最近瞧了一篇文章,我做了六百万字得歌词分析,告诉你中国rapper都在唱什么.立马想到也来分析分析我姿看看。最后的4万字歌词的词云让我看到一条箴言是:
我们不要爱情
幸福是相信自己
哈哈哈,看来单身狗是要注孤生了
言归正转,Let‘s go!
更新了一版简单点的教程soda学python-原来周杰伦最喜欢用四个字是 谢谢大家的支持!

- 1.任务目标
- 2.爬取歌词
- 2.1观察
- 2.2 代码
- 2.2.1 爬取歌词链接
- 2.2.2 爬取歌词
-2.2.3 清洗歌词
-2.2.4 歌词文本分词
- 3.歌词词云分析
1.任务目标
- 爬取孙燕姿的所有中文歌词
- 对孙燕姿的中文歌词进行分析制作词云
2. 爬取歌词
因为没找到现成的歌词包,因此我选择的是自己在歌词千寻网上爬,歌词千寻对于爬虫来说还是非常友好简单的,基本和soda学python---简单爬糗百过程一致。
2.1 观察
首先,让进入孙燕姿的主页歌词千寻-孙燕姿
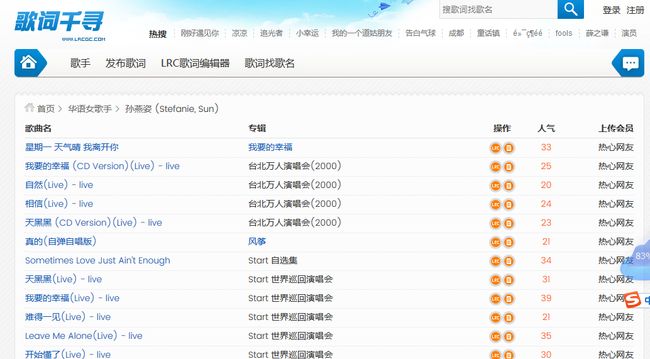
接着,查看条目。我们发现页面表格中的主要内容都在tr标签的td标签下,前两个td标签中分别包含了歌曲名,专辑名。
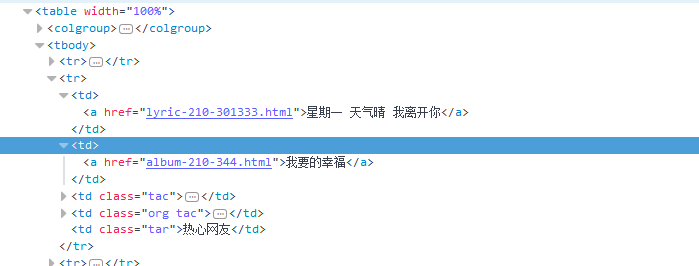
其中第一个标签中还有 链接信息,经测试“ http://www.lrcgc.com/”+链接部分即可跳转到歌词界面
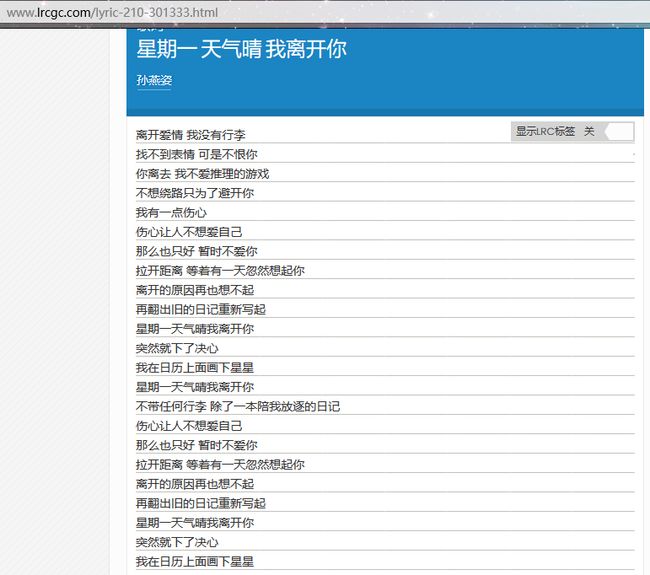
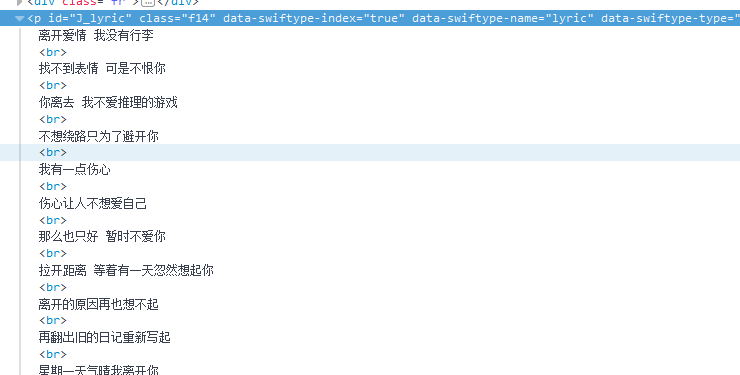
观察歌词界面元素,发现歌词元素在 p class=“f4” 标签下
因此我们爬取思路如下:
1.通过歌手主页,爬取到所有歌词链接
2.通过歌词链接,爬取歌词
3.为了便于清洁数据,我们将歌曲名与专辑名一起爬取
2.2 代码
2.2.1 爬取歌词链接
这部分的目标是爬取所有歌曲的链接并存储。该部分基本和soda学python---简单爬糗百过程一致。如有疑问看参见糗百篇。主要代码块解释如下
- 导入相关库
import requests
from bs4 import BeautifulSoup
import codecs
import warnings
import numpy as np
import pandas as pd
warnings.filterwarnings('ignore')
- 主代码
def main():
url_list=[]
for i in np.arange(1,13).astype('str'):
urli='http://www.lrcgc.com/songlist-210-'+i+'.html'
url_list.append(urli)
num=0
sun=pd.DataFrame(np.zeros((300,4)),columns=['歌名','专辑名','链接','歌词'])
for url in url_list:
html=download_page(url)
sun,num=parsel_lyrics(html,sun,num)
sun.to_csv('sunyanzi.csv')
return sun
因为涉及到翻页问题,我们需要知道下一页的链接。观察
第一页:http://www.lrcgc.com/songlist-210-1.html
第二页:http://www.lrcgc.com/songlist-210-2.html
我们发现歌手主页各页的链接只需更改http://www.lrcgc.com/songlist-210-1.html中的黑体部分位对应页码即可。因此我们先通过一个循环得到url_list,共12个链接。
