对于互联网er们来说,一定的数据爬取技能已成为生活必需品,但是技术门槛始终碍眼,以至于我们不能开启更美好的数据世界,这不波哥给大家整理下目前全球范围内最受欢迎的0门槛95%数据爬取知识-Web Scraper。
一、插件安装
1、安装方法
①从Chrome商店(http://dwz.cn/7bpm9c)【需科学上网】 安装此扩展(Extension),安装完成后需重启 Chrome 以确保扩展加载完成。
②网上搜索下载插件安装包,然后进行本地安装。
2、Google浏览器要求
此扩展要求 Chrome 版本号 31 及以上。无操作系统限制。【欲查看 Chrome 版本,可在浏览器地址栏中输入:chrome://settings/help】
二、Web Scraper打开方式
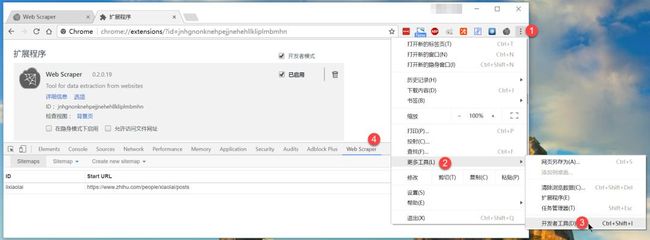
Web Scraper 集成入 Chrome 开发者工具(Developer Tools)。图 1 展示了如何打开。你也可以使用以下快捷键(Shortcuts)打开 开发者工具。请在打开 开发者工具 后选中 Web Scraper 标签。
快捷键:
Windows,Linux:Crtl + Shift + I 或 F12,开启开发者工具
Mac:Cmd + Opt + I,开启开发者工具
三、训练爬虫-抓取网站示例
打开欲抓取网站,也就是你心中目标站点。
1、建立 Sitemap
欲创建 Sitemap 首先需要指定起始 URL ,这个 URL 是抓取的起点。如果抓取始于多个位置,你也可以指定多个起始 URL。比如,你想要抓取多个搜索结果,就可以为每个搜索结果建立独立的起始 URL。
指定存在序列关系的多个 URL
如果某个网站的页面 URL 中存在数列, 使用指定序列比使用 Link 选择器的方式抓取网页更为合理。用指定序列 [1-100] 替代 URL 中页码部分。如页码部分有 0 作为占位符可使用 [001-100]。入页码有固定间隔可使用 [0-100:10],以10为差的等差数列形式。示例如下:
http://example.com/page/[1-3]可抓取以下网页:
* http://example.com/page/1
* http://example.com/page/2
* http://example.com/page/3
http://example.com/page/[001-100]可抓取以下网页:
* http://example.com/page/001
* http://example.com/page/002
* http://example.com/page/003
http://example.com/page/[0-100:10]可抓取以下网页:
* http://example.com/page/0
* http://example.com/page/10
* http://example.com/page/20
创建选择器(Selector)
在创建 sitemap 后可为其添加选择器,在选择器面板可以添加新选择器、对原有选择器进行改进或浏览选择器树状结构。选择器能够以树状结构方式添加,Web Scraper 也按照此结构抓取网页。比如有一个新闻网站,你想抓取上面所有文章,这些文章都链接在网站首页。如下图2示例网站:
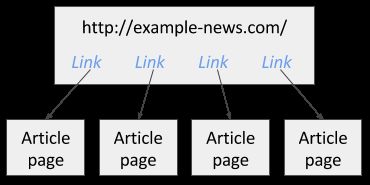
欲抓取此网站,你可以建立 Link 选择器提取首页所有文章链接。然后在添加一个 Text 选择器作为子选择器从上面的 Link 选择器指向的网页提取文章。下图3展示了如何为此网站建立 sitemap:

需注意,当创建选择器时需使用 Element preview 和 Data preview 功能以确保你选中了正确的网页元素及数据。
更多关于选择器树状结构相关信息可在选择器文档中看到。你至少应当阅读以下核心选择器相关内容:
1、文本选择器(Text selector)
2、链接选择器(Link selector)
3、元素选择器(Element selector)
浏览选择器树状结构
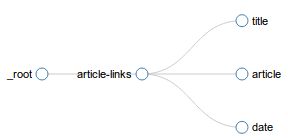
在为 sitemap 建立好选择器后,你可以在 Selector graph panel 浏览选择器树状结构。下图4展示了一个示例选择器图。
抓取网站
在为 sitemap 建立选择器后可开始抓取网站。打开 Scrape 面板开始抓取,如图5所示。
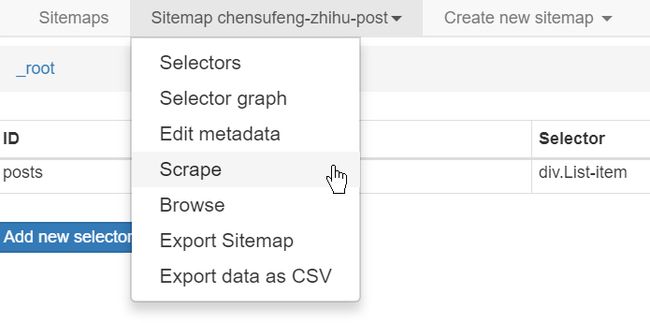
此时会打开一个网页窗口, scraper 会在其中加载网页并从中提取数据。在抓取完成后此窗口会关闭并弹出提示信息。你可以打开 Browse 面板查看抓取到的数据,并通过 Export data as CSV 面板将其导出。
0门槛数据爬虫Web Scraper连载:
0门槛数据爬虫Web Scraper进阶 (一)-波哥产品
0门槛数据爬虫Web Scraper进阶 (二)-波哥产品