前言
下面文章从认知,使用到反思提炼三个层面对函数式编程进行讲解。
分别对应“函数编程的概念”,
“Java 8中的函数式编程接口汇总” 和使用和理解Stream”讲解实例使用,
再最终回归“函数式编程的优点和编程建议”
函数编程的概念
什么是函数式编程
函数式编程 ( functional programming, 即 FP )是一种编程范式,我们常见命令式编程(Imperative programming),函数式编程,逻辑式编程,常见的面向对象编程是也是一种命令式编程。
命令式编程是面向计算机硬件的抽象,有变量(对应着存储单元),赋值语句(获取,存储指令),表达式(内存引用和算术运算)和控制语句(跳转指令),一句话,命令式程序就是一个冯诺依曼机的指令序列。而函数式编程是面向数学的抽象,将计算描述为一种表达式求值,一句话,函数式程序就是一个表达式。
先看一个非函数式的例子:
int cnt;
void increment(){
cnt++;
}
那么,函数式的应该怎么写呢?
int increment( int cnt){
return cnt+1;
}
这个例子就是函数式编程的准则:没有被外界所影响,而且也不改变外部数据的值,而是返回一个新的值给你。函数式编程其实就是数学中的函数概念,比如f(x)=x+2,定义的这个函数就是输入的值x和f(x)之间的关系。
函数编程有什么特点?
函数式编程更加安全。不更改变量的值,
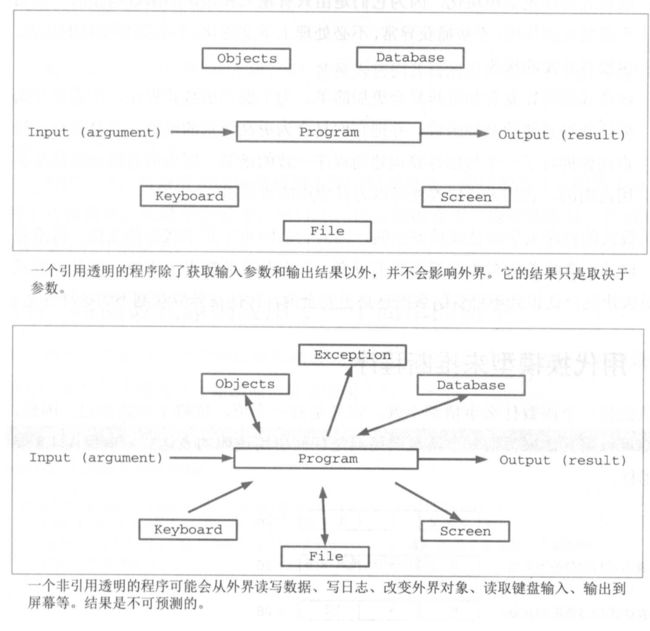
对于多线程应用程序 ,条件组合的数量使测试成为不可能 。(明确分离程序中可以被证明为正确的 部分和不能证明为正确的部分。这就是函数式编程技术所能提供的 。)。函数式编程需要将抽象推至极致的理念。 它允许明确分离程序 中可以被证明为正确的部分与输出取决于外部条件的其他部分。 通过这种方式,函数式程序是不太容易产生bug 的程序,它的 bug只会驻留在特定的受限区域。
java不是命令式语言,其实也可以适用于函数式编程。只是一开始我们的java可能对于函数式编程相比之下没有其他函数式编程语言那么友好。
Java 8中的函数式编程接口汇总
Function接口
首先从Java 8 Function接口开始介绍,尝试了解一下什么是函数式编程。
package java.util.function;
import java.util.Objects;
@FunctionalInterface
public interface Function {
/**
*该接口的唯一个抽象方法是apply方法,接受一个类型的参数,有返回值.功能
*是将参数赋予相应的方法.
*/
R apply(T t);
/**
*默认方法,先用入参去调用apply方法,然后再用调用者去调用apply方法.调*用的
*Object.requireNonNull是java7的新特性,如果before是null值的话直接*抛出异常.
