Textbook:
《计算机组成与设计——硬件/软件接口》 HI
《计算机体系结构——量化研究方法》 QR
Branch Prediction
对于下面的指令:
i1: r1 := r2 / r3 i2: r2 := r1 / r3 i3: r3 := r2 - r3 i4: beq r3, 100 //if r3==0 then GOTO 100
前面i1, i2, i3都是有依赖的,计算起来就很慢。如果在i4的分支语句中使用了branch prediction,就可以不用等r3算出来,直接提前prefetch target instruction了。这在循环中会很有用。
分支预测要做到下面几点:
- Determine whether it is a branch instruction
- Predict whether it will be taken or not
- Predict the target address if taken
那么如何实现branch prediction呢?有下面几种方法:
1. A branch will do exactly what it did last time
就是搞一个hash table,instruction address的least significant bit作为index,记录该指令有没有跳转。每次新分支指令执行之前,去hash table查找一下对应的value,作为预测结果。
但是这个方法比较死板嘛...就是直接用上一次的结果作为本次的prediction。对于10101010...这样的pattern就很不行了
2. Change the prediction after two mispredictions
这次改成了:如果有连续两次预测错了,就改变一下预测值。否则不变。这个的具体实现可以通过一个2-bit saturation counter来完成
另外也可以扩展到N-bit saturation counter
3. Correlation Branch Predictor
有时候一个程序里,两个branch的行为是有相关性的。所以对于相关的两个branch A和B,比如对于B就可以搞两个predictor,根据branch A的执行情况来决定对branch B到底用哪个prediction:
- One bit predicts the branch if the last branch is taken
- One bit predicts the branch if the last branch is not taken
prediction的值根据历史执行情况更新(有点类似1)
4. Tournament Predictor
PPT P10 / QR ch3.3.1
它的原理就是把Local predictor(只看当前指令的历史结果。)和Global predictor(所有指令的历史结果糊在一起)结合起来,然后再搞个predictor-predictor来决定到底用前面的哪个predictor。
4k-entry 2 predictor-predictor
Use a 2 bit saturation counter to select between two predictors
Based on local information of the branch
A local predictor
1024-entry 10-bit predictor, keeps track of 10 most recent outcomes
The entry then selects from a 3-bit saturation counter
4k-entry global predictor
indexed by the history of 12 branches,
Each entry is a standard 2-bit predictor
Hardware Speculation
PPT P13 / QR ch3.6 / HI P216
推测(speculation) 是一种允许编译器或处理器猜测指令结果,以消除执行其他指令对该结果依赖的方法。例如,我们可以推测分支指令的结果,这样分支后的其他指令就可以提前执行了。另一个例子是假设load 指令前有一条store 指令,我们可以推测它们不对同一存储器地址进行访问,这样就可以把load 指令提到store 指令前执行。
但是推测的问题在于可能会猜错,因此when the prediction is wrong, incorrectly executed instruction must be “erased”。但是前面说过,有些奇怪的指令可能不太容易直接被erase,所以还需要硬件上支持一个恢复机制。
前面提到过通过旁路可以在指令在没有完全结束前,就读到它计算阶段算出的结果。然后为了消除一些依赖关系带来的stall还引入了Tomasulo算法。但在乱序执行的情况下,此时我们还不知道这个指令是不是该被执行的(有可能后来jump了一下,就白执行了),因此需要有些机制保证可以recover不需要的指令。
recover的关键思想是允许指令乱序执行,但必须顺序提交。我们设置一个硬件缓冲区(重排序缓冲区),用于保存已经执行完成但还没提交的指令结果(holds the results of instructions that have finished execution but not yet committed)。它包含如下字段:

- Instruction Type:type of instruction
- Destination Field:which Register to be modified
- Value Field:produced value
- Ready Field:whether ready to commit?
我们把这个Reorder Buffer加到Tomasulo算法里看一下:
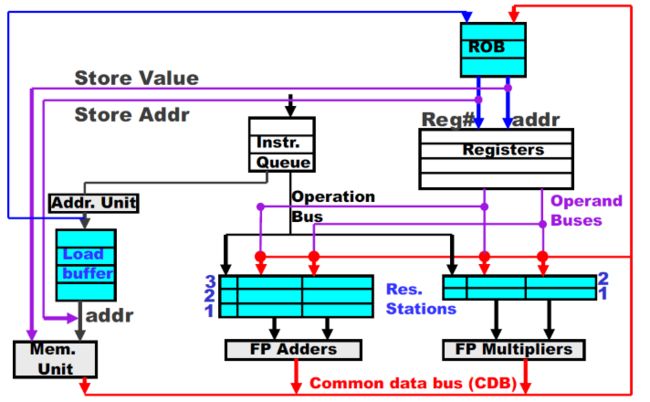
- 在Instruction Queue中,issued instruction会同时进入Reorder Buffer和Reservation Station
- Common data bus产生出的结果会先写入Reorder Buffer,到了commit时再真正写入寄存器。Store memory的操作也一样
- Reorder buffer可以看作对register和memory的一层写入缓冲区。这样就允许incorrect的指令进行recover了
指令的执行步骤:PPT P15
...