import urlparse
import urllib2
import re
import Queue
#页面下载
def page_download(url,num_retry=2,user_agent='zhxfei',proxy=None):
#print 'downloading ' , url
headers = {'User-agent':user_agent}
request = urllib2.Request(url,headers = headers)
opener = urllib2.build_opener()
if proxy:
proxy_params = {urlparse(url).scheme:proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
html = urllib2.urlopen(request).read() #try : download the page
except urllib2.URLError as e: #except :
print 'Download error!' , e.reason #URLError
html = None
if num_retry > 0: # retry download when time>0
if hasattr(e, 'code') and 500 <=e.code <=600:
return page_download(url,num_retry-1)
if html is None:
print '%s Download failed' % url
else:
print '%s has Download' % url
return html
#使用正则表达式匹配出页面中的链接
def get_links_by_html(html):
webpage_regex = re.compile(']+href=["\'](.*?)["\']', re.IGNORECASE)
return webpage_regex.findall(html)
#判断抓取的链接和入口页面是否为同站
def same_site(url1,url2):
return urlparse.urlparse(url1).netloc == urlparse.urlparse(url2).netloc
def link_crawler(seed_url,link_regex,max_depth=-1):
crawl_link_queue = Queue.deque([seed_url])
seen = {seed_url:0} # seen means page had download
depth = 0
while crawl_link_queue:
url = crawl_link_queue.pop()
depth = seen.get(url)
if seen.get(url) > max_depth:
continue
links = []
html = page_download(url)
links.extend(urlparse.urljoin(seed_url, x) for x in get_links_by_html(html) if re.match(link_regex, x))
for link in links:
if link not in seen:
seen[link]= depth + 1
if same_site(link, seed_url):
crawl_link_queue.append(link)
#print seen.values()
print '----All Done----' , len(seen)
return seen
if __name__ == '__main__':
all_links = link_crawler('http://www.zhxfei.com',r'/.*',max_depth=1)
运行结果:
http://www.zhxfei.com/archives has Download
http://www.zhxfei.com/2016/08/04/lvs/ has Download
...
...
http://www.zhxfei.com/2016/07/22/app-store-审核-IPv6-Olny/#more has Download
http://www.zhxfei.com/archives has Download
http://www.zhxfei.com/2016/07/22/HDFS/#comments has Download
----All Done----
#!/usr/bin/env python
# _*_encoding:utf-8 _*_
# description: this modlue is load crawler By SITEMAP
import re
from download import page_download
def load_crawler(url):
#download the sitemap
sitemap = page_download(url)
links = re.findall('(.*?)',sitemap)
for link in links:
page_download(link)
if link == links[-1]:
print 'All links has Done'
# print links
load_crawler('http://example.webscraping.com/sitemap.xml')
def link_crawler(seed_url,link_regex,max_depth=-1,scrape_callback=None):
...
html = page_download(url) #这行和上面一样
if scrape_callback:
scrape_callback(url,html)
links.extend(urlparse.urljoin(seed_url, x) for x in get_links_by_html(html) if re.match(link_regex, x)) #这行和上面一样
...
zhxfei@zhxfei-HP-ENVY-15-Notebook-PC:~/桌面/py_tran$ python crawler.py
http://example.webscraping.com has Download
http://example.webscraping.com/index/1 has Download # /index 在__call__中的/view 所以不会进行数据提取
http://example.webscraping.com/index/2 has Download
http://example.webscraping.com/index/0 has Download
http://example.webscraping.com/view/Barbados-20 has Download
http://example.webscraping.com/view/Bangladesh-19 has Download
http://example.webscraping.com/view/Bahrain-18 has Download
...
...
