本篇开始介绍Spark API的核心扩展功能 Sprak Streaming。
官方介绍
Spark Streaming 是Spark API核心的扩展,支持实时数据流的可扩展,高吞吐量,容错流处理。数据可以从Kafka,Flume, Kinesis, 或TCP Socket来源获得,并且可以使用与高级别功能表达复杂的算法来处理map,reduce,join和window。最后,处理后的数据可以推送到文件系统,数据库和实时仪表看板。
工作原理
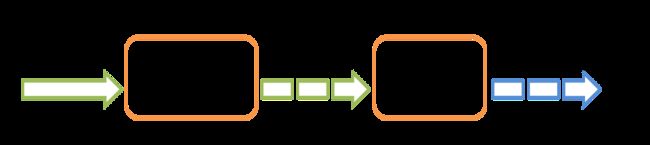
Spark Streaming接收实时输入数据流并将数据分批,然后由Spark引擎处理,以批量生成最终结果流。
代码示例
我以本地Socket 为数据源实现了一个简单对字符串分割计数的功能。
Maven 中引入
org.apache.spark
spark-streaming_2.11
2.3.1
先实现一个Socket Server。在本地启动一个ServerSocket,端口号设为9999,启动后开始监听客户端连接,一旦连接成功,打印客户端地址,然后向客户端推送一串字符串,时间间隔为1秒钟,循环一百次。
package com.yzy.spark;
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
public class SparkSocket {
static ServerSocket serverSocket = null;
static PrintWriter pw = null;
public static void main(String[] args) {
try {
serverSocket = new ServerSocket(9999);
System.out.println("服务启动,等待连接");
Socket socket = serverSocket.accept();
System.out.println("连接成功,来自:" + socket.getRemoteSocketAddress());
pw = new PrintWriter(new OutputStreamWriter(socket.getOutputStream()));
int j = 0;
while (j < 100) {
j++;
String str = "spark streaming test " + j;
pw.println(str);
pw.flush();
System.out.println(str);
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
pw.close();
serverSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
编写Spark Streaming Demo。创建一个socket类型的JavaStreamingContext,它是Spark Streaming
的入口,host指向localhost,端口号为9999。
package com.yzy.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class demo7 {
private static String appName = "spark.streaming.demo";
private static String master = "local[*]";
private static String host = "localhost";
private static int port = 9999;
public static void main(String[] args) {
//初始化sparkConf
SparkConf sparkConf = new SparkConf().setMaster(master).setAppName(appName);
//获得JavaStreamingContext
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(3));
//从socket源获取数据
JavaReceiverInputDStream lines = ssc.socketTextStream(host, port);
//拆分行成单词
JavaDStream words = lines.flatMap(new FlatMapFunction() {
public Iterator call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
//计算每个单词出现的个数
JavaPairDStream wordCounts = words.mapToPair(new PairFunction() {
public Tuple2 call(String s) throws Exception {
return new Tuple2(s, 1);
}
}).reduceByKey(new Function2() {
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
//输出结果
wordCounts.print();
//开始作业
ssc.start();
try {
ssc.awaitTermination();
} catch (Exception e) {
e.printStackTrace();
} finally {
ssc.close();
}
}
}
先运行SparkSocket,控制台输出
服务启动,等待连接
此时主线程会阻塞,再运行demo,观察SparkSocket控制台变化(如果运行demo报错请参考最底部)
服务启动,等待连接
连接成功,来自:/127.0.0.1:5175
spark streaming test 1
spark streaming test 2
spark streaming test 3
......每隔一秒打印一条
再观察demo控制台