*/
default Function compose(Function before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
/**
*默认方法,与compose方法相反,先用调用者去调用apply方法,然后再用入
*参去调用apply方法.
*/
default Function andThen(Function after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
/**
* 静态方法,java8新特性,返回当前正在执行的方法.
*
*/
static Function identity() {
return t -> t;
}
不难看出,除了第一个方法以外,其他三个方法的返回值都是Function,所以后面三个方法是可以链式调用(即用"."方法)的,就如建造者模式(Build)一样.
我们尝试构建两个函数分别返回2n和n+2。
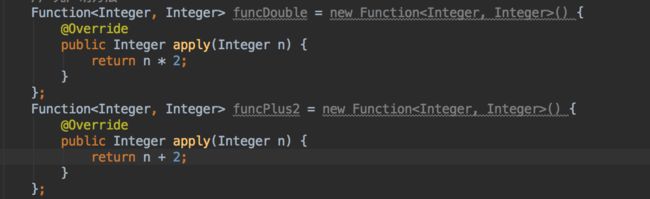
这时候IDE会提醒我们可以切换为lambda表达式,切换为lambda后代码如下(lambda被用于接收特定接口的地 方, Java 正是以此来决定调用哪个方法的。):
import java.util.function.Function;
public class FunctionTest {
public static void main(String[] args) {
// 先声明方法
Function f = (n) -> n * 2;
Function g = (n) -> n + 2;
System.out.println(f.apply(3));
System.out.println(g.apply(3));
System.out.println(f.andThen(g).apply(3));
System.out.println(f.compose(g).apply(3));
System.out.println(Function.identity().compose(f).apply(8));
}
}
来看看上面的返回结果,

理解 Function接口
- @FunctionalInterface用于函数式接口类型声明的信息注解类型。
- 函数式接口只能有一个抽象方法,并排除接口默认方法以及声明中覆盖Object的公开方法的统计。(default和static定义的方法除外)
- @FunctionalInterface不能标注在注解、类、枚举类上。
如何理解上面的compose方法?就是类似理解数学中的复合函数(高阶函数)。
f.compose(g).apply(3) 也就是f(g(x)),相当于把g(x)的返回值当作f(x)的输入。所以f(g(x))=(3+2)2=10 .。所以如果是g.compose(f).apply(3) =g(f(x))=(32)+2=8
所以我们再来看看上面的代码片段,是否会清晰一些?
@FunctionalInterface
public interface Function {
/**
*该接口的唯一个抽象方法是apply方法,接受一个类型的参数,有返回值.功能
*是将参数赋予相应的方法.
*/
R apply(T t);
/**
*默认方法,先用入参去调用apply方法,然后再用调用者去调用apply方法.调*用的
*Object.requireNonNull是java7的新特性,如果before是null值的话直接*抛出异常.
*/
default Function compose(Function before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
}
Consumer接口
Consumer是一个函数式编程接口; 顾名思义,Consumer的意思就是消费,即针对某个东西我们来使用它,因此它包含有一个有输入而无输出的accept接口方法;
除accept方法,它还包含有andThen这个方法;
/**
* Represents an operation that accepts a single input argument and returns no
* result. Unlike most other functional interfaces, {@code Consumer} is expected
* to operate via side-effects.
*
* This is a functional interface
* whose functional method is {@link #accept(Object)}.
*
* @param the type of the input to the operation
*
* @since 1.8
*/
@FunctionalInterface
public interface Consumer {
/**
* Performs this operation on the given argument.
*
* @param t the input argument
*/
void accept(T t);
/**
* Returns a composed {@code Consumer} that performs, in sequence, this
* operation followed by the {@code after} operation. If performing either
* operation throws an exception, it is relayed to the caller of the
* composed operation. If performing this operation throws an exception,
* the {@code after} operation will not be performed.