http://example.webscraping.com/view/Albania-3 has Download
http://example.webscraping.com/view/Aland-Islands-2 has Download
http://example.webscraping.com/view/Afghanistan-1 has Download
----All Done---- 35
zhxfei@zhxfei-HP-ENVY-15-Notebook-PC:~/桌面/py_tran$ ls
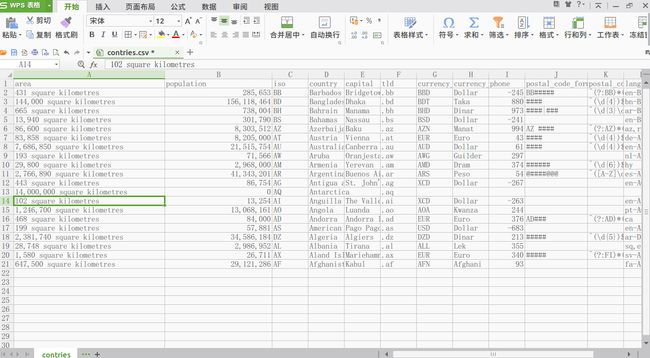
contries.csv crawler.py
打开这个csv,就可以看到数据都保存了:
完整代码在这里:
#!/usr/bin/env python
# _*_encoding:utf-8 _*_
import urlparse
import urllib2
import re
import time
import Queue
import lxml.html
import csv
class ScrapeCallback():
def __init__(self):
self.writer = csv.writer(open('contries.csv','w+'))
self.rows_name = ('area','population','iso','country','capital','tld','currency_code','currency_name','phone','postal_code_format','postal_code_regex','languages','neighbours')
self.writer.writerow(self.rows_name)
def __call__(self,url,html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
rows = []
for row in self.rows_name:
rows.append(tree.cssselect('#places_{}__row > td.w2p_fw'.format(row))[0].text_content())
self.writer.writerow(rows)
def page_download(url,num_retry=2,user_agent='zhxfei',proxy=None):
#print 'downloading ' , url
headers = {'User-agent':user_agent}
request = urllib2.Request(url,headers = headers)
opener = urllib2.build_opener()
if proxy:
proxy_params = {urlparse(url).scheme:proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
html = urllib2.urlopen(request).read() #try : download the page
except urllib2.URLError as e: #except :
print 'Download error!' , e.reason #URLError
html = None
if num_retry > 0: # retry download when time>0
if hasattr(e, 'code') and 500 <=e.code <=600:
return page_download(url,num_retry-1)
if html is None:
print '%s Download failed' % url
else:
print '%s has Download' % url
return html
def same_site(url1,url2):
return urlparse.urlparse(url1).netloc == urlparse.urlparse(url2).netloc
def get_links_by_html(html):
webpage_regex = re.compile(']+href=["\'](.*?)["\']', re.IGNORECASE) #理解正则表达式
return webpage_regex.findall(html)
def link_crawler(seed_url,link_regex,max_depth=-1,scarape_callback=ScrapeCallback()):
crawl_link_queue = Queue.deque([seed_url])
# seen contain page had find and it's depth,example first time:{'seed_page_url_find','depth'}
seen = {seed_url:0}
depth = 0
while crawl_link_queue:
url = crawl_link_queue.pop()
depth = seen.get(url)
if seen.get(url) > max_depth:
continue
links = []
html = page_download(url)
links.extend(urlparse.urljoin(seed_url, x) for x in get_links_by_html(html) if re.match(link_regex, x))
for link in links:
if link not in seen:
seen[link]= depth + 1
if same_site(link, seed_url):
crawl_link_queue.append(link)
#print seen.values()
print '----All Done----' , len(seen)
return seen
if __name__ == '__main__':
all_links = link_crawler('http://example.webscraping.com', '/(index|view)',max_depth=2)
分页显示一直是web开发中一大烦琐的难题,传统的网页设计只在一个JSP或者ASP页面中书写所有关于数据库操作的代码,那样做分页可能简单一点,但当把网站分层开发后,分页就比较困难了,下面是我做Spring+Hibernate+Struts2项目时设计的分页代码,与大家分享交流。
1、DAO层接口的设计,在MemberDao接口中定义了如下两个方法:
public in
/*
*使用对象类型
*/
--建立和使用简单对象类型
--对象类型包括对象类型规范和对象类型体两部分。
--建立和使用不包含任何方法的对象类型
CREATE OR REPLACE TYPE person_typ1 as OBJECT(
name varchar2(10),gender varchar2(4),birthdate date
);
drop type p
what 什么
your 你
name 名字
my 我的
am 是
one 一
two 二
three 三
four 四
five 五
class 班级,课
six 六
seven 七
eight 八
nince 九
ten 十
zero 零
how 怎样
old 老的
eleven 十一
twelve 十二
thirteen
spring security 3中推荐使用BCrypt算法加密密码了,以前使用的是md5,
Md5PasswordEncoder 和 ShaPasswordEncoder,现在不推荐了,推荐用bcrpt
Bcrpt中的salt可以是随机的,比如:
int i = 0;
while (i < 10) {
String password = "1234
1.前言。
如题。
2.代码
(1)单表查重复数据,根据a分组
SELECT m.a,m.b, INNER JOIN (select a,b,COUNT(*) AS rank FROM test.`A` A GROUP BY a HAVING rank>1 )k ON m.a=k.a
(2)多表查询 ,
使用改为le