excel表里:
(3) 使用链接表方式或专门的软件,例如使用DAX Studio(请自行了解该部分内容)来输出列表结果。图示略过。
3、EVALUATE 的列表结果
使用DAX Studio来输出列表结果时,往往需要用到EVALUATE函数,该函数功能专门用于列表输出。 EVALUATE语法:可以将DAX作为一种编程语言或一种查询语言(兼有两种功能)。
其实,你可以将通常所说的DAX查询看成是一个返回表的DAX表达式,反之亦然。也就是说,DAX查询是获取列表结果的一种方式。这与"引用"列表是有区别的。DAX查询是获取列表结果,而"引用"列表,必须先存在列表后才能被"引用"。
因为今后经常会用到EVALUATE语句以及它的综合查询语法,这里不再详细介绍。
值得强调的是:EVALUATE可以用于定义查询本地的度量(也就是说,它们存在于查询的生存期)。当在调试公式时,它变得非常有用,因为这可以定义一个本地度量,然后测试它,一旦它按照预期的结果运行,就可以将它放入模型中。后续系列学习中,你将看到更多这种语法的例子。
大多数语法是由可选参数组成的。例如最简单的查询:检索一个现有表的所有行和列:
EVALUATE Product
该查询结果为Product(产品)表的全集结果。 有时为了控制排序顺序,可以使用order BY子句:
EVALUATE Product
ORDER BY Product[Color],
Product[Brand] ASC,
Product[Class] DESC
请注意,己在模型中定义的列属性不会影响DAX查询。即使可以通过按列属性查询(或筛选)单个列来查看排序数据,也不必依赖这种行为,就像不能依赖SQL查询中的聚集索引一样。生成动态DAX查询的客户端应该在模型的元数据中按列属性读取排序,然后按条件生成相应的顺序。
在DAX和SQL中,必须始终使用一个显式的ORDER BY 条件来获得排序数据。ASC和DESC关键字是可选的:如果它们不存在,则默认使用ASC。该查询的结果,将根据Color、Brand和 Class列对数据进行排序。
关于列表结果的查询,我们后续有一个列表查询的专题介绍。这里从略。
之外,要筛选某些行(列值)并更改DAX查询返回的列表,必须使用EVALUATE函数来操作计算关键字之后的表表达式。本部分介绍了一些表表达式,而后一个部门将介绍其他表表达式。
4、函数法操纵列表
我们说,DAX 是一种函数语言,这意味着一个完整的计算公式将包含在函数里(例如最常用、最熟悉的CALCULATE()),即DAX计算式总是由一个或多个函数以不同方式来构成。例如:函数的嵌套、函数定义的值列条件语句等…。实际上,在DAX中,你使用函数只有两种情况:引用列表或定义值列表。
值得记住的是:DAX中的引擎执行,一般是从最内部的函数或参数所定义的列表或值列表开始,逐步由内向外计算。
例如前面的COUNTROWS(VALUES())公式,内部引擎将首先计算内层的VALUES( ),再计算外层的COUNTROWS( )。 我们说,DAX的计算列表并不总是原始列表(即元列表包含了该表的最大列值,即整个列表集)的计算,而是变化了的、其结果为一个或多个列值范围的新计算列表子集。
我们可以先不管其变化过程以及到底经历了多少次变化。总之,能确定的是:这其中的任何变化,其结果都将是小于或等于原列表列值(严格来说,应是"列基数")的值列表。问题是,在这些值列表中,引擎的最优化执行步骤总是:趋向于先找到最小"基数"范围的列表(引擎的特点:“以快速计算为先”)。
