下面我们来看run_evaluate()函数。
- train.py -> model.train() -> base_model.py -> train() -> run_epoch() -> ner_model.py -> run_epoch() -> run_evaluate()
def run_evaluate(self, test):
"""Evaluates performance on test set
Args:
test: dataset that yields tuple of (sentences, tags)
Returns:
metrics: (dict) metrics["acc"] = 98.4, ...
"""
accs = []
correct_preds, total_correct, total_preds = 0., 0., 0.
for words, labels in minibatches(test, self.config.batch_size):
labels_pred, sequence_lengths = self.predict_batch(words)
for lab, lab_pred, length in zip(labels, labels_pred,
sequence_lengths):
lab = lab[:length]
lab_pred = lab_pred[:length]
accs += [a==b for (a, b) in zip(lab, lab_pred)]
lab_chunks = set(get_chunks(lab, self.config.vocab_tags))
lab_pred_chunks = set(get_chunks(lab_pred,
self.config.vocab_tags))
correct_preds += len(lab_chunks & lab_pred_chunks)
total_preds += len(lab_pred_chunks)
total_correct += len(lab_chunks)
p = correct_preds / total_preds if correct_preds > 0 else 0
r = correct_preds / total_correct if correct_preds > 0 else 0
f1 = 2 * p * r / (p + r) if correct_preds > 0 else 0
acc = np.mean(accs)
return {"acc": 100*acc, "f1": 100*f1}
其实分析到现在,程序已经快到尾声了。主要的处理数据啊,构建图啊,建立词向量啊,设置batch和epoch进行迭代啊什么的都搞完了,现在要做评测,以进一步改进算法。
- 先看参数,这里传入self和需要测试的数据test。
在测试集上评估性能,其中参数test是(sentences + tags)键值对,返回字典类型的数据,比如这里是acc和f1。 - 先建立一个列表acc用于存放准确率
- correct_preds, total_correct, total_preds = 0., 0., 0.这仨参数代表什么我还不清楚,不过有种感觉是准确率与查全率之类的。
- 接下来用minibatches函数将words和labels提取出来。
紧接着我们看到一个预测函数predict_batch(),跳进去看一下。
ner_model.py -> predict_batch()
def predict_batch(self, words):
"""
Args:
words: list of sentences
Returns:
labels_pred: list of labels for each sentence
sequence_length
"""
fd, sequence_lengths = self.get_feed_dict(words, dropout=1.0)
if self.config.use_crf:
# get tag scores and transition params of CRF
viterbi_sequences = []
logits, trans_params = self.sess.run(
[self.logits, self.trans_params], feed_dict=fd)
# iterate over the sentences because no batching in vitervi_decode
for logit, sequence_length in zip(logits, sequence_lengths):
logit = logit[:sequence_length] # keep only the valid steps
viterbi_seq, viterbi_score = tf.contrib.crf.viterbi_decode(
logit, trans_params)
viterbi_sequences += [viterbi_seq]
return viterbi_sequences, sequence_lengths
else:
labels_pred = self.sess.run(self.labels_pred, feed_dict=fd)
return labels_pred, sequence_lengths
- 传入的参数是words,返回的值是预测的标签和序列长度,我设断点进去调试了一下。
 fd
fd
这是fd的值,阔以看到是字典类型,里面存放着这些变量。
sequence_length的值为
sequence_length = : [7, 9, 7, 7, 9, 7, 7, 9, 7, 7, 9]
反观我们的训练数据,

test.txt
嗯没错~
- 接下来是一个if的判断,是否使用了crf(条件随机场),好吧,条件随机场我也会单独出一章来分析。这里我们用了crf技术,所以进一步走。
- 首先建立viterbi序列,然后将logits、transparams、feed_dict代入进行运算,并传入给新的logits、transparams,然后一个for循环,这里先将logits和sequence_length打包成元组对,然后依次提取,我们看,
 image.png
image.png
比较好理解,哈哈,pycharm的调试机制还是很好用的。
 image.png
image.png
这是logit中的内容,然后我们只取前sequence_length个,因为后面的数据没啥用。。。都是填充上去的,所以
