异常报警
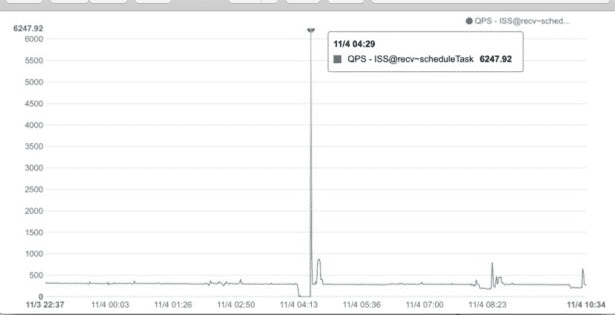
某日ldbees系统凌晨发生系统线程数飚高的报警,通过观察系统监控发现,在凌晨4点左右有一次请求抖动,请求量在瞬间增大了10倍左右。请求量的瞬间增大并不可怕,因为这是些都是消息请求,消息量增大到超过系统线程池最大处理能力时会reject,被reject的消息在之后进行重投即可。
但是问题是,请求量的暴增只在一瞬间,之后马上下降,但是系统的线程数却一直保持在最高位,即便6个小时之后也没有降下来,系统线程数飚高的报警一直存在(一般会在监控系统中配置线程数升高的报警,报警值根据系统情况设置在1000到1200左右)。
通过线程dump发现,系统线程的总数在2k左右,而大量的线程处于休眠状态却也不会被回收。
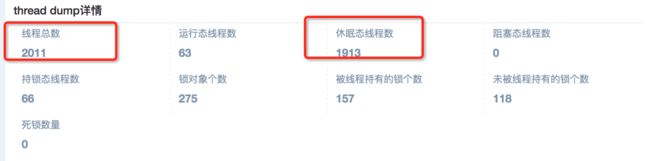
所以问题就是为什么会有这么多的线程无法回收,然后为什么有这么多线程处于休眠状态,休眠的线程在干什么?
问题暴露出来之后,和负责ldbees的同学一起看了下,也没有发现什么具体的原因,看了下相关代码也没想明白为什么峰值请求结束之后线程不会下降,因为也不是自己负责的系统所以也就没有在关注了。
过了很多天之后,偶然发现负责ldbees的同学还在孜孜不倦的研究这个问题,接着继续聊了下,提到峰值请求结束之后,后续其实还是有请求流量过来,并且这些请求实际上是一个打包的批量请求,一次请求对应到线程池上其实是10次请求。这时候意识到之前自己走入了一个误区,峰值请求结束之后不代表着后续没有任何请求了,还是有源源不断的请求会加入的线程池的队列之中。
于是在回过头来看看ldbees中线程池的设置,
发现keepAliveTime的大小设置为30s,开始感觉到是keepAliveTime设置的有问题,而keepAliveTime到底是如何影响到线程的状态呢,通过查看ThreadPoolExecutor的代码发现keepAliveTime实际上是线程从queue中获取任务的超时时间,在未超时之前线程处于wait状态,在超时之后ThreadPoolExecutor会开始回收线程的工作。
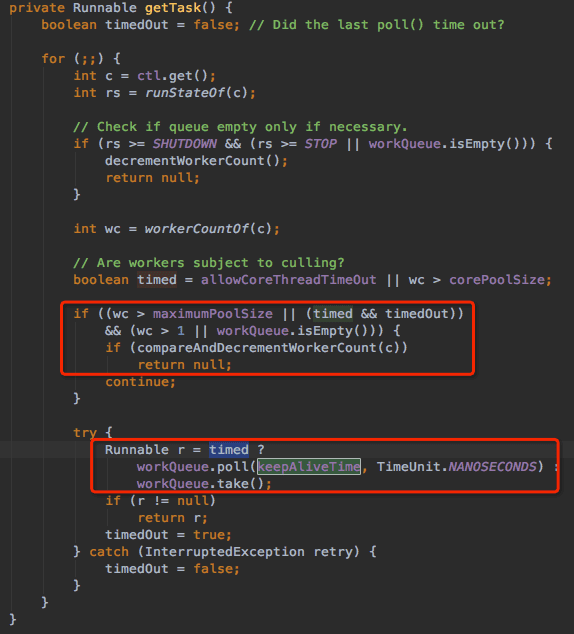
然而线程dump时大量的线程状态为wait,那为什么在30s之后线程为什么还是wait,在wait超时之后不就该回收吗?