所以,在CALCULATE(计算式,筛选1+ 筛选2+…筛选N )的多个AND(并条件)筛选中,还是存在先后顺序的,一般将能筛选出"基数"最小(值列表范围最小)的筛选放在前面,这样引擎首先获得一个较小的数据列表集,从而可能会以较小的内存及运行消费来获得较快的速度,这是基于引擎快速运行的特点,因此,也是一种DAX优化(未来可能会自主识别)。
你也可以理解为,DAX引擎执行一般总是从最内部的函数定义的值列表开始。也就是说,当所有筛选完成后(某个列表上的所有筛选器都完成后。因为筛选到最后,值列表最小)才计算。所以,简单理解为:列表或值列表筛选将导致计算列表范围由大变小(被形象地称之为漏斗式筛选),而计算的执行总与之相反。
例如,我们再次使用值列表的概念来解释变量的定义。例如,你可以使用以下语法在 DAX 表达式的任意位置定义一个变量:
VAR NAME = RETURNED VALUE
VAR变量可以是任何数据类型,也包括整个表。请记住,每次在 DAX 表达式中引用变量时, 必须根据定义重新计算它的值。这相当于定义了一个固定的值列表来参于计算,这就是我们所说: 变量更像是一个常量(标量)。因此,你在函数中应避免使用重复变量(详见变量系列)。
第19式:CALCULATE的引用列表筛选
既然列表筛选可简单理解为导致计算列表范围的缩小,这可以从以下几种筛选方式中了解它:如有必要,你可以实验几次,以加深对于列表筛选的理解。
(1) 透视表的列表筛选;你应该非常熟悉了;
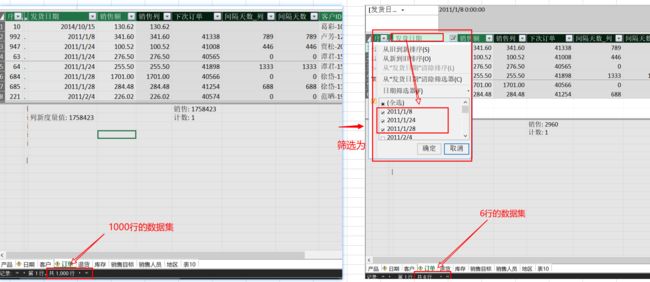
(2) 内部数据模型的全集被筛选为子集;例如一个有1000行数据的列表集合,通过其中的一个[发货时期]列的筛选(只筛选了三天的时期),该数据集则变为只有6行的数据(仅包含那些符合筛选条件的时期对应的行集,本例中筛选时期为三天):
(3) CALCULATE内部定义的值列表筛选。比如你已经熟悉的CALCULATE()里的筛选。附图略。
你会发现:上述三种方式产生的筛选效果是一样的。有的称第一、第二种方式为外部筛选,第三种CALCULATE()为内部筛选,并且外部筛选总在内部筛选之前。这很好理解,因为所谓的外部筛选直接针对的是数据模型的筛选。而所谓内部筛选是通过公式内部定义的筛选(你可以理解为:先有列表再有值列表)。第二种方式几乎只是作为一种改变数据模型范围、以直观检测或观察列表筛选结果的手段。
其实,无论是透视表筛选还是直接针对内部数据模型里的某个表的筛选,都将导致列表的范围改变(由原有的全集列表变为某个子集列表),每筛选一次,计算列表集范围会相应改变(缩小)一次,其结果则是当前数据列表集,所有已设置好的度量或计算列都将在该当前数据列表下计算。
而且,无论是哪种筛选,一般都是单线程、单列表进行,即每次筛选只针对某一个列表,或者说,一个列表上不能同时进行多个筛选(体现在透视表或直接数据摸型表的筛选上,你只能一次一次地点击、进行一个筛选后再进行另一个筛选)。实际演示几次就会明白,或者你已进行了无数次类似筛选却没有注意而矣。
我们重点了解和学习的是第三种方式,因为这才是有用的、用于输出有效结果的方式。
这时,我们终于将要了解除元度量外,稍为复杂一点的最简单、最基本、却最有可能出错的DAX的第二种常用的计算式形态,CALCULATE( )函数定义的筛选计算:
CALCULATE(计算式或函数定义的值列表, 筛选1, 筛选2…, 筛选N)。