*
* @param after the operation to perform after this operation
* @return a composed {@code Consumer} that performs in sequence this
* operation followed by the {@code after} operation
* @throws NullPointerException if {@code after} is null
*/
default Consumer andThen(Consumer after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
public static void main(String[] args) {
Consumer f =n->System.out.println(n);
// Consumer f = System.out::println;
Consumer f2 = n -> System.out.println(n + "-F2");
//执行完f后再执行f2的Accept方法
f.andThen(f2).accept("test");
//连续执行f的Accept方法
f.andThen(f).andThen(f).andThen(f2).accept("test1");
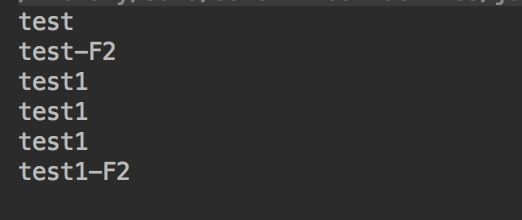
下面我们来探索java 8中的简化方式。
其实,定义一个Consumer对象,传统的方式是这样定义的:
Consumer c = new Consumer() {
@Override
public void accept(Object o) {
System.out.println(o);
}
};
而在Java8中,针对函数式编程接口,可以这样定义:
Consumer c = (o) -> {
System.out.println(o);
};
函数式编程接口都只有一个抽象方法,因此在采用这种写法时,编译器会将这段函数编译后当作该抽象方法的实现。(如果接口有多个抽象方法,编译器就不知道这段函数应该是实现哪个方法的了。)
因此,=后面的函数体我们就可以看成是accept函数的实现。这就是我们lambda表达式的写法啦。
输入:->前面的部分,即被()包围的部分。此处只有一个输入参数,实际上输入是可以有多个的,如两个参数时写法:(a, b);当然也可以没有输入,此时直接就可以是()。
函数体:->后面的部分,即被{}包围的部分;可以是一段代码。
输出:函数式编程可以没有返回值,也可以有返回值。如果有返回值时,需要代码段的最后一句通过return的方式返回对应的值。
当函数体中只有一个语句时,可以去掉{}进一步简化:
Consumer c = (o) -> System.out.println(o);
然而这还不是最简的,由于此处只是进行打印,调用了System.out中的println静态方法对输入参数直接进行打印,因此可以简化成以下写法:
Consumer c = System.out::println;
它表示的意思就是针对输入的参数将其调用System.out中的静态方法println进行打印。
到这一步就可以感受到函数式编程的强大能力。
通过最后一段代码,我们可以简单的理解函数式编程,Consumer接口直接就可以当成一个函数了,这个函数接收一个输入参数,然后针对这个输入进行处理;当然其本质上仍旧是一个对象,但我们已经省去了诸如老方式中的对象定义过程,直接使用一段代码来给函数式接口对象赋值。
因此可以做为其它方法的参数或者返回值,可以与原有的代码实现无缝集成!
Predicate接口
Predicate为函数式接口,predicate的中文意思是“断定”,即判断的意思,判断某个东西是否满足某种条件; 因此它包含test方法,根据输入值来做逻辑判断,其结果为True或者False。
@FunctionalInterface
public interface Predicate {
/**
* Evaluates this predicate on the given argument.
*
* @param t the input argument
* @return {@code true} if the input argument matches the predicate,
* otherwise {@code false}
*/
boolean test(T t);
/**
* Returns a composed predicate that represents a short-circuiting logical
* AND of this predicate and another. When evaluating the composed
* predicate, if this predicate is {@code false}, then the {@code other}
* predicate is not evaluated.
*
* Any exceptions thrown during evaluation of either predicate are relayed
* to the caller; if evaluation of this predicate throws an exception, the
* {@code other} predicate will not be evaluated.