那只有一个可能,线程不是一直处于wait状态,中间取得过任务,只是在任务完成之后继续尝试从queue获取任务而处于wait状态。由于一直有任务加入队列,线程一直有机会获取到任务,一直无法发送超时从而导致无法回收。
demo验证
在怀疑是keepAliveTime的问题之后,写了一个demo来进行验证,demo比较简单,每秒往batchQueryHbaseExecutorService线程池中塞入400个任务,然后通过调整batchQueryHbaseExecutorService的参数来观察线程数的变化情况。
public static void main(String[] args) {
ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(1);
ExecutorService batchQueryHbaseExecutorService = new ThreadPoolExecutor(10, 20,
20000L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue(200),new ThreadPoolExecutor.AbortPolicy());
scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
public void run() {
System.out.println("********添加任务!");
try {
for(int i = 1; i < 400; i++){
System.out.println("batchQueryHbaseExecutorService!" + i);
batchQueryHbaseExecutorService.submit(new Runnable() {
@Override
public void run() {
int n = 0;
for(int k = 0; k < 3000000; k++){
n += k;
}
System.out.println(Thread.currentThread().getId() + ": 正在执行!");
}
});
}
}catch (Exception e) {
e.printStackTrace();
}
}
}, 1000, 1000, TimeUnit.MILLISECONDS);
}
通过调节batchQueryHbaseExecutorService的参数设计,在keepAliveTime为20s时,线程池线程数达到maximumPoolSize(20),并且一直不会下降,通过观察线程状态,发现大部分线程的状态绝大多数时间处于wait状态,但是观察时间拉长,发现基本上每个线程都会在某个时间处于running状态(下图右边),也就是说线程在keepAliveTime时间之内都能获取到一个任务并执行,执行完之后在继续处于wait任务的状态(下图左边),线程一直无法进行回收。这样验证之前对应大量线程处于wait状态的猜想。
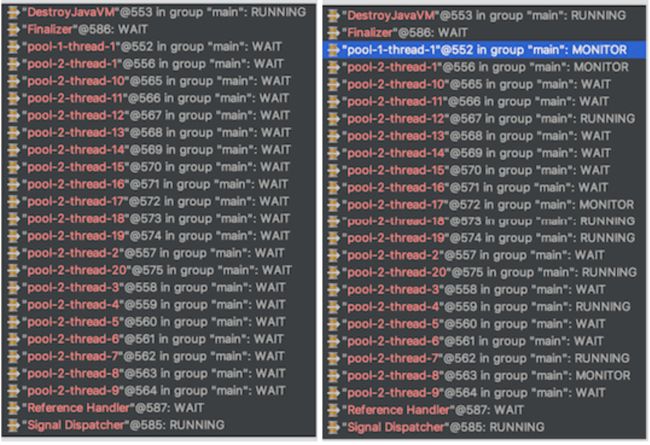
于是原因以及非常清晰了,在ldbees系统中,一次请求会涉及到多个线程池的操作,每个线程的设置都一样,请求峰值之后多个线程池的线程数达到300无法回收,从而导致线程数升高报警,由于后续还有少许请求过来,导致了长时间也无法进行线程回收。
找到问题之后,开始进行参数调整观察线程运行情况,以期望找到线程池设置的最优参数。
如果把keepAliveTime调小,设置为200ms,则会发现在线程数在最开始达到20个之后会减少到10个左右,长时间观察会发现线程数在20~10之间波动的比较频繁。这是因为keepAliveTime设置调小,线程更容易被回收,在请求量一直很大时,会频繁进行创建和回收。
接着调整queue的大小到2000,则会发现线程数在最开始达到20个之后减少到10个左右,波动幅度和频率减小很多。
数据分析
通过demo程序的测试,基本上可以确认ldbeev系统在一次请求峰值之后线程数数无法下降的原因了,keepAliveTime设置过大,导致线程增长到maximumPoolSize之后无法进行回收。
这时候我们关注下另一个分析系统性能时非常重要的参数——rt。
在请求峰值6w的时候,ldbees30台机器,单机每条2000个任务,即便每个任务的rt已经低至30ms,但是30个核心线程每秒能处理的任务数为30*1000/30=1000,而200的队列已经无法应对大量的请求,线程数立马扩大到300并发生大量reject异常。
而batchSyncExecutorService线程池中keepAliveTime为60s,也就是说batchSyncExecutorService中的线程只有在60s内没有一次机会能获取到任务才会被回收,但是即使回到均值调用请求下单机每秒也有400*10/30=130个任务过来。
在maximumPoolSize为300时,通过计算会发现,在60s内每个线程有130*60/300=26次执行任务的机会,既然在keepAliveTime内有机会可以执行任务当然不会被回收。但是线程这个时候每个线程的利用率则非常低,26*30/60000=13%,也就是线程有87%的时间处于wait状态。这也是在出现线程数飚高报警之后,线程dump时发现大量的线程状态为wait。
参数设置
根据之前的测试demo和数据分析,现在来讨论下ldbeev系统下ThreadPoolExecutor如何设置合理的参数:
corePoolSize:根据日常请求量和任务rt计算得出,corePoolSize依然设置为30,可以满足日常请求量的需求。
maximumPoolSize:maximumPoolSize一般设置为corePoolSize的两到三倍,提供一定的业务容量弹性,保证请求量增大时满足需求。当然在请求量突然暴增10多倍情况下,这已经不是正常的情况,必然发生大量的reject,做好重试即可。
keepAliveTime:keepAliveTime的设置调小,根据日常请求量和任务rt,任务增量趋势测试得出,keepAliveTime设置在500ms左右,让ThreadPoolExecutor线程数扩大之后有更大的机会能被回收。
queue:queue的值调大,让线程池整体能承受一定的请求波动,而不用频繁去创建和回收线程,毕竟创建线程也需要消耗系统资源。当然queue也不能无限过大,一是要考虑内存的占用,还要考虑系统在重启时queue中残留任务的完成状态。
threadName:ThreadPoolExecutor尽量设置线程名称,可以实现自己的NameThreadFactory,这样在线程dump分析时候能更快的分析和定位线程状态。
所以最终的参数设置为:
batchQueryHbaseExecutorService = new ThreadPoolExecutor(30, 60, 500L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue(2000), new NameThreadFactory("batchQueryHbaseExecutorService"), new ThreadPoolExecutor.AbortPolicy());