因为CALCULATE也是函数,我们前面针对该函数的功能已做了部分说明,比如其最基本的功能是定义出一个计算列表子集。上述计算式形态中的筛选1、筛选2…筛选N相当于该函数的第二参数(参数间是"and"、并的关系),该参数无论是列表或值列表,都必须满足:
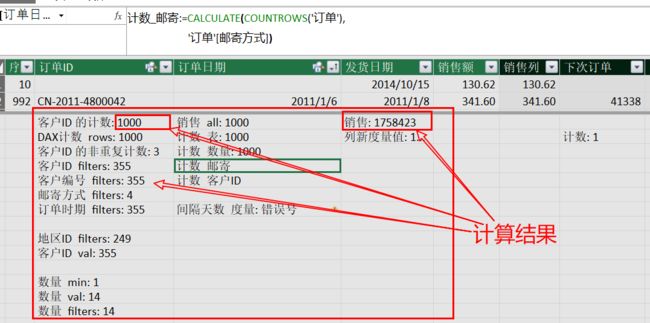
(1) 它们中的任何一个筛选(筛选1、筛选2、…筛选N),其基数总是小于第一参数的基数,否则筛选不起作用。也就是说,它们都针对同一个数据集合筛选,彼此之间并不相互筛选。 如图,我们列出订单表里的可能用于计算的几个列表的基数(唯一值):
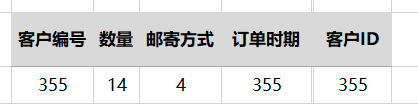
根据该图示结果:基于订单表的[客户编号]列等列表的唯一值数,可以确定其列表的基数:例如,[客户编号]列的基数是355个(由该基数重复后的扩展行则可能有无限多),[邮寄方式]只有4个,[客户ID]与[订单时期]列具有相同的基数355个。 由这些列表基数对应的表的行共1000行(所有列表都为1000行),说明每个列表中有很多的重复行,基数越多的列表,对应的重复行越少。
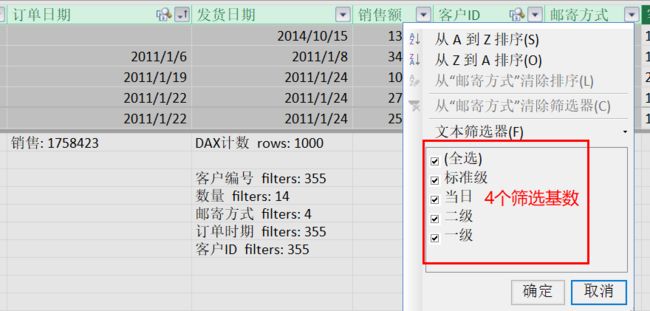
我们观察一下基数(唯一值)对应的筛选情况。例如,[邮寄方式]列里有4个唯一值的基数,它可能提供1*2*3*4=24种不同排列组合对应的筛选。我们依据该列的4个不同的基数筛选,观察每个基数的筛选结果。
我们添加了两个观察度量,一个是表行数的计数(COUNTROWS('订单')),一个是[销售]度量。请记住上图中它们对应的结果(即当前数据模型表里的计算值)分别为1758423与1000(行数)。我们直接使用[邮寄方式]列筛选(这里提供不同的4个列值。即唯一值的基数值供筛选):
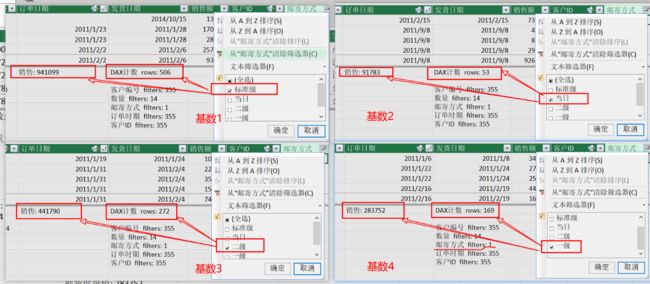
由图可知:由基数1--标准级筛选出来的表的行数为506行(我们可以说,筛选后的列表子集表的行数为506行,即一个506行的表),其他3个基数筛选出来的对应行数分别为:53、272、169。4个筛选的结果之和应为总行数:506+53+272+169=1000。你可以用同样的方式
验证另一个度量:[销售]。
上图中,使用[邮寄方式]列的列值--“标准级”筛选出来的表的行数为506行,这相当于向CALCULATE计算中添加了一个布尔值列表筛选条件:
CALCULATE(COUNTROWS('订单'), [邮寄方式]="标准级"))
由于每个筛选之间是and--并的关系(即同时满足完所有这些筛选),所以实际运用中,由于筛选的交叉等复杂情况,往往很难判断筛选子集的变化。 例如:
CALCULATE(COUNTROWS('订单'), [邮寄方式]="标准级", [邮寄方式]="一级"))
请思考这个计算的结果。
当CALCULATE()的筛选不起作用时,你首先应该检查用于筛选的列表与第一参数的范围对比(唯一值基数的多少)。因为上述CALCULATE()形态里的任何一个筛选的基数总是小于第一参数列表的基数(列值范围要小)。
因此,可以理解为CALCULATE()里的所有筛选列表,相对于第一参数的计算列表而言都是值列表(无论使用的是列表还是值列表)。也就是说,它们都是需要"定义"的值列表筛选,而不是引用列表(引用列表筛选的情况后面有专门的介绍),理解这一点很重要。否则,CALCULATE()中的筛选看起来很简单,却很容易出错。
