IO多路复用
Redis客户端对服务端的每次调用都经历了发送命令,执行命令,返回结果三个过程。其中执行命令阶段,由于Redis是单线程来处理命令的,所有每一条到达服务端的命令不会立刻执行,所有的命令都会进入一个队列中,然后逐个被执行。并且多个客户端发送的命令的执行顺序是不确定的。但是可以确定的是不会有两条命令被同时执行,不会产生并发问题,这就是Redis的单线程基本模型。
redis的多路复用选择器
Redis 基于 Reactor 模式开发了自己的网络事件处理器: 这个处理器被称为文件事件处理器(file event handler):
文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字, 并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时, 与操作相对应的文件事件就会产生, 这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
文件事件处理器的构成
文件事件处理器的四个组成部分, 它们分别是套接字、 I/O 多路复用程序、 文件事件分派器(dispatcher)、 以及事件处理器。
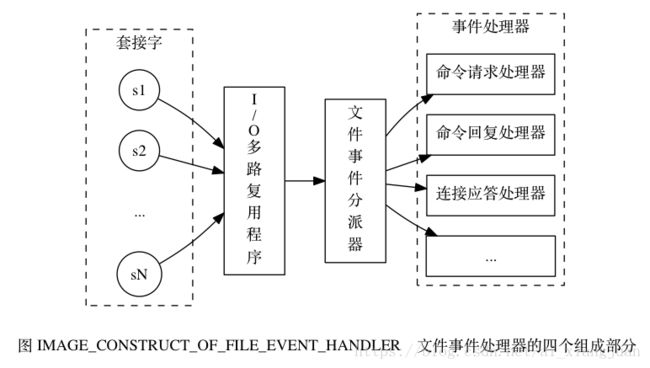
文件事件是对套接字操作的抽象, 每当一个套接字准备好执行连接应答(accept)、写入、读取、关闭等操作时, 就会产生一个文件事件。 因为一个服务器通常会连接多个套接字, 所以多个文件事件有可能会并发地出现。
I/O 多路复用程序负责监听多个套接字, 并向文件事件分派器传送那些产生了事件的套接字。
尽管多个文件事件可能会并发地出现, 但 I/O 多路复用程序总是会将所有产生事件的套接字都入队到一个队列里面, 然后通过这个队列, 以有序(sequentially)、同步(synchronously)、每次一个套接字的方式向文件事件分派器传送套接字: 当上一个套接字产生的事件被处理完毕之后(该套接字为事件所关联的事件处理器执行完毕), I/O 多路复用程序才会继续向文件事件分派器传送下一个套接字。

Redis的线程模型
- 文件事件处理器
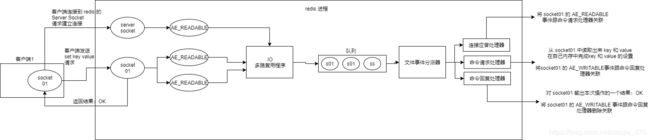
如果是客户端要连接 redis,那么会为socket关联连接应答处理器
如果是客户端要写入数据到 redis,那么会为 scoket关联命令请求处理器
如果是客户端要从 redis读数据,那么会为socket关联命令回复处理器
复用的封装实现
Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)
文件事件处理器使用 I/O 多路复用模块同时监听多个 FD,当 accept、read、write 和 close 文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器
虽然整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引入,实现了同时对多个 FD 读写的监控,提高了网络通信模型的性能,同时也可以保证整个 Redis 服务实现的简单
redis的多路复用, 提供了select, epoll, evport, kqueue几种选择,在编译的时候来选择一种。
- select是POSIX提供的, 一般的操作系统都有支撑;
- epoll 是LINUX系统内核提供支持的;
- evport是Solaris系统内核提供支持的;
- kqueue是Mac 系统提供支持的;
我们一般运行的服务器都是LINUX系统上面,这里重点比较一下select、poll和epoll 3种多路复用的差异。
IO介绍