-------------------------------------------
Time: 1530089706000 ms
-------------------------------------------
(spark,1)
(1,1)
(streaming,1)
(test,1)
-------------------------------------------
Time: 1530089709000 ms
-------------------------------------------
(4,1)
(spark,3)
(2,1)
(streaming,3)
(test,3)
(3,1)
-------------------------------------------
Time: 1530089712000 ms
-------------------------------------------
(spark,3)
(5,1)
(6,1)
(streaming,3)
(test,3)
(7,1)
......每隔三秒打印一次聚合信息
我设置了3秒钟聚合一次,Spark 刚启动的第一个三秒钟只接收到一条来自socket服务器的数据,因此每个单词计数只有1。然后socket服务器每隔一秒就会有一条数据发送过来,后面的聚合结果也验证了这一点。
关于DStream
点此查看官方文档
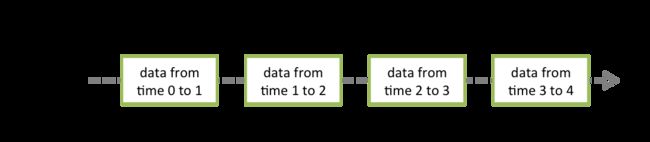
1.DStream是Spark Streaming提供的基本抽象。它表示连续的数据流,即从源接收的输入数据流或通过转换输入流生成的已处理数据流。在内部,DStream由连续的RDD系列表示,这是Spark对不可变的分布式数据集的抽象。DStream中的每个RDD都包含来自特定时间间隔的数据。
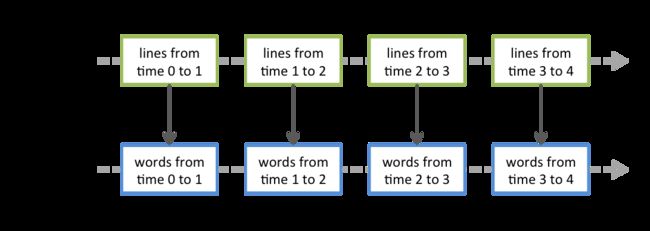
2.在DStream上应用的任何操作都会转化为对基础RDD的操作。在本例中,flatMap操作将应用于linesDStream中的每个RDD 以生成DStream的 wordsRDD。
因此,我们还可以将本例转化为JavaRDD数据集来操作。代码改动如下
//.....
words.foreachRDD(new VoidFunction>() {
public void call(JavaRDD rdd) throws Exception {
JavaPairRDD pairRDD = rdd.mapToPair(new PairFunction() {
public Tuple2 call(String s) throws Exception {
return new Tuple2(s, 1);
}
}).reduceByKey(new Function2() {
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
pairRDD.foreach(new VoidFunction>() {
public void call(Tuple2 tuple2) throws Exception {
System.out.println(String.format("word:%s,count:%d", tuple2._1(), tuple2._2()));
}
});
}
});
//删除wordCounts.print();
控制台输出
前面日志被覆盖了...
word:18,count:1
word:spark,count:3
word:17,count:1
word:16,count:1
word:streaming,count:3
word:test,count:3
关于 StreamingContext
点此查看官方文档
1.要初始化Spark Streaming程序,必须创建一个StreamingContext对象,它是所有Spark Streaming功能的主要入口。
//初始化sparkConf
SparkConf sparkConf = new SparkConf().setMaster(master).setAppName(appName);
//获得JavaStreamingContext
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(3));
2.appName参数是你的应用程序在集群UI上显示的名称
3.master是Spark,Mesos或YARN群集URL,或者是以本地模式运行的特殊 local[*] 字符串。详情参见文章 Spark启动时的master参数以及Spark的部署方式
4.JavaStreamingContext对象也可以从现有的JavaSparkContext创建
JavaSparkContext sc = ... //existing JavaSparkContext
JavaStreamingContext ssc = new JavaStreamingContext(sc, Durations.seconds(3));
5.要点
- 一旦上下文启动,就不能建立或添加新的
streaming computations。 - 一旦上下文停止,就不能重新启动。
- 同时只能有一个
StreamingContext可以在JVM中处于活动状态。 -
StreamingContext上的stop()也会停止SparkContext。要仅停止StreamingContext,请将可选参数stopSparkContext设为false。 - 只要先前的
StreamingContext在创建下一个StreamingContext之前停止(不停止SparkContext),就可以重新使用SparkContext来创建多个StreamingContext。
遇到的问题
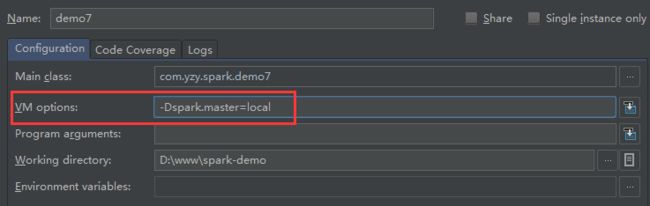
启动demo报错:org.apache.spark.SparkException: A master URL must be set in your configuration.
解决方式设置编译器的 VM Options=-Dspark.master=local