(2) 上述CALCULATE()形态中的每个筛选是一种最简单的值列表筛选,有的称其为"直接列表筛选"或“初始列表筛选”,虽然这种说法不一定对,但这种直接筛选的特征可帮助我们了解DAX中最基本的列表筛选特性:
第一、这种筛选需要引用与计算列表同在的表(即模型)里的列表,然后定义一个值列表筛选。比如布尔值条件:[类别]="饮料",[类别]<>BLAK(),[数量]<300,[订单时期]>"2007/5/8",COUNTROWS([类别])>1等等……(其中[类别]、[数量]列、[订单时期]列与计算列表同在一个表中(在接下来了解到列表关系后,称之为:同在一个由列表关系连接的数据模型里,或另一种形态--"扩展表"里)。
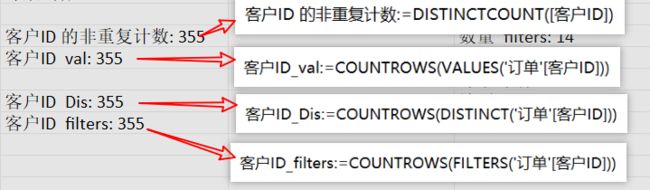
前面提到的唯一值(基数)列表在DAX计算中非常有用。我们顺便介绍几个定义唯一值列表的函数:VALUES 、 DISTINCT、DISTINCTCOUNT等。
第20式:CALCULATE的唯一值列表
获取唯一值列表的函数有:VALUES 、 DISTINCT、DISTINCTCOUNT(不重复计数),以及一个求值列表筛选次数(值)的公式4的形态(使用FILTERS,不过很少使用)。如图:
由于这不是函数系列(后面有关于它们的更详细内容),这里只简单说明几点:
(1)VALUES返回当前单元格中可见的唯一值列表,包括未匹配值的可选空白行。DISTINCT执行相同的操作,不返回未匹配值的空行(这是两者的区别)。然而, 如果空白值显示为列的有效值,这两个函数将包括空白行。唯一的区别是,添加了空白行来处理关系中的缺失值。
(2)当没有筛选器时,DISTINCT的行为对应于ALLNOBLANKROW,而VALUES的行为则对应于ALL。
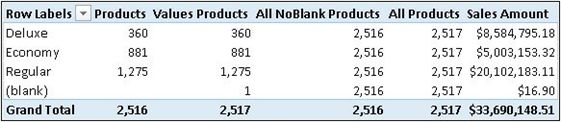
(3)VALUES也接受一个表作为参数。在这种情况下,它将返回当前单元格中可见的整个表,并有选择地包括未匹配关系的空行。例如,在数据模型中考虑以下度量,其中Sales表与Product--产品表具有关系,并包含与产品键不匹配的任何现有产品的事务记录。
[Products] : = COUNTROWS( Product )
[ValuesProducts]:= COUNTROWS(VALUES( Product ) )
[All NoBlankProducts]:=COUNTROWS(ALLNOBLANKROW( Product) )
[All Products]:=COUNTROWS(ALL( Product ) )
可以在下图中看到,在这种情况下,当没有筛选器时,VALUES的结果对应于ALL的行为,并包括添加的空白行,以显示未匹配产品的销售额。在这种情况下,不能使用DISTINCT引用一个表:如果需要删除一列中重复的行, DAX函数中没有单一这样的函数来删除重复的行(这时必须使用SUMMARIZE,稍后的部分中将看到)。
然而, 当没有筛选器时,[Products]度量计数表中的行数,并忽略一个可能的空白行,该行为与ALLNOBLANKROW相同。
(4)使用VALUES、MAX、MIN定义唯一值的值(标量)列表。
我们用一句话来说明 VALUES () 函数的功能:"VALUES () 函数从引用的列表中返回唯一值的列表 (如果仅指定一个值, 则可用作标量值列表)"。