第二部分调用预先写好的源代码下载函数dowload_page()及解析函数parsel_lyrics()爬取所有歌曲的歌名,专辑名及歌词链接并存储。
- 网页源代码下载
def download_page(url):
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0'}
html=requests.get(url,headers=header).content
return html
- 网页源代码解析
找到tr,td标签找到歌名,专辑名及歌词链接
def parsel_lyrics(html,sun,num):
soup=BeautifulSoup(html)
song_list=soup.find_all('tr')[1:]
for song in song_list:
sun['歌名'].loc[num]=song.find_all('td')[0].getText()
sun['专辑名'].loc[num]=song.find_all('td')[1].getText()
sun['链接'].loc[num]='http://www.lrcgc.com/'+song.find_all('td')[0].find('a')['href']
num+=1
return sun,num
- 完整代码
import requests
from bs4 import BeautifulSoup
import codecs
import warnings
import numpy as np
import pandas as pd
warnings.filterwarnings('ignore')
def download_page(url):
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0'}
html=requests.get(url,headers=header).content
return html
def parsel_lyrics(html,sun,num):
soup=BeautifulSoup(html)
song_list=soup.find_all('tr')[1:]
for song in song_list:
sun['歌名'].loc[num]=song.find_all('td')[0].getText()
sun['专辑名'].loc[num]=song.find_all('td')[1].getText()
sun['链接'].loc[num]='http://www.lrcgc.com/'+song.find_all('td')[0].find('a')['href']
num+=1
return sun,num
def main():
url_list=[]
num=0
sun=pd.DataFrame(np.zeros((300,4)),columns=['歌名','专辑名','链接','歌词'])
for i in np.arange(1,13).astype('str'):
urli='http://www.lrcgc.com/songlist-210-'+i+'.html'
url_list.append(urli)
for url in url_list:
html=download_page(url)
sun,num=parsel_lyrics(html,sun,num)
sun.to_csv('sunyanzi.csv')
return sun
if __name__=='__main__':
main()
