前言
本文主体内容参考自 https://www.cnblogs.com/skyfsm/p/6806246.html,补充了一些算法细节。
图像识别任务分类
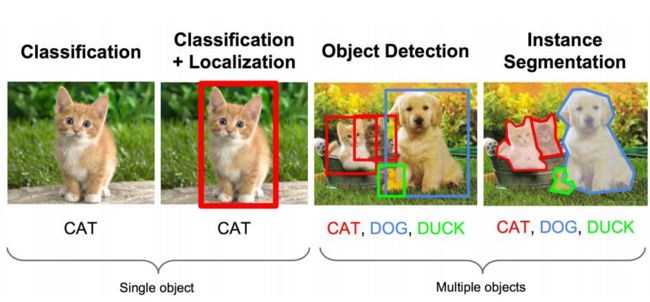
分类任务 Classification
输入: 图片
输出: 物体的类别
评估方法: 准确率,F1
定位任务 Localization
输入: 图片
输出: 方框在图片中的位置(x,y,w,h)
评估方法: 检测评级函数 intersection-over-union IOU 交并比
基本思路
思路1 看作回归问题
直接用网络预测出(x,y,w,h)四个参数的值,从而得出方框的位置。

步骤1:搭建一个图像识别神经网络
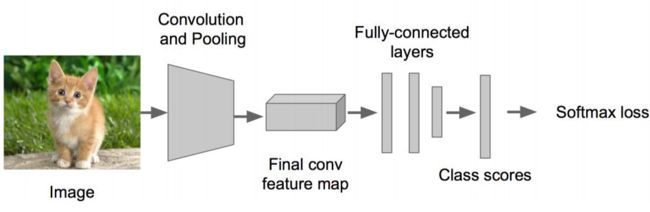
步骤2:在上述神经网络的尾部展开,分为分类头和回归头,即classification + regression模式

步骤3: SGD + 欧氏距离 训练Regression,前面的卷积层保持不变
步骤4:预测阶段拼上两个头部完成不同功能
备注:regression太难做了,应想方设法转换为classification问题。regression的训练参数收敛的时间要长得多,所以上面的网络采取了用classification的网络来计算出网络共同部分的连接权值。
思路2:取图像窗口
取大小不同的框,让框出现在不同的位置获取判定得分,取得分最高的框
步骤:对一张图片,用各种大小的框(遍历整张图片)将图片截取出来,输入到CNN,然后CNN会输出这个框的得分(classification)以及这个框图片对应的x,y,h,w(regression)

物体检测
多物体识别+定位多个物体
思路: 找出可能含有物体的框(也就是候选框,比如选1000个候选框),这些框之间是可以互相重叠互相包含的,这样我们就可以避免暴力枚举的所有框了

不同候选框方法对比:
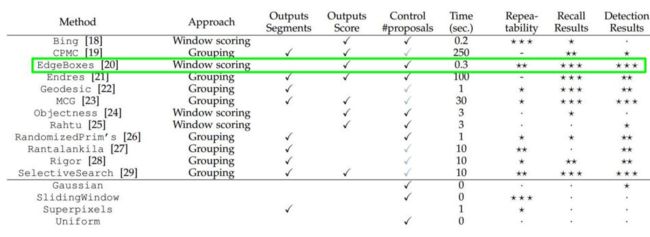
-
滑窗法(Sliding Window)
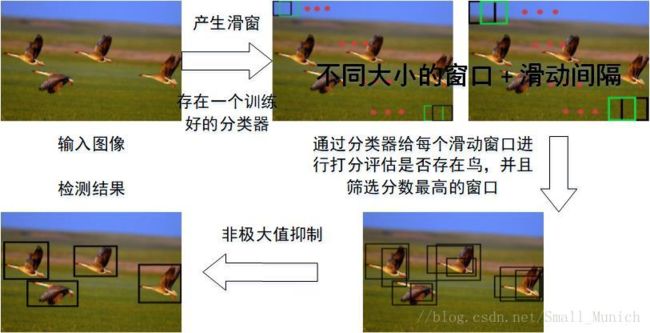 滑窗法
滑窗法
方法: 首先对输入图像进行不同窗口大小的滑窗进行从左往右、从上到下的滑动。每次滑动时候对当前窗口执行分类器(分类器是事先训练好的)。如果当前窗口得到较高的分类概率,则认为检测到了物体。对每个不同窗口大小的滑窗都进行检测后,会得到不同窗口检测到的物体标记,这些窗口大小会存在重复较高的部分,最后采用非极大值抑制(Non-Maximum Suppression, NMS)的方法进行筛选。最终,经过NMS筛选后获得检测到的物
评价: 效率低下 不同窗口大小进行图像全局搜索导致效率低下,而且设计窗口大小时候还需要考虑物体的长宽比。 -
EdgeBoxes
主要的思想:
一个候选框中完整包含的轮廓数量与该候选框的正确概率成正比。利用边缘信息,确定候选框中轮廓个数与框边缘重叠的轮廓个数,基于此对框评分,根据得分高低确定proposal信息。
 EdgeBoxes算法
EdgeBoxes算法
步骤:
首先利用结构化的方法检测出边缘,并利用非极大值抑制对边缘进行筛选;然后基于某种策略将似乎在一条直线上的边缘点集合成若干个edge group,并计算edge group之间的相似度,越是在同一直线上的edge group,其相似度越高。再通过edge group来确定轮廓数,实现策略为给每个edge group计算一个权值,将权值为1的edge group归为proposal内轮廓上的一部分,将权值为 0 的edge group归为proposal外或proposal框重叠的一部分,由此便提取得到proposal,并对proposal进行评分,选取得分最高的proposal作为最后的检测输出。
