前言
昨天在写完 入门级爬虫之后 ,马上就迫不及待的着手开始写 B站的图片爬虫了,真的很喜欢这个破站呢 (〜 ̄△ ̄)〜
这里不涉及到 Python 爬虫的高级技巧,没有使用框架,没有考虑反爬机制,没有使用异步IO技术,因为这些,我都不会!
分析目标
我们选定 B站的 动画区 进行测试,打开后我们发现有好多好多图....
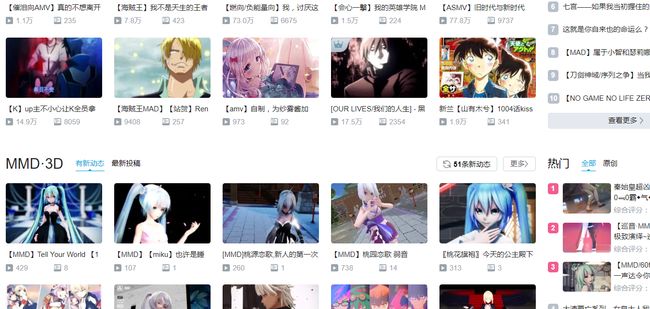
但当我们使用 F12 查看这些图片的时候,发现并没有图片的地址...
这就是目前大多网站使用的 Ajax 技术动态加载数据的锅,可遇到这种情况这么办呢?别急别急,我们知道这些图片的地址一定是需要加载的,而目前常见WEB传输数据的基本就是方式 XML 和 Json (其实是我就知道这两种...),那好我们去看看请求的 XML 和 Json 文件。
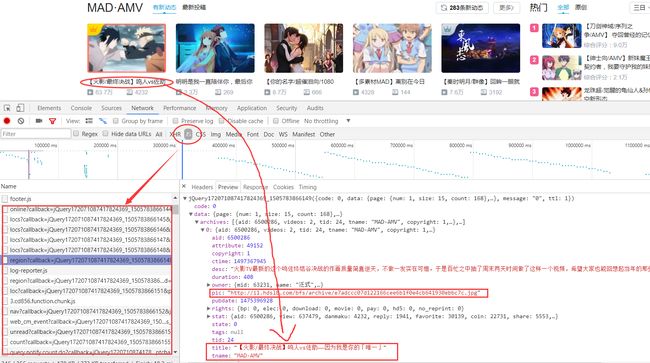
以下省略查找过程....
我们发现 B站的图片地址是保存在 Json 里面的,ok,我们保存好这个 json 地址:
https://api.bilibili.com/x/web-interface/dynamic/region?callback=jQuery172071087417824369_1505783866149&jsonp=jsonp&ps=15&rid=24&_=1505783866453
这个是 MAD·AMV 最新动态的 Json 文件,利用上面相同的方法,我们找到 3D区、短片·配音区、综合区 以及 右边排行部分 的相应 json 地址。
找到 Json 数据后,我们需要开始分析如何才能从中拿到 图片地址了
好在 Chrome 浏览器提供了一个 Preview 功能,自动帮我们整理好 数据,如下
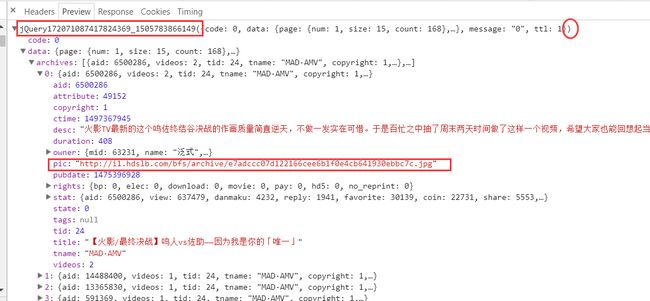
这样就很清晰啦,我们只需要一层层解析拿到 pic 即可。于是我们这样写:
json_url = 'https://api.bilibili.com/x/web-interface/dynamic/region?callback=jQuery172071087417824369_1505783866149&jsonp=jsonp&ps=15&rid=24&_=1505783866453'
json = requests.get(json_url).json()
print (json)
我们利用 requests 内置的 json 解码器,很不幸,报错:
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
它提示说:解码 Json 数据的时候出了问题,可能是在 第一行 第一列,咦?好奇怪,刚才不是用浏览器看过结构了吗,没毛病啊,怎么还在报错:Σ(  ̄□ ̄||)
别急别急,我们先看看原始的 Json 数据长啥样?用 浏览器打开上面的 json 链接就可以了。

(/TДT)/ 前面的那些字母是干嘛的呀,为什么还有括号啊!
所以我们知道了 Json 解析错误 的原因啦:后面在处理的时候把前面的这部分删掉就好啦,另外我们也发现了 archives 这个关键字,我们在上一张图看见过的哦,有印象吗?啊,你说没有呀,没关系,这里你只需要记着它是一个 List 的数据类型就好了呀!
开码开码
先看看 解析部分怎么写:
- 获取 Json 数据
- 解析 Json 数据,并保存其中的 所有的图片链接
- 注意去重
#coding:utf-8
__author__ = 'Lanc4r'
import json
import requests
import re
class BiliBiliSpider(object):
def __init__(self):
self._images = []
self._oldImages = [] # 保存已经获取过的 图片地址
def _getImages(self, url):
content = requests.get(url).text
dic = json.loads(re.match(r'^([a-zA-Z0-9_(]+)(.*)(\))$', content).group(2))
data = dic['data']
# 判断是 动态区 和 还是 评论区的数据
if 'archives' in data:
final = data['archives']
else:
final = data
for i in range(len(final)):
image = final[i]['pic']
if image not in self._oldImages: # 去重
self._images.append(image)
self._oldImages.append(image)
def getResult(self, url):
self._getImages(url)
temp = self._images
self._images = []
return temp
OK,接下来写下载器:
- 获取需要下载的 图片地址
- 进行下载
- 我这里是用数字作为图片的名字保存起来的,数字用一个 count.txt 文件保存,为了好看一点吧...