- 结果
得到一个sunyanzi.csv的文件及DataFrame格式的变量sun
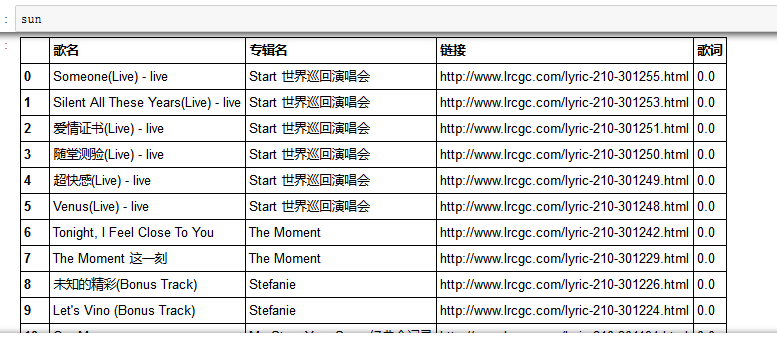
2.2.2 爬取歌词
2.2.2.1 清洗链接
我们现在已经有了一个总计包含224首歌曲相关信息的表格,在直接根据表格中的链接爬取歌词前,我们先对这个表格进行简单的清洗。因为条目较少,该部分我直接使用excel来处理
-
查重:
先后Excel中"数据选项卡"中的"删除重复项"先后根据链接 歌名查重
利用歌名栏,查重结果如下
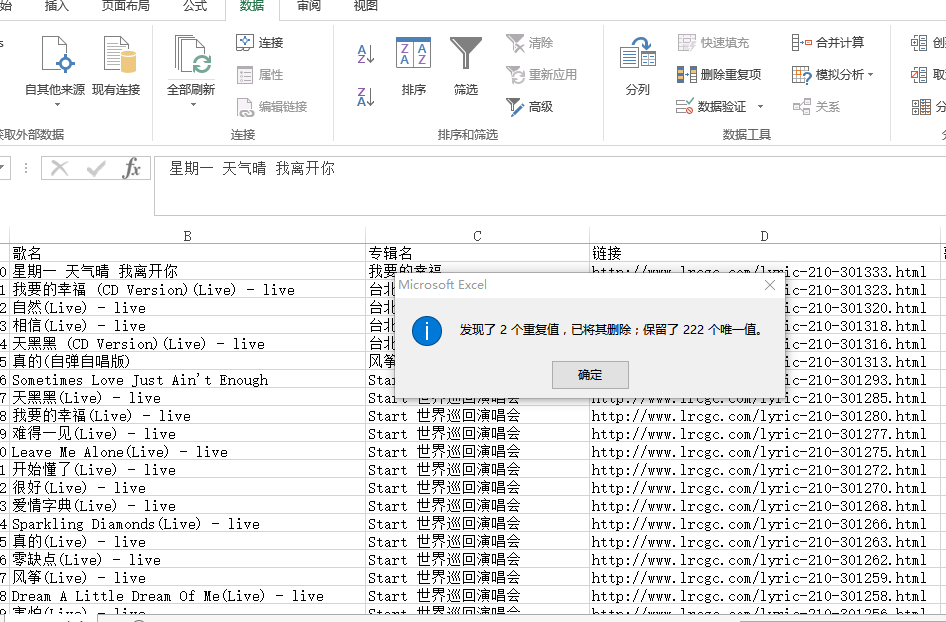 查重 .png
查重 .png -
查错
对专辑栏进行排序,发现了一些从来没听过的专辑比如乘着风,作为铁粉万分震惊,百度后得知此乃盗版专辑浑水摸鱼,果断删除
 查错.png
查错.png 手工
当然这样的清楚还是远远不够的,因为条目不多我还是老老实实根据歌名手工来找,再老老实实掏出网易云的专辑列表,挨着挨着一张一张专辑的核对。。这都是体力活,不再赘述(这活干完,感觉可以参加姿吧的知识)最后总计得到146条曲目,存为sun_2.xlsx
2.2.2.2 下载歌词
根据之前得到的歌曲链接,来下载歌词,并存储到sun_2.xlsx中的歌词列。这个爬虫和前面类似。
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
def download_page(url): # 下载源代码
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0'}
html=requests.get(url,headers=header).content
return html
def parsel_ly(html,lyrics_list): #解析源代码
soup=BeautifulSoup(html)
lyrics=soup.find('p',{'class':'f14'}).getText()
lyrics_list.append(lyrics)
return lyrics_list
def main():
lyrics_list=[]
information=pd.read_excel('sun_2.xlsx')
for url in information['链接'] :
HTML=download_page(url)
lyrics_list=parsel_ly(HTML,lyrics_list)
#将下载歌词存储到sun_2.xlsx的歌词列
information=pd.read_excel('sun_2.xlsx')
information['歌词']=lyrics_list
information.to_excel('sun_2.xlsx')
if __name__ == '__main__':
data=main()
结果:

2.2.3 清洗歌词
观察发现,爬取的结果中还包含了一些非中文歌词部分,利用正则表达式来进行清理,并将最终结果存储到sun_3.xlsx中
import numpy as np
import pandas as pd
import re
information=pd.read_excel('sun_2.xlsx')
lys=information['歌词']
lyric_after=[]
# 正则表达式,清理文本中带有作词,作曲等无关词部分
for ly in lys:
#pat=re.compile(r'\].*?\s:.*?\[')
pat=re.compile(r'\作曲.*?\[') #匹配]作曲:....[