logit = logit[:sequence_length] # keep only the valid steps
最后,使用TensorFlow自带的tf.contrib.crf.viterbi_decode(logit, trans_params)函数,传入logit和trans_params,关于trans_params,之前我们大概分析过一个crf的极大似然函数,其中一个返回值就是它。
log_likelihood, trans_params = tf.contrib.crf.crf_log_likelihood(
self.logits, self.labels, self.sequence_lengths)
这里
log_likelihood是标量
transition_params是形状为[num_tags, num_tags] 的转移矩阵。
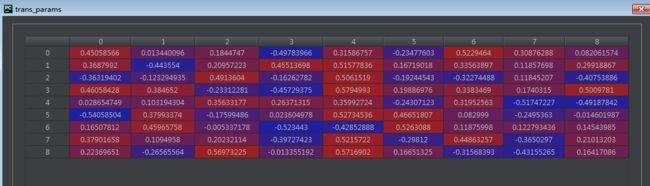
trans_params在此
最后呢更新viterbi序列,条件随机场的预测算法是著名的 维特比算法
最后呢返回维特比序列( viterbi_sequences)和序列长度( sequences_lengths)

image.png
看这里,这是我运行了一次的结果。
否则的话呢?如果我们没运行crf算法,那就冲。
labels_pred = self.sess.run(self.labels_pred, feed_dict=fd)
好那我们试一下,把config.py下的use_crf改成False:
image.png
????怎么会这样?全是6,我玩个鸟,6代表 Other(从0开始计)

image.png
好了好了,说明没有 CRF这就是个鬼,我们还是先切回来看刺激的CRF环节。
接下来一个for循环,先把 label、label_predict、length取出来然后准备进行评估。都先取前length个数据,然后更新 accs, accs += [a==b for (a, b) in zip(lab, lab_pred)]
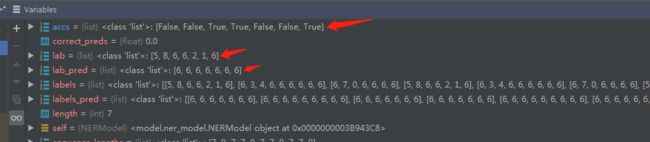
image.png
这是accs、label和label_pred的内容,容易理解。
再然后。
lab_chunks = set(get_chunks(lab, self.config.vocab_tags))
lab_pred_chunks = set(get_chunks(lab_pred,
self.config.vocab_tags))
还记得Python中set()函数吗?建立一个无序不重复的元素集。
这里还有一个get_chunks函数
def get_chunks(seq, tags):
"""Given a sequence of tags, group entities and their position
Args:
seq: [4, 4, 0, 0, ...] sequence of labels
tags: dict["O"] = 4
Returns:
list of (chunk_type, chunk_start, chunk_end)
Example:
seq = [4, 5, 0, 3]
tags = {"B-PER": 4, "I-PER": 5, "B-LOC": 3}
result = [("PER", 0, 2), ("LOC", 3, 4)]
"""
default = tags[NONE]
idx_to_tag = {idx: tag for tag, idx in tags.items()}
chunks = []
chunk_type, chunk_start = None, None
for i, tok in enumerate(seq):
# End of a chunk 1
if tok == default and chunk_type is not None:
# Add a chunk.
chunk = (chunk_type, chunk_start, i)
chunks.append(chunk)
chunk_type, chunk_start = None, None
# End of a chunk + start of a chunk!
elif tok != default:
tok_chunk_class, tok_chunk_type = get_chunk_type(tok, idx_to_tag)
if chunk_type is None:
chunk_type, chunk_start = tok_chunk_type, i
elif tok_chunk_type != chunk_type or tok_chunk_class == "B":
chunk = (chunk_type, chunk_start, i)
chunks.append(chunk)
chunk_type, chunk_start = tok_chunk_type, i
else:
pass
# end condition
if chunk_type is not None:
chunk = (chunk_type, chunk_start, len(seq))
chunks.append(chunk)
return chunks
看函数的名字,大概意思是获取数据块???传入的参数是seq和tags
函数介绍:给定一组标签、组实体及其位置。
这里传入两个参数:
- 第一个是带有标签的序列。
-
第二个是字典类型的数据,(标签,键值)对形式。
还是来张图比较直观呢。
 image.png
image.png - 返回值的话这里返回一个list类型的数据,其中每一组记录了三个数据:chunk_type、 chunk_start、 chunk_end。这里作者给了一个例子。
 image.png
image.png
首先设置默认值default,这里是tags[NONE],NONE的定义在这个data_utils.py文件的开头有定义:NONE = "O",也就是Other的意思。这里tags["O"]的值为6,所以default为6。 - 然后idx_to_tag这里把dict类型的tags提取其中的元素(tag、id)并转换成(id,tag)的形式,说白了就是字典里双方对调了一下位置。
 image.png
image.png
感觉没啥卵用呢。。。我们接下去再看。(不过这里我们get到一个小知识是dict类型的元素有一个函数是items(),用来提取它里面的内容) - 接下来构建列表chunk了,就是我们要返回的东西的列表。然后建立chunk_type、chunk_start并先初始化为None。咦为啥没建chunk_end?