缺陷:
当一幅图像中包含多个相同的检测目标时,其得分最高的proposal几乎包含整幅图像,而不是单独的目标。原因在于,其不是基于“学习”的算法,没有训练的过程,也就没有具体的针对目标的模型,故这使得其在进行单一类别多目标检测时效果不佳。
-
Selective Search
 选择性搜索
选择性搜索
图像中物体可能存在的区域应该是有某些相似性或者连续性区域的。因此,选择搜索基于上面这一想法采用子区域合并的方法进行提取bounding boxes候选边界框。
步骤
- 对输入图像进行分割算法产生许多小的子区域( a graph-based segmentation method by Felzenszwalb and Huttenlocher)。
- 其次,根据这些子区域之间相似性(相似性标准主要有颜色、纹理、大小等等)进行区域合并,不断的进行区域迭代合并。
- 每次迭代过程中对这些合并的子区域做bounding boxes(外切矩形),这些子区域外切矩形就是通常所说的候选框
评价
计算效率优于滑窗法。
由于采用子区域合并策略,所以可以包含各种大小的疑似物体框。
合并区域相似的指标多样性,提高了检测物体的概率。
参考
https://www.learnopencv.com/selective-search-for-object-detection-cpp-python/
RCNN (Region With CNN Feature)

步骤
- 训练(或者下载)一个分类模型(比如AlexNet)
- 对该模型做fine-tuning
- 特征提取
3.1 提取图像的所有候选框 selective search
3.2 对于每一个区域:修正区域大小(剪裁和放缩) 以适合CNN的输入,做一次前向运算,将第五个池化层的输出(就是对候选框提取到的特征)存到硬盘 - 使用二分类判断候选框内物体的类别
-
使用回归器精细修正候选框位置:对于每一个类,训练一个线性回归模型去判定这个框是否框得完美
 修正器
修正器
SPP Net - Spatial Pyramid Pooling 空间金字塔池化
ref: https://arxiv.org/pdf/1406.4729.pdf
-
为什么需要SPP
- 卷积层对于输入数据的大小并没有要求,唯一对数据大小有要求的则是第一个全连接层
- 在R-CNN中,每个候选框先resize到统一大小,然后分别作为CNN的输入,这样是很低效的。
所以SPP Net根据这个缺点做了优化:只对原图进行一次卷积得到整张图的feature map,然后找到每个候选框zaifeature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
-
SPP原理
 SPP原理
SPP原理
https://blog.csdn.net/yzf0011/article/details/75212513 详解
- SPP 效果
- 多窗口的pooling会提高实验的准确率
- 输入同一图像的不同尺寸,会提高实验准确率(从尺度空间来看,提高了尺度不变性(scale invariance))
- 用了多View(multi-view)来测试,也提高了测试结果
- 图像输入的尺寸对实验的结果是有影响的(因为目标特征区域有大有有小)
- 因为我们替代的是网络的Poooling层,对整个网络结构没有影响,所以可以使得整个网络可以正常训练。
Fast RCNN
Fast R-CNN就是在RCNN的基础上采纳了SPP Net方法,在inference过程中避免重复计算feature map。
