TO DO
DataFrame
Read and Write DataFrame
What new in Spark 2.0
Official release note:
https://spark.apache.org/releases/spark-release-2-0-0.html
https://databricks.com/blog/2016/08/15/how-to-use-sparksession-in-apache-spark-2-0.html
SparkSession
Beyond a time-bounded interaction, SparkSession provides a single point of entry to interact with underlying Spark functionality and allows programming Spark with DataFrame and Dataset APIs. Most importantly, it curbs the number of concepts and constructs a developer has to juggle while interacting with Spark.
pyspark.sql.SQLContext(sparkContext, sparkSession=None, jsqlContext=None)
is depreciated in Spark 2.0
In previous versions of Spark, you had to create a SparkConf and SparkContext to interact with Spark, as shown here:
//set up the spark configuration and create contexts
val sparkConf = new SparkConf().setAppName("SparkSessionZipsExample").setMaster("local")
// your handle to SparkContext to access other context like SQLContext
val sc = new SparkContext(sparkConf).set("spark.some.config.option", "some-value")
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
Whereas in Spark 2.0 the same effects can be achieved through SparkSession, without expliciting creating SparkConf, SparkContext or SQLContext, as they’re encapsulated within the SparkSession. Using a builder design pattern, it instantiates a SparkSession object if one does not already exist, along with its associated underlying contexts.
// Create a SparkSession. No need to create SparkContext
// You automatically get it as part of the SparkSession
val warehouseLocation = "file:${system:user.dir}/spark-warehouse"
val spark = SparkSession
.builder()
.appName("SparkSessionZipsExample")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()
In Spark 1.x
SparkConf, SparkContext -> sc -> sqlContext
My understanding is, in 1.x, everything is under SparkContext (sc), e.g. sqlContext, HiveContext, or Streaming, MLlib, etc (verify this! )
In Spark 2.x
but in 2.x, different modules have their independent entry
- SparkContext is for base Spark
- SparkSession is for Spark SQL
- ... for Spark Streaming
SparkSession Encapsulates SparkContext
Lastly, for historical context, let’s briefly understand the SparkContext’s underlying functionality.
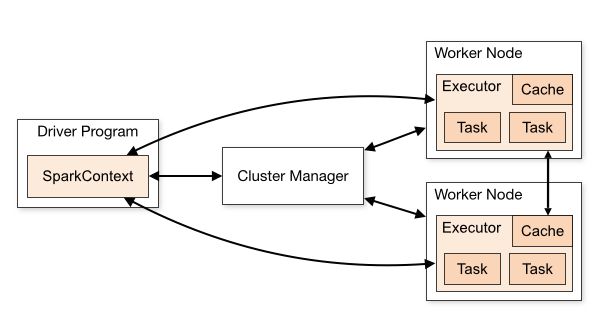
As shown in the diagram, a SparkContext is a conduit to access all Spark functionality; only a single SparkContext exists per JVM. The Spark driver program uses it to connect to the cluster manager to communicate, submit Spark jobs and knows what resource manager (YARN, Mesos or Standalone) to communicate to. It allows you to configure Spark configuration parameters. And through SparkContext, the driver can access other contexts such as SQLContext, HiveContext, and StreamingContext to program Spark.
However, with Spark 2.0, SparkSession can access all aforementioned Spark’s functionality through a single-unified point of entry. As well as making it simpler to access DataFrame and Dataset APIs, it also subsumes the underlying contexts to manipulate data.
In summation, what I demonstrated in this blog is that all functionality previously available through SparkContext, SQLContext or HiveContext in early versions of Spark are now available via SparkSession. In essence, SparkSession is a single-unified entry point to manipulate data with Spark, minimizing number of concepts to remember or construct. Hence, if you have fewer programming constructs to juggle, you’re more likely to make fewer mistakes and your code is likely to be less cluttered.