#coding:utf-8
__author__ = 'Lanc4r'
import requests
class BiliBiliDownloader(object):
def __init__(self):
self._images = []
def addNewImages(self, images):
for image in images:
self._images.append(image)
# 获取后缀名
def getFinName(self, url):
if url[-4:].find('.') > -1:
fin = url[-4:]
else:
fin = url[-5:]
return fin
def imageDownload(self):
with open('count.txt', 'rb') as f:
temp = int(f.read().decode('utf-8'))
for url in self._images:
name = 'images/' + str(temp) + self.getFinName(url)
print ('Downloading {}...'.format(name))
r = requests.get(url)
with open(name, 'wb') as f:
f.write(r.content)
temp += 1
self._images = []
with open('count.txt', 'wb') as f:
f.write(str(temp).encode('utf-8'))
最后是调度器:
为了防止被当作是 恶意访问 从而被封 IP,这里我们选择牺牲时间,取巧使用 sleep(x) ,让其等待一段时间之后再发出请求。
#coding:utf-8
__author__ 'Lanc4r'
from BiliBiliSpider import BiliBiliSpider
from BiliBiliDownloader import BiliBiliDownloader
import time
class BiliBiliMain(object):
def __init__(self):
self._spider = BiliBiliSpider()
self.downloader = BiliBiliDownloader()
def Crawl(self, url):
images = self._spider.getResult(url)
self.downloader.addNewImages(images)
self.downloader.imageDownload()
if __name__ == '__main__':
# 添加相应位置的 json 文件
json_url_MAD = 'https://xxx...'
json_url_MAD_rank = 'https://xxx...'
...
json_url_list = []
json_url_list.append(json_url_MAD)
json_url_list.append(...)
...
bilibili = BiliBiliMain()
# 设置一个标志位,循环爬取多少次之后自动退出。
flag = 1
while True:
for url in json_url_list:
bilibili.Crawl(url)
time.sleep(30) # 防止被当作是恶意请求。。。
time.sleep(100) # 防止被当作是恶意请求。。。
flag += 1
if flag > 15:
break
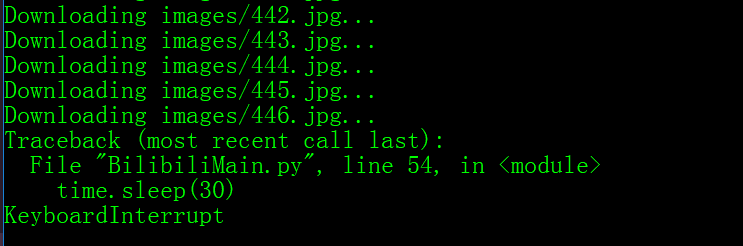
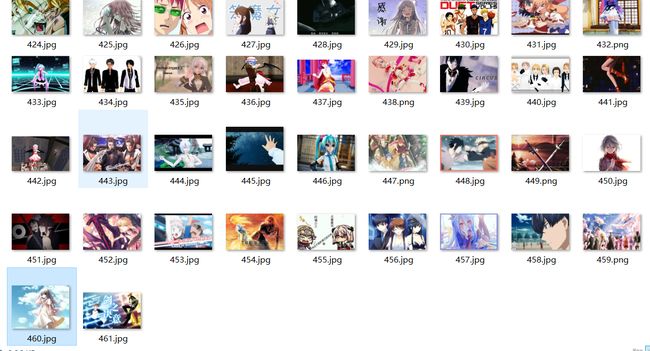
运行效果:
总结:
你可能会问我,呀,你这个,根本没有代理、没有混淆IP防止反爬、也没有模拟 Ajax 请求动态抓取云云~
那我可以很负责的告诉你,你!走错地方了!你要找的技术贴出门右拐!( ̄へ ̄)
关于取巧
我们恰巧使用的是 B站的 Ajax 技术,只要哪个视频有了最新评论(或者是一下其它的条件),就会使用 Ajax 将最新的数据取出来。就像下面这样:
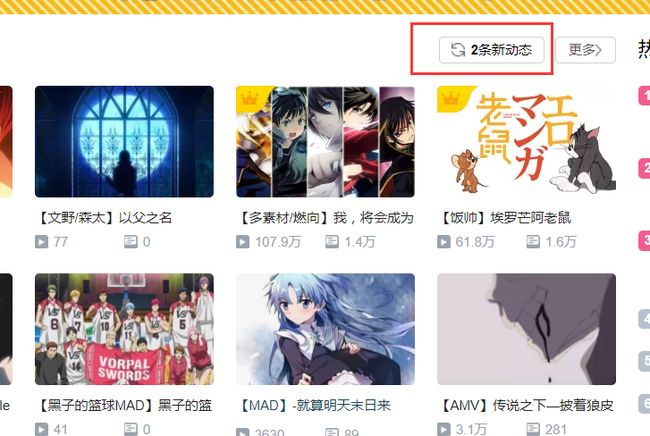
所以可能在访问人数多的时候,更新越快,越有可能获得更多不同的图片啦!
之后你就可以在吃饭的时候,把它挂起,然后吃饭回来就会发现有好多好多的图片!(=・ω・=)
关于以后
之后会陆续的更新自己爬虫的爬坑过程,希望能够找到小伙伴一起学习呀!