*
* @param other a predicate that will be logically-ANDed with this
* predicate
* @return a composed predicate that represents the short-circuiting logical
* AND of this predicate and the {@code other} predicate
* @throws NullPointerException if other is null
*/
default Predicate and(Predicate other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
/**
* Returns a predicate that represents the logical negation of this
* predicate.
*
* @return a predicate that represents the logical negation of this
* predicate
*/
default Predicate negate() {
return (t) -> !test(t);
}
/**
* Returns a composed predicate that represents a short-circuiting logical
* OR of this predicate and another. When evaluating the composed
* predicate, if this predicate is {@code true}, then the {@code other}
* predicate is not evaluated.
*
* Any exceptions thrown during evaluation of either predicate are relayed
* to the caller; if evaluation of this predicate throws an exception, the
* {@code other} predicate will not be evaluated.
*
* @param other a predicate that will be logically-ORed with this
* predicate
* @return a composed predicate that represents the short-circuiting logical
* OR of this predicate and the {@code other} predicate
* @throws NullPointerException if other is null
*/
default Predicate or(Predicate other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
/**
* Returns a predicate that tests if two arguments are equal according
* to {@link Objects#equals(Object, Object)}.
*
* @param the type of arguments to the predicate
* @param targetRef the object reference with which to compare for equality,
* which may be {@code null}
* @return a predicate that tests if two arguments are equal according
* to {@link Objects#equals(Object, Object)}
*/
static Predicate isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}
它的使用方法示例如下:
/**
* Predicate测试
*/
private static void predicateTest() {
Predicate p = o -> o.equals("test");
Predicate g = o -> o.startsWith("t");
/**
* negate: 用于对原来的Predicate做取反处理;
* 如当调用p.test("test")为True时,调用p.negate().test("test")就会是False;
*/
Assert.assertFalse(p.negate().test("test"));
/**
* and: 针对同一输入值,多个Predicate均返回True时返回True,否则返回False;所以下方返回true
*/
Assert.assertTrue(p.and(g).test("test"));
/**
* or: 针对同一输入值,多个Predicate只要有一个返回True则返回True,否则返回False,所以下方返回true
*/
Assert.assertTrue(p.or(g).test("ta"));
}
使用和理解Stream
关注lambda表达式和函数式编程,不得不关注Stream。Java SE 8 中引入的一个这样的库是java.util.stream包 (Streams),它有助于为各种数据来源上的可能的并行批量操作建立简明的、声明性的表达式。
下面在使用和理解Stream中继续探索函数式编程的魅力。
如何使用Stream?
下面举个例子。
public class FunctionTestJava8 {
private ArrayList这个查询的命令版本(for循环)非常简单,而且需要更少的代码行即可表达。为了体现流方法的好处,示例问题没有必要变得过于复杂。流利用了这种最强大的计算原理:组合。通过使用简单的构建块(过滤、映射、排序、聚合)来组合复杂的操作,在问题变得比相同数据源上更加临时的计算更复杂时,流查询更可能保留写入和读取的简单性。
前面例子中,对聚合操作的使用可以归结为3个部分:
- 创建Stream:通过stream()方法,取得集合对象的数据集。
- Intermediate:通过一系列中间(Intermediate)方法,对数据集进行过滤、检索等数据集的再次处理。如上例中,使用filter()方法来对数据集进行过滤。
- Terminal通过最终(terminal)方法完成对数据集中元素的处理。如上例中,使用forEach()完成对过滤后元素的打印。
在一次聚合操作中,可以有多个Intermediate,但是有且只有一个Terminal。也就是说,在对一个Stream可以进行多次转换操作,并不是每次都对Stream的每个元素执行转换。并不像for循环中,循环N次,其时间复杂度就是N。转换操作是lazy(惰性求值)的,只有在Terminal操作执行时,才会一次性执行。可以这么认为,Stream 里有个操作函数的集合,每次转换操作就是把转换函数放入这个集合中,在 Terminal 操作的时候循环 Stream 对应的集合,然后对每个元素执行所有的函数。3个部分,具体有哪些可以参考这里 java.util.stream 库简介
所以为什么可以在stream中如何引入lambda表达式的?可以看到下方的源代码,Stream正是引用了我们上面说到的Consumer,Function等函数作为参数传递。而这些函数是支持lambda表达式的。
这里如何理解Sream中的map函数?
