Java线程同步与异步
线程池
无锁化的实现方案
分布锁的实现方案
分享的目的:
进一步掌握多线程编程和应用的技巧,希望对大家在平时的开发中应对高并发编程有所帮助
Java线程同步与异步
1. 同步相关的方法有
wait, notify, notifyAll
2. 关键字
synchronized
3. JDK锁的框架
AQS (AbstractQueuedSynchronizer)
4. AQS的实现类
java.util.concurrent.locks.ReentrantLock
java.util.concurrent.locks.ReentrantReadWriteLock
java.util.concurrent.CountDownLatch
java.util.concurrent.Semaphore
5. 例子——两个线程交替打印出100以内的奇数和偶数
主程序:
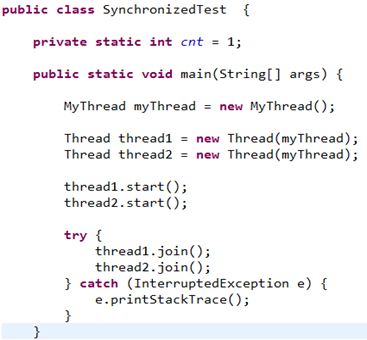

输出结果示例:
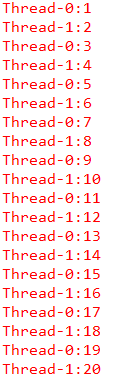
...
...
...
思考:
读者可以用两种其它方法实现,加深自己对Java线程同步和互斥的理解
用 ReentrantLock?
还是用wait和notify ?
线程池
作用:
控制线程并发数量,一般用在控制单机并发度上, 也是实现流控的一种方案;
实现原理:
1. 参数含义
corePoolSize: 核心线程的数量, 在CPU密集型和IO密集型的任务中,这个参数的设置不太一样:
在CPU密集型的应用中:
通常这个参数被设置为: 机器cpu核数-1, 例如机器有4个核,这个参数就被设置为3, 这样做的即兼顾了最大的并发度,又兼顾了其它非重要的核心任务的执行;
在IO密集的任务中:
通常这个参数被设置为机器cpu核数*(1.5 - 3),具体情况还需要根据实际业务情况进行压测比较,然后再给出最优的值;
maximumPoolSize: 最大核心线程的数量
poolSize: 当前线程的数量
当用户向线程池中新提交一个线程的时候,会有如下情况:
情况1.
如果当前线程池中线程的数量小于corePoolSize, 就会创建一个新的线程, 并添加到线程池中;
情况2.
如果当前线程池中线程的数量等于corePoolSize, 并且等待队列中还没有满,则把当前用户添加的线程对象放在等待队列中;
情况3.
如果当前线程池中线程的数量大于等于corePoolSize并且小于maximunPoolSize,并且等待队列已经满,则创建一个新的线程,并添加到线程池中;
情况4.
如果当前线程池中线程的数量等于maximunPoolSize, 则会根据线程创建线程时候的拒绝策略,进行相应的处理;
2. java线程对象中run方法和start方法的区别:
2.1 线程对象直接调用run方法,JVM是不会有感知,是不会直接产生一个新的线程, 此时程序运行的方式依然是串行的;
2.2 线程对象直接调用start方法,JVM才会有感知,会产生一个新的线程, 此时才会产生并发多线程;
线程池正是充分利用了run方法和start的区别来实现线程的复用;
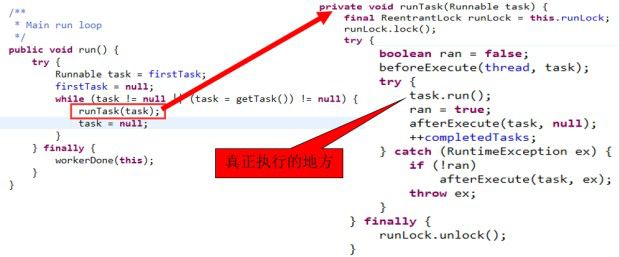
3. 线程池的核心代码
下面均是以jdk1.6的线程池的源码,jdk1.7和jdk1.8线程池实现在上有些变化,但核心思想不变,有兴趣可以自己去研究
提交线程的核心代码:
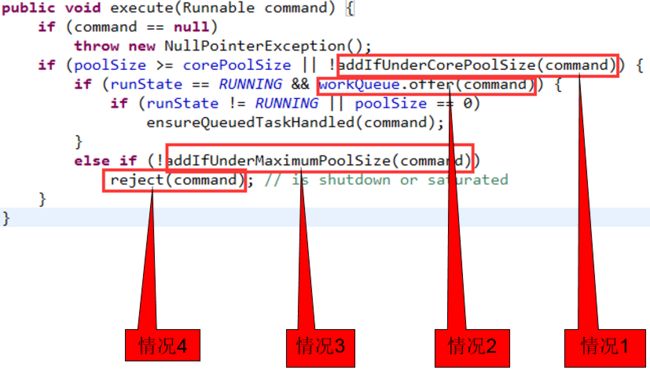
执行用户任务的核心代码:
无锁化的实现方案
用线程池的方案
1. netty的reactor线程模型,参考netty官方或网上相关的资料
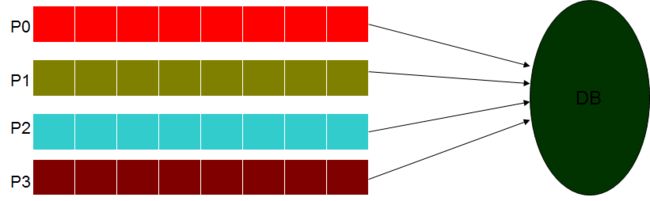
2. 异地机房数据库之间的数据同步:
用表名+主键名做hash ,hash值相同的记录被写到同一个Kafka的Partition中去,假设一个Partition用一个线程进行消费, 这样不同线程之间写入目标数据库的时候,就不会存在数据库行锁的竞争关系,间接实现了无锁化的操作, 即线程之间并行,线程内部串行, 如下图所示;
用CAS的命令
1. JDK中各种类型值的原子操作
AtomicInteger
AtomicLong
AtomicBoolean
2. jdk中各种锁的实现, 本质也是volitate变量+CAS
java.util.concurrent.locks.ReentrantLock
java.util.concurrent.Semaphore
java.util.concurrent.CountDownLatch
分布锁的实现方案
1. tair
incr和decr操作,相当于是乐观锁
2. Redis/memcache
setNx命令
3. Zookeeper
充分利用watcher机制,创建临时结点,谁创建成功,谁就获得当前的锁
4. 数据库:利用数据库的行锁
// 加锁SQL
update trade_base set status = 1 where trade_no=“XXX” and status = 0;
// 解锁SQL
update trade_base set status = 0 where trade_no=“XXX” and status = 1;
注意trade_base表上一要有trade_no的列的唯一索引
当然具体用那种分布锁,还需要结合业务自身的需要,一般来说,在并发量不是别大,数据库完全可以扛得住的情况下,用数据库实现分布锁最快,最方便,而且性能的损失也非常地小;
当然现在很多场景下,都是分库分表,并且加锁和解锁分别都只影响一行,对数据库来说,加锁和解锁的 sql也是非常轻量的sql操作,因此在性能损失上不用过多的担心。
本文作者:友德
阅读原文
本文为云栖社区原创内容,未经允许不得转载。