- 所谓的块设备指的是硬盘、FLASH等的存储设备,此类设备存在一个缺点就是随机读写的时候有时候速度会变慢。下面一一介绍对于块设备驱动对于它的处理。
1、硬盘的结构
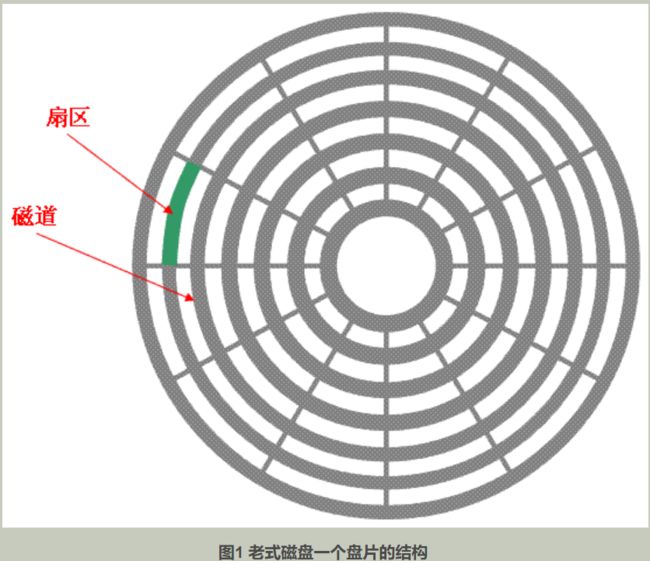
以硬盘为例,先介绍下老式磁盘的结构,因为块设备驱动的编写过程中涉及到很多老式磁盘的概念。先从磁盘片的结构说起,如图1所示,图中灰色的一圈圈同心圆为一条条磁道,从圆心向外画直线,可以将磁道划分为若干圆弧段,每个磁道上一个圆弧段被称之为扇区(图中的绿色部分)。扇区是磁盘的最小组成单位,通常是512字节的。
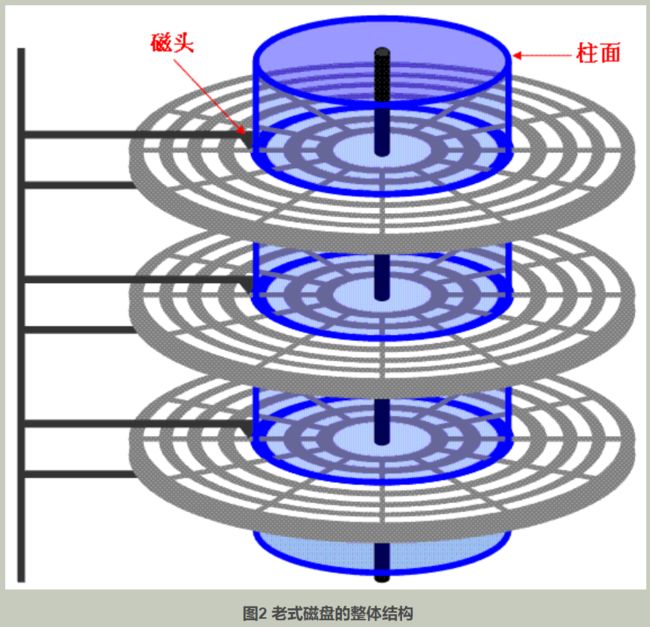
下图二展示了由一个个磁片组成的磁盘立体结构,一个盘片上下两面都是可读可写的,图书蓝色部分叫做柱面。
简单对磁盘进行了 介绍后,下面对它的几个重要的参数进行说明:
- 磁头(head)
- 磁道(track)
- 柱面(cylinder)
- 扇区(sector)
- 圆盘(platter)
图二中的磁盘是一个3个圆盘、6个磁头,7个柱面(磁道)的磁盘,图二中每条磁道有12个扇区,所以此磁盘的容量为6*7*12*512字节。具体的计算公式为:
存储容量 = 磁头数量 * 磁道(柱面)数量 * 每个磁道的扇区数 * 每个扇区的字节数
上面的公式在写块设备的驱动程序时会用到。
2、磁盘的操作
假设我要进行如下的操作:
a、读柱面1的 数据
b、往柱面2写数据
c、读柱面1的数据
如果按照正常abc流程读写,那么对于磁头会跳转2次。而块设备驱动程序会对这个操作进行优化,而不是马上去执行这个操作。它优化后的执行顺序acb,这样操作的话磁头就只要跳转一次即可。这就是磁盘类的块设备读写不会马上执行的原因。
3、FLASH的操作
FLASH由于其特殊性导致,只能写0而不能写1,所以在写数据前必须以块为单位先擦除块,然后再往块里写数据。
假设我要进行如下的操作:
a、往块0的扇区0写数据
b、往块0的扇区1写数据
如果按照正常的流程读写,那么操作是这样的:
操作(写扇区0):
1、读出整块BUFFER
2、修改buffuer的扇区0
3、擦除块0
4、烧写块0
操作(写扇区1):
1、读出整块BUFFER
2、修改buffuer的扇区1
3、擦除块0
4、烧写块0
但是如果优化一下的话:
1、先不执行,放入队列
2、优化后执行(合并)=》
a、读出块0
b、修改扇区0、扇区1
c、擦除
d、烧写
4、块设备驱动程序思想
经过2、3的分析可以知道块设备驱动程序是这样的:
1、把读写放入队列
2、优化后再执行
5、块设备驱动程序框架
块设备驱动程序框架入下图所示,首先应用层调用open、read、write等操作文件,然后进入文件系统层;文件系统将文件的读写转换为扇区的读写;接着就是来到ll_rw_block函数,它主要实现二个功能,一是把“读写”放入队列、二是调用队列的处理函数(优化/调顺序/合并)。从文件系统到ll_rw_blockc的调用过程可以参考《Linux内核源代码情景分析》这本书。这一过程放到以后再研究。

图3. 块设备驱动程序框架
下面来分析ll_rw_block,下面的代码是ll_rw_block的调用层次,
for (i = 0; i < nr; i++) { struct buffer_head *bh = bhs[i]; submit_bh(WRITE, bh); struct bio *bio;//使用bh来构造bio(block input/output) submit_bio(rw, bio); //通用的构造请求,使用bio来构造请求(request) generic_make_request(bio); __generic_make_request(bio); request_queue_t q = bdev_get_queue(bio->bi_bdev);//找到队列 // 调用队列的“构造请求函数” ret = q->make_request_fn(q, bio); //默认的函数是__make_request //先尝试合并 elv_merge(q, &req, bio); //如果合并不成功,那么使用bio构造请求 init_request_from_bio(req, bio); //把请求放入队列 add_request(q, req); //执行队列 __generic_unplug_device(q); //调用队列的“处理函数” q->request_fn(q);