我们对上面的student调用如下。
list.stream().map(student -> student.getHeight()).forEach(System.out::println);
最终会打印两个学生的height值。 所以可以看到map完成了从student对象到student.getHeight()的转变。
下方是Stream的抽象接口和实现。可以看到的是Stream的map正是我们上面所说的 Intermediate操作。因为返回的还是一个Stream,只是做了一个从输入T(泛型)到R(泛型)的流的转变。至于理解ReferncePipeline可以参考这里java8 Stream Pipelines 浅析
//抽象,来自Stream
Stream map(Function mapper);
//实现,来自Stream实现类ReferencePipeline
public final Stream map(Function mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink opWrapSink(int flags, Sink sink) {
return new Sink.ChainedReference(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
通过Stream来体会下函数式编程的特征???
函数式程序更加易于推断, 因为它们是确定性(deterministic )的 。对于一个特定的输入总会给出 相同的输出。 在许多情况下 , 你都可以证明程序是 正确 的, 而不是在大量的测试 后仍然不确定程序是 否会在意外的情况下 出错。
函数式程序更加易于测试。 因为没有副作用, 所以你不需要那些经常用于在 测试里隔离程序及外界的 mock。
函数式程序更加模块化, 因为它们是由只有输入和输出的函数构建的。 我们 不必处理副作用, 不必捕获异常, 不必处理上下文变化 , 不必共享变化的状态,也没有并发的修改。
函数式编程让复合和重新复合更加简单。 为了编写函数式程序, 你需要开始 编写各种必要的基础函数, 并把它们复合为更高级别的函数, 重复这个过程 直到你拥有了一个与你打算构建的程序一致的函数。 因为所有的函数都是引用透明的,它们无须修改便可以为其他程序所重用。
无副作用:尽管流在表面上可能类似于集合(您可以认为二者都包含数据),但事实上,它们完全不同。集合是一种数据结构;它的主要关注点是在内存中组织数据,而且集合会在一段时间内持久存在。集合通常可用作流管道的来源或目标,但流的关注点是计算,而不是数据。数据来自其他任何地方(集合、数组、生成器函数或 I/O 通道),而且可通过一个计算步骤管道处理来生成结果或副作用,在此刻,流已经完成了。流没有为它们处理的元素提供存储空间,而且流的生命周期更像一个时间点 — 调用终止操作。不同于集合,流也可以是无限的;相应地,一些操作(limit()、findFirst())是短路,而且可在无限流上运行有限的计算。
集合和流在执行操作的方式上也不同。集合上的操作是急切和突变性的;在List上调用remove()方法时,调用返回后,您知道列表状态会发生改变,以反映指定元素的删除。对于流,只有终止操作是急切的;其他操作都是惰性的。流操作表示其输入(也是流)上的功能转换,而不是数据集上的突变性操作(就如上方的例子,过滤一个流会生成一个新流,新流的元素是输入流的子集,但没有从来源删除任何元素)。更多关于集合和流的区别参考stackoverflow我应返回集合还是流?