管它呢,接着一个for函数里接enumerate关键字,用于遍历序列时同时列出数据和数据下标。传入的参数是seq,我们之前预测的序列标签。
 image.png
image.png
阔以看到,初始时这里i是1,tok是6。
这里进入一个if判断:如果当前tok是默认值6(Other)并且chunk_type非空(is not None),那么把(chunk_type, chunk_start, i)赋给chunk并append进chunks列表里,并将chunk_type、chunk_start重新赋None。这里因为chunk_type为None,故我们进入下面的elif:
# End of a chunk + start of a chunk!
elif tok != default:
tok_chunk_class, tok_chunk_type = get_chunk_type(tok, idx_to_tag)
if chunk_type is None:
chunk_type, chunk_start = tok_chunk_type, i
elif tok_chunk_type != chunk_type or tok_chunk_class == "B":
chunk = (chunk_type, chunk_start, i)
chunks.append(chunk)
chunk_type, chunk_start = tok_chunk_type, i
else:
pass
如果tok不是default值6,是其他的实体类别,那么我们进入另一个函数get_chunk_type()这个函数其实是把我们的实体类整合一下,,,什么意思呢?再来回顾一下我们的tags.txt。
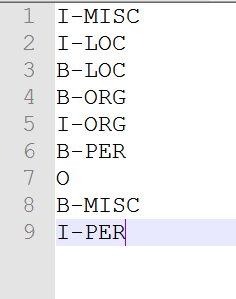
image.png
这里你会发现,咦为啥有好多 LOC、ORG、PER、MISC?因为形如地名(location)、人名(person)、机构名(organization)和混杂类型(miscellaneous),都不仅仅是一个单词就能判定的,如 北京,北 和 京本身并无太大意义,但合起来才是一个地名,又如 European Union,European和Union合起来才表示欧盟这一机构组织 (ORG),所以这里我们又引入了新的元素: B、I、E(我查资料有的项目只使用 B和I),其中B代表实体的开头(Begin),I代表实体的中间(In)、E代表实体的尾部(End),如: 厦门这里我们给出 厦(B-LOC)门(I-LOC)。好下面我们来看 get_chunk_type()。
def get_chunk_type(tok, idx_to_tag):
"""
Args:
tok: id of token, ex 4
idx_to_tag: dictionary {4: "B-PER", ...}
Returns:
tuple: "B", "PER"
"""
tag_name = idx_to_tag[tok]
tag_class = tag_name.split('-')[0]
tag_type = tag_name.split('-')[-1]
return tag_class, tag_type
这里它把属于同一类型的标签拆开(根据 — 符号),这里用到了一个split函数,作者的示例也给得很明晰了。返回结果是tag_class(B、I、E)和tag_type(PER、LOC。。。)
如果。。。。好的吧剩下的几句我也不太懂,有点懵,因为目前的话数据有点问题:

image.png
预测的数据 seq全他妈是6(Other),我不知道是哪出问题了,可能是数据量太少,我这程序跳转不到if和elif中,只能pass,等我把问题彻底搞清了再来排雷吧(哭泣)。
-
总之,最后返回的类型就是实体的标签和它们对应的位置。
 image.png
image.png - 接着计算acc(准确率)和f1分数,并返回字典。
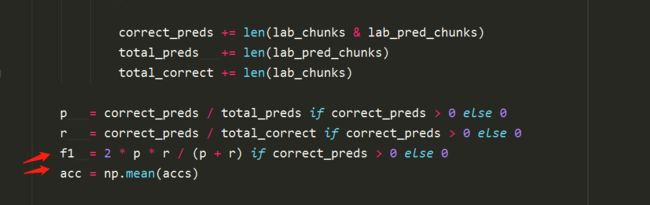 image.png
image.png
函数返回到ner_model.py中的run_epoch()函数体。
 image.png
image.png
此时,metric是一个字典类型,然后我们使用format格式化函数,它通过{}和:来代替以前的 %,最近我在看项目的时候遇到好多使用format格式化输出的方法,后期也会专门出一章来讲讲。这里04.2f的意思是总共输出4位,其中两位是小数,举个例子03.25、14.6
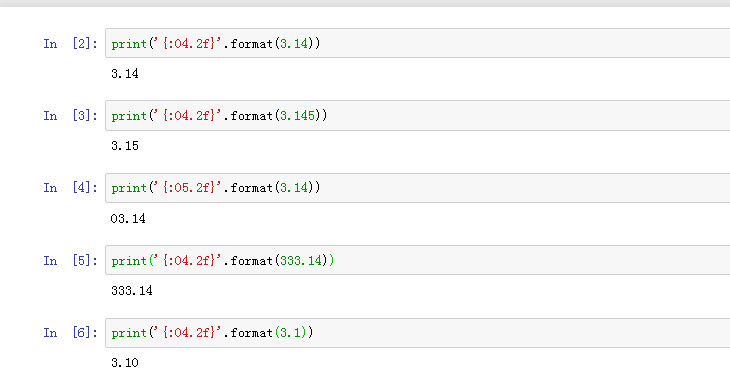 image.png
image.png
看一下几个尝试,我们发现,format函数是会自动四舍五入的,前面的04意思是要输出4位:这里我们看到Python将小数点也算成一位,如果没够四位的话第一位前面补0,超过四位的话,那就超咯,后面的.2f意思是保留小数点后两位。不够的话后边补0。
函数最后返回f1值给base_model.py下的train()函数中的score参数。