直接列出写块设备驱动程序的步骤:
1、分配一个gendisk:alloc_disk
2、设置
2.1、分配/设置队列:request_queue_t //它提供读写能力
blk_init_queue
2.2、设置gendisk其他信息 //它提供属性:比如容量
3、注册:add_disk
6、利用内存模拟块设备驱动程序
直接贴上代码(参考drivers\block\xd.c、drivers\block\z2ram.c)
#include#include #include #include #include #include #include #include #include #include #include #include #include #include #include #include #include #include #include static struct gendisk *ramblock_gendisk;//磁盘的结构体 static request_queue_t *ramblock_queue;//处理队列 static int major;//主设备号 static DEFINE_SPINLOCK(ramblock_lock);//大内核锁 #define RAMBLOCK_SIZE 512*512 //操作的内存大小,以字节为单位 static unsigned char *ramblock_buf; static int ramblock_getgeo(struct block_device *bdev, struct hd_geometry *geo) { /* 容量=heads*cylinders*sectors*512 */ geo->heads = 2; //硬盘磁头数 geo->sectors = 32;//扇区数 geo->cylinders = RAMBLOCK_SIZE/2/32/512;//硬盘柱数 return 0; } static struct block_device_operations ramblock_fops = { .owner = THIS_MODULE, .getgeo = ramblock_getgeo, }; static void do_ramblock_request(request_queue_t *q) { static int r_cnt = 0; static int w_cnt = 0; struct request *req;//请求描述符 while ((req = elv_next_request(q)) != NULL) //取得请求描述符 { /* 数据传输三要素: 源,目的,长度 */ /* 源/目的: */ unsigned long offset = req->sector*512;//当前的扇区 /*长度*/ unsigned long len = req->current_nr_sectors * 512;//当前扇区数 if (rq_data_dir(req) == READ)//如果是读 { printk("do_ramblock_request read %d\n", ++r_cnt); memcpy(req->buffer, ramblock_buf+offset, len);//从内存中读出然后传给文件系统 } else { printk("do_ramblock_request write %d\n", ++w_cnt); memcpy(ramblock_buf+offset, req->buffer, len);//从文件系统中取得的数据传给内存 } end_request(req, 1);//结束此次请求 } } static int ramblock_init(void) { /* 1、分配一个gendisk:alloc_disk */ ramblock_gendisk = alloc_disk(16); /* 次设备号个数:分区个数+1 */ if(!ramblock_gendisk) return -1; /* 2、设置 */ /* 2.1、分配/设置队列:request_queue_t:它提供读写能力 */ ramblock_queue = blk_init_queue(do_ramblock_request, &ramblock_lock); if (!ramblock_queue) return -1; //放入ramblock_gendisk ramblock_gendisk->queue = ramblock_queue; /* 2.2、设置gendisk其他信息,它提供属性:比如容量 */ major = register_blkdev(0,"ramblock"); /*cat /proc/devices */ //主设备号 ramblock_gendisk->major = major; //第一个次设备号 ramblock_gendisk->first_minor= 0; //名字 sprintf(ramblock_gendisk->disk_name, "ramblock"); //fops(一定得提供这个结构体) ramblock_gendisk->fops = &ramblock_fops; //队列 ramblock_gendisk->queue = ramblock_queue; //容量(以扇区为单位)内核永远认为扇区是512字节 set_capacity(ramblock_gendisk, RAMBLOCK_SIZE / 512); /* 3、硬件相关操作 */ //分配ram缓存 ramblock_buf = kzalloc(RAMBLOCK_SIZE, GFP_KERNEL); if(!ramblock_buf) return -1; /* 4、注册 */ add_disk(ramblock_gendisk); return 0; } static void ramblock_exit(void) { unregister_blkdev(major, "ramblock"); del_gendisk(ramblock_gendisk); put_disk(ramblock_gendisk); blk_cleanup_queue(ramblock_queue); kfree(ramblock_buf); } module_init(ramblock_init); module_exit(ramblock_exit); MODULE_LICENSE("GPL");
下面以上面的程序来做实验,把此程序编译后得到12th_ramblock_drv.ko模块
实验1:挂接块设备
在开发板上:
1、insmod 12th_ramblock_drv.ko
2、格式化:mkdosfs /dev/ramblock
3、挂接:mount /dev/ramblock /tmp
4、读写文件:cd /tmp,在里面vi文件
5、cd /;umount /tmp/
6、cat /dev/ramblock > /mnt/ramblock.bin // 相当于磁盘映像
7、在pc上查看ramblock.bin
sudo mount -o loop ramblock.bin /mnt // 把普通文件当成块设备挂接到/mnt目录
最终可以看到mnt下面的文件与原先在/tmp下的文件一样
实验2:块设备写入的时机
在读或写操作里面增加了一条打印语句,测试读或写的时间。可以看到不会马上去写,而是过一段时间再写进去。是因为等待队列的电梯算法的缘故
# cp /etc/inittab /tmp
do_ramblock_request read 43
# do_ramblock_request write 6
do_ramblock_request write 7
do_ramblock_request write 8
do_ramblock_request write 9
实验3:块设备分区
# fdisk /dev/ramblock //分区,分区以柱面为单位
下面分配了两个分区,其中/dev/ramblock为全部的块设备、/dev/ramblock1为分区2、 /dev/ramblock2为分区2
# ls /dev/ramblock* -l
brw-rw---- 1 0 0 254, 0 Jan 1 01:25 /dev/ramblock
brw-rw---- 1 0 0 254, 1 Jan 1 01:25 /dev/ramblock1
brw-rw---- 1 0 0 254, 2 Jan 1 01:25 /dev/ramblock2
a、分区表为磁盘里的第一个扇区
b、挂接分区其实是以某种文件系统的格式处理