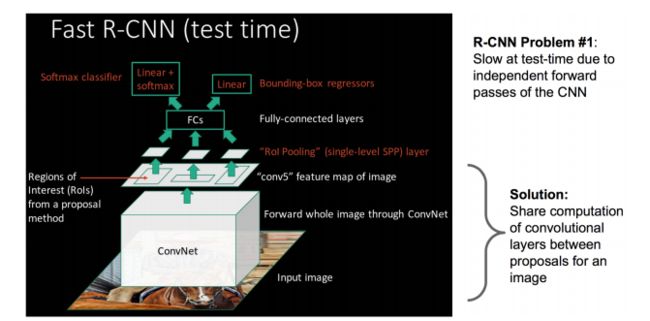
评价
- 共享卷积层,现在不是每一个候选框都当做输入进入CNN了,而是输入一张完整的图片,在第五个卷积层再得到每个候选框的特征
Faster R-CNN
Fast RCNN的瓶颈在于选择性搜索耗时。为此加入一个提取边缘的神经网络,也就说找到候选框的工作也交给神经网络来做了。做这样的任务的神经网络叫做Region Proposal Network(RPN)。
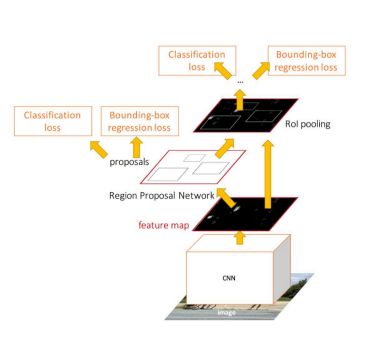
-
步骤
- 在feature map上滑动窗口 (原文使用 33滑动窗口,并使用11卷积网络替代全连接层)
-
建一个神经网络用于物体分类+框位置的回归
2.1 Anchors 每个位置最大的候选区域数量为k。
2.2 回归层有4k个输出,(窗口一般使用四维向量(x,y,w,h)来表示)
 边框回归的参数
边框回归的参数
 image.png
image.png
注意 只有当Proposal和Ground Truth比较接近时(线性问题),才能将其作为训练样本训练我们的线性回归模型,否则会导致训练的回归模型不work(变成复杂的非线性问题)
2.3 分类层有2k个输出。 用于判定该proposal是前景还是背景。
2.4 细节:全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练 - 滑动窗口的位置提供了物体的大体位置信息
- 框的回归提供更精确的位置
-
Proposal Layer
- 生成anchors,利用[dx(A),dy(A),dw(A),dh(A)]对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致)。
- 按照输入的foreground softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的foreground anchors。
- 利用im_info将fg anchors从MxN尺度映射回PxQ原图,判断fg anchors是否大范围超过边界,剔除严重超出边界fg anchors。
- 进行nms(nonmaximum suppression,非极大值抑制)。
- 再次按照nms后的foreground softmax scores由大到小排序fg anchors,提取前post_nms_topN(e.g. 300)结果作为proposal输出。
-
ROI Pooling Layer
- 首先使用spatial_scale参数将proposal映射回(M/16)x(N/16)大小的feature maps尺度
- 将每个proposal水平和竖直都分为7份,对每一份都进行max pooling处理
- 实现固定长度输出

-
Faster RCNN训练
步骤:- 在已经训练好的model上,训练RPN网络,对应stage1_rpn_train.pt
- 利用步骤1中训练好的RPN网络,收集proposals,对应rpn_test.pt
- 第一次训练Fast RCNN网络,对应stage1_fast_rcnn_train.pt
- 第二训练RPN网络,对应stage2_rpn_train.pt
- 再次利用步骤4中训练好的RPN网络,收集proposals,对应rpn_test.pt
- 第二次训练Fast RCNN网络,对应stage2_fast_rcnn_train.pt
-
训练RPN网络
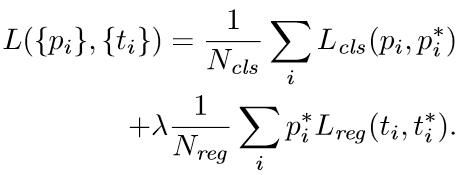 损失函数