ly=pat.sub('',ly)
pat=re.compile(r'\作词.*?\[')
ly=pat.sub('',ly)
pat=re.compile(r'孙燕姿')
ly=pat.sub('',ly)
pat=re.compile(r'\制作.*?\[')
ly=pat.sub('',ly)
pat=re.compile(r'\歌词.*?\[')
ly=pat.sub('',ly)
pat=re.compile(r'[^\u4e00-\u9fa5]') #删除非中文字符
ly=pat.sub('',ly)
lyric_after.append(ly)
information['歌词']=lyric_after
i=0
for ly in information['歌词']: #清理掉歌词长度小于30的无效歌词
if len(ly)<30:
information=information.drop(i,axis=0)
i+=1
information.to_excel('sun_3.xlsx') #存储
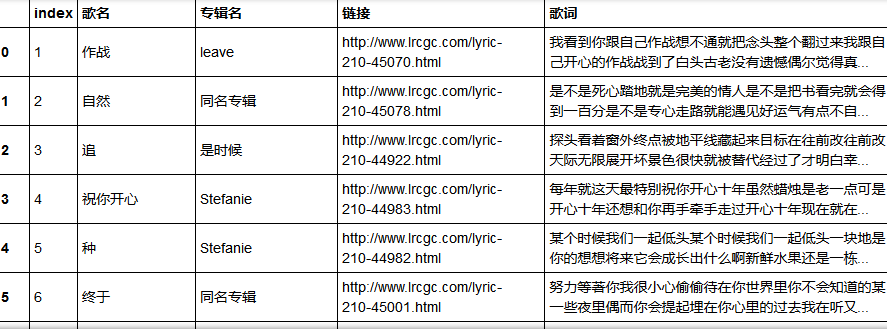
最后结果如图,已较好的清洗出了歌词文本部分,但为了更准确,可手动打开excel文件再进行检查,最后总计剩余129首歌,共计38172字。
2.2.4 歌词文本分词
使用jieba包对已经处理好的文本进行分析处理,并过滤掉了单字。
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import jieba
#导入歌词数据
inf=pd.read_excel('sun_3.xlsx')
text=''.join(inf['歌词'])
#结巴分词
segs=jieba.cut(text,True)
#过滤点单个字
word_list=[]
for seg in segs:
if len(seg)>1:
word_list.append(seg)
#存储
word=pd.DataFrame({'word':word_list})
word.to_excel('sun_word.xlsx')
对结果做简单的词频分析,可以看出我们 没有等词的频率较高

3.歌词词云分析
这部分可以使用python自带的wordcloud包,这里我偷懒直接用了一个在线网站WordArt
- 点击import words,载入分好词的文本
- 在分别选择shape,font进行定制,注意自带字体无法识别中文,需要自己加载字体,这里我选择的是simsun.tff
- 点击visualize 出图啦~
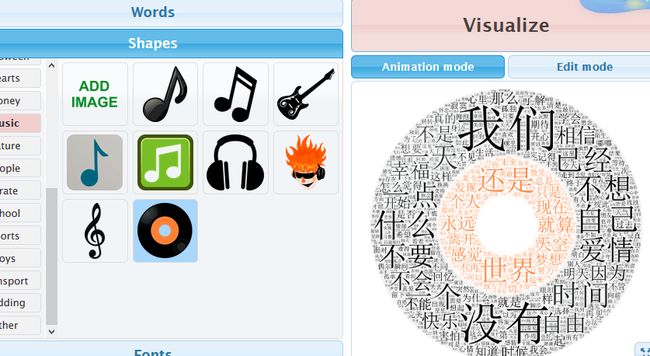
附:python代码,具体可参见wordcloud教程
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
cut_text=' '.join(word_list)
color_mask = np.array(Image.open( "图片2.png"))
wc = WordCloud(font_path='F:\Jupter\孙燕姿song\simsun.ttc',background_color="white", max_words=2000, mask=color_mask)
wc.generate(cut_text)
wc.to_file("sun.png")
# show
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()

总结
第一次做这么完整的项目,出图的一刻还是很开心的!
还有很多不完善的地方,希望再接再厉,继续努力!