即使VALUES是一个表函数,也会经常使用它来定义为标量值列表,这代表着DAX的一个特殊的特性行为。由于该行为,VALUES()函数似乎有一种从某个列表里过滤出某个列值的意思? 例如:
=IF(VALUES(时期表[月份]) =“2月”,“闰月”,“不在该月”)
当然,更可以在表表达式中设置VALUES。如下面的一个[ColorName] 度量,以确保选择的为相同颜色的所有产品:
[ColorName] :=IF(COUNTROWS(VALUES( 产品表[颜色] ) ) =1,--后面将用新函数替代
VALUES( 产品表[颜色] ))
可以在下图中看到结果。当[ColorName]结果包含空白时,意味着有两个或更多不同的颜色。
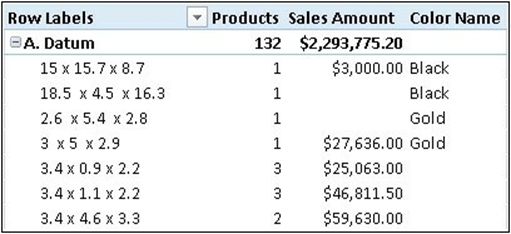
当VALUES返回一行,可以使用它将结果转换为一个标量值,比如[Color Name]度量。
有趣的是,使用VALUES()作为标量值的结果,即使它的功能是返回一个表。这不是VALUES的特殊行为,但它代表了DAX语言更一般的行为:如果需要一个表表达式返回一行或一列,并需要它自动完成,则可以使用任何表表达式来将列表转换为标量值(即将列表转换为值列表)。
前面提到的MAX、MIN也是结果返回一行,即可以使用它将结果转换为一个标量值。我们将前面“当前行”行筛选的定义:
产品表[价格分级] = COUNTROWS(
FILTER(VALUES( 产品[价格] ),
产品表[价格] >EARLIER(产品表[价格] ))) +1
修改为由MAX、MIN、VALUES值列表定义,也能表达“当前”行筛选,比如计算那些年初至今累计的产品。该公式替换得比较牵强,只是说明这种行筛选的表示方式。
[YTD年初至今累计值]=CALCULATE([销售收入],
FILTER(ALL('日期表'),'日期表'[年份]=MAX(' 日期表'[年份])
&&'日期表'[日期]<=MAX('日期表'[日期])))
在我们还没有学习到列表及值列表的形态特征时,你可能不知道VALUES()作为标量值的结果的这种情况,更不会理解它。
实践中,如果结果正好为一行或一列,则可以定义任何表表达式作为一个标量值的值列表。而当表结果返回多行时,在执行时会得到一个错误:“一个多值的表是由其他方式提供的”。
因此,你应该保持该标量值列表的转换条件,使表表达式返回一个不同的多行结果 (你应该已经知道,当你写DAX函数表达式时,该表表达式只返回一行)。前面的[Color Name]示例,使用COUNTROWS检查颜色在产品表的选择里是否只有一个值。
一个更简单的完全相同的定义方法是使用HASONEVALUE,它执行同样的检查,如果列只有一个值,返回TRUE,否则返回FALSE。以下两个语法是等价的:
COUNTROWS(VALUES( ) ) =1
HASONEVALUE( )
你应该用HASONEVALUE代替COUNTROWS方式,这有两个原因:可读性更强,以及可以稍快一些。下面是一个更好的基于HASONEVALUE设置的相同度量:
[Color Name]: = IF (HASONEVALUE ( 产品表[颜色] ), VALUES ( 产品表[颜色]))
我们经常使用“值”作为标量值列表表达式的原因是,它返回单个列,也可能返回单个行,这取决于执行的筛选条件。在许多DAX模式中,使用VALUES()作为标量表达式是很常见的,今后也可能反复出现。