损失函数- i表示anchors index,pi表示foreground softmax predict概率,pi代表对应的GT predict概率(即当第i个anchor与GT间 IoU>0.7,认为是该 anchor是 foreground,pi=1;反之IoU<0.3时,认为是该anchor是background,pi*=0;至于那些0.3
- bounding box regression网络训练。注意在该loss中乘了pi*,相当于只关心foreground anchors的回归
- 早期实现中,cls项归一化为mini-batch的大小,。reg项设为anchor位置的数量。这样两项差不多等权重。
- Smooth L1 loss 原因参见:https://www.jianshu.com/p/b37e454a986b
 S
S
 Smooth L1
Smooth L1
- i表示anchors index,pi表示foreground softmax predict概率,pi代表对应的GT predict概率(即当第i个anchor与GT间 IoU>0.7,认为是该 anchor是 foreground,pi=1;反之IoU<0.3时,认为是该anchor是background,pi*=0;至于那些0.3
Non-Maximum Suppression 非极大值抑制方法
- 非极大抑制算法应用相当广泛,其主要目的是消除多余的框,找到最佳的物体检测位置。
- 其实现的思想主要是将各个框的置信度进行排序,然后选择其中置信度最高的框A,将其作为标准选择其他框,同时设置一个阈值,当其他框B与A的重合程度超过阈值就将B舍弃掉,然后在剩余的框中选择置信度最大的框,重复上述操作。
import numpy as np
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1) # 计算出所有图片的面积
order = scores.argsort()[::-1] # 图片评分按升序排序
keep = [] # 用来存放最后保留的图片的相应评分
while order.size > 0:
i = order[0] # i 是还未处理的图片中的最大评分
keep.append(i) # 保留改图片的值
# 矩阵操作,下面计算的是图片i分别与其余图片相交的矩形的坐标
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
# 计算出各个相交矩形的面积
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# 计算重叠比例
ovr = inter / (areas[i] + areas[order[1:]] - inter)
#只保留比例小于阙值的图片,然后继续处理
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1]
return keep
Hard-Negative Mining 难分样本挖掘
proposal中的正样本的数量远远小于负样本,这样训练出来的分类器的效果总是有限的,会出现许多 false negative, 即预测为负例的正样本。
Fast RCNN中ground truth 的 IoU 在 [0.1, 0.5) 之间标记为负例, 随机选择。而IOU为[0, 0.1) 的,理论上为easy example,容易分类。如果分类错误即形成false positive example, 用于 hard negative mining。
实现 一个简单的实现方式是在所有负例中随机抽取N个样本,然后根据样本的预测概率排序,取其中P个样本作为训练负样本。