更多参考:
java.util.stream的包文档:查看该库的工作原理概述。
如果需要了解rxjava可以参考下面的文章。
ReactiveX RxJava wiki
给 Android 开发者的 RxJava 详解
函数式编程的优势和编程建议
函数式编程的优势
通过比较可以发现,函数式编程语言有以下几个特点:(参考自Java函数式编程)
1、并行。在函数式编程中,程序员无需对程序修改,程序就可以并发运行。程序运行期间,不会产生死锁现象。原因是通过函数式编程所得到的程序,在程序中不会出现某一数据被同时修改两次及以上的情况,同样的,两个不同的线程就更不用说了。由于函数式编程有这样的优点,导致了程序员完全不用花费精力去考虑增加某个线程带来的并发问题。
在函数编程语言中,编译器会分析代码,辨认出潜在耗时的创建字符串s1和s2的函数,然后将他们并行的运行。这样的做法,是程序员在使用普通的命令式程序语言时不可能做到的。而使用函数式程序语言可以自动的找出那些可以并发执行的函数。
2、单元测试。在函数式编程中,由于程序中的每一个符号都是final后的,所以这样的函数不会产生副作用。这就导致了在某个地方产生修改,同时不会有函数修改过在自身范围之外的变量或者状态被另外的函数所使用。这就导致了函数的返回结果只是返回值。只有函数自身的参数才会影响函数的返回值,所以在编程的时候,对程序中的每个函数而言,程序员只需在控制它们的参数,而不用在意函数自己点顺序以及函数外部变量和状态就能正确的编程。与函数式编程相比,命令式编程就没有这样的优势了,在检查函数的返回值的同时程序员还必须检查函数是否影响到了函数的外部状态和变量。
3、没有额外作用。副作用是指的是函数内部与外部互动。比如,函数在自身内部可以对函数以外的其他变量进行修改,这样就会产生其他结果。在函数式编程中,想要达到这样的目的就必须让函数自身要保持独立。在函数式程序语言中,所有的功能的结果就是一个返回值,不存在其他的行为,包括对外部变量的修改。
4、不修改状态。在函数式编程中,程序语言在使用中是会不修改变量的,它的一个特性可以使得函数式编程语言区别于其他的程序语言。在其他类型的语言中,变量是用来保存状态的。由于函数式编程不修改变量,导致了这些状态不能存在于变量中。那么,函数式编程语言保存状态的方法是使用参数来保存,递归方法是最好的例子。由于采用了递归方法,函数式编程语言在运行速度上相对于其他语言较慢,所以,速度不够快是函数式编程语言长期不能广泛使用的主要原因。
5、引用透明。在函数式编程中,引用透明指的是运行函数的时候,函数的没一个步骤都不会不牵连到函数的外部变量或状态,而是只依赖于函数输入的参数,相同的参数输入总会得到相同的函数返回值。而在其他类型的语言中,函数的返回值不仅仅与函数的参数传入有关,也与当前的系统状态有关。在不同的系统状态的情况下,函数的返回值不同。
6、代码部署热。在以前,假如想在Windows上安装更新,安装之后重启计算机是必须进行的步骤,可能还不只一次的重启。即使是仅仅安装了一个小的软件也不能免于重启的步骤。一些特殊的系统,比如电信系统,这样的系统必须保证任何时间都在运行。因为如果在系统更新时紧急拨号失效,就可能造成很大的损失。最理想的情况是在完全不停止系统任何组件的情况下,达到更新相关的代码的目的。这样的想法在命令式编程中是不可能的。对函数式的程序,所有的状态即传递给函数的参数都被保存在了堆栈上,这使的热部署轻而易举。实际上,所有我们需要做的就是对工作中的代码和新版本的代码做一个差异比较,然后部署新代码。其他的工作将由一个语言工具自动完成。
函数式编程建议
函数式编程并不会比 命令式编程更难,只是不同而己。 你可以用这两个范式来解决相同的问题,但是从一个转换到另 一个时可能效率较低。 学习函数式编程就像是学 习 一 门外语 。 正如你想着 一 门语言并翻译到另 一 门语言不可能效率较 高那样, 你也不能想着命令式 并把代码翻译为函数 式 。 井且正如你需要学会 用新的语言来思 考那样, 你也需要学会函数式 地思考 。
参考文章
The Implementation of Functional Programming Languages
Functional Programming for Java Developers
Java函数式编程
Java 8函数式编程
函数式编程思维
Java8新特性学习-函数式编程(Stream/Function/Optional/Consumer)
用Java8来进行函数式编程