I就是input输入,O就是output输出,一起就是基本输入输出设备;I/O也就是输入输出地址。每个设备都会有一个专用的I/O地址,用来处理自己的输入输出信息。I/O地址绝对不能重复,如果两个设备的I/O地址有冲突,系统硬件就不能正常工作。
- IO模型
对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
(1) 等待数据准备 (Waiting for the data to be ready)
(2)将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
正是因为IO操作的两个阶段,linux系统产生了下面五种网络模式的方案。
1.阻塞IO
在linux中,默认情况下所有的socket都是阻塞的,在内核数据准备好之前,系统调用会一直等待。具体流程如下:
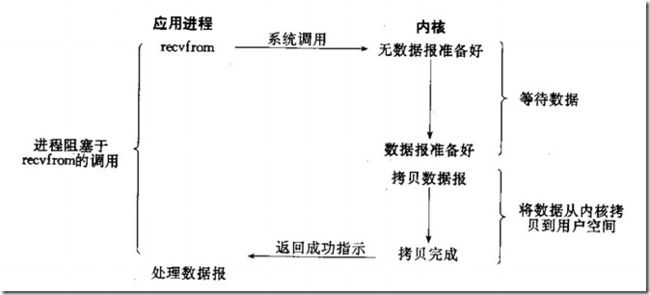
(1)当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。
(2)当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来
2、非阻塞IO
如果内核还未将数据准备好,系统调用仍然会直接返回,并且返回EWOULDBLOCK错误码,具体执行过程如下:
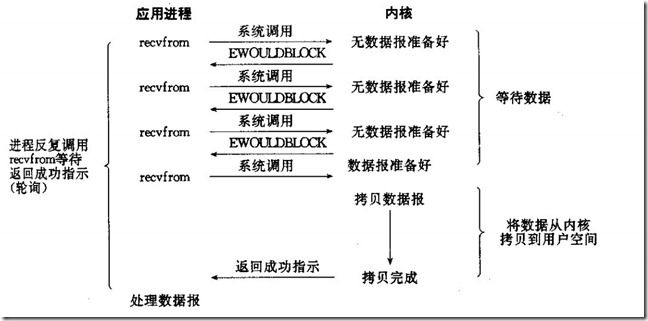
(1)当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。
(2)从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作(这个反复尝试读写文件描述符的过程称为轮询)。
(3)一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
3、信号驱动IO
内核将数据准备好之后,使用SIGIO信号通知程序进行IO操作,其具体过程图如下:

(1)首先开启套接口信号驱动I/O功能,并通过系统调用sigaction执行一个信号处理函数(此系统调用立即返回,进程继续工作,它是非阻塞的)。
(2)当数据准备就绪时,就为该进程生成一个SIGIO信号,通过信号回调通知应用程序调用recvfrom来读取数据,并通知主循环函数处理数据。
4、多路复用IO
支持I/O复用的系统调用有select、poll、epoll、kqueue等
IO多路转接过程中依然是阻塞等待过程,但是与阻塞IO不同的是,它一次可以等待多个文件描述符,当其中任何一个文件描述符上的读或写事件就绪时就返回给用户进程继续工作,所以在效率上优于阻塞IO模型。具体流程图如下:
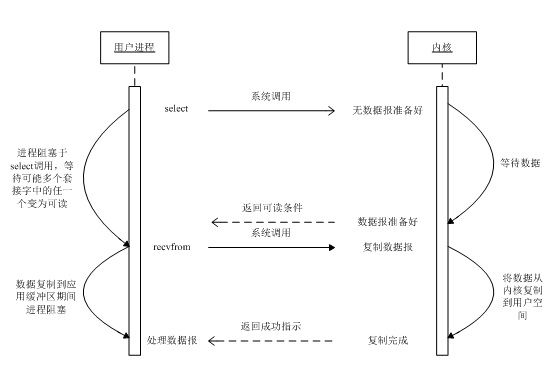
当有很多连接要进行读或者写的时候,用户进程通过将fd_set传递给一个函数,比如select函数,select函数触发了系统调用,进入内核态,内核如果看到有某个fd对应的数据准备好了,就会返回这个fd,select在接收这个返回的过程中一直是阻塞的,当接收到这个返回之后就在用户进程的fdset查找对应fd,然后再执行系统调用,这次系统调用不再是让内核返回就绪文件描述符了,而是让内核读取数据返回,当然这个过程进程也是阻塞的。
在select等待就绪fd的过程中,可以认为是使用了同步阻塞模式,在获取到数据可读的fd之后,再次系统调用是阻塞读取的。其实从select等待就绪fd的过程里面看,Io多路复用相对阻塞IO还有点相似,也是在数据到来之前阻塞,但是呢,IO多路复用的优势就是可以处理多个连接,这对于服务器来说是很重要的。
5、异步IO模型(asynchronous IO)
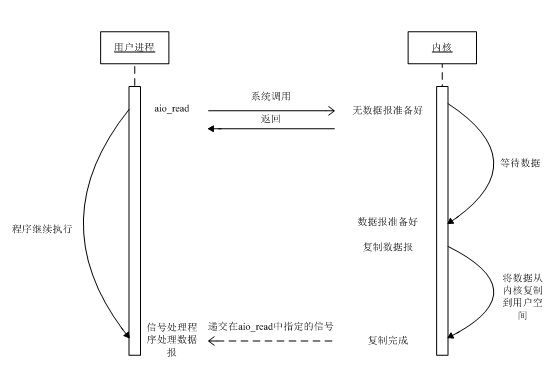
(1)用户进程发起read操作之后,立刻就可以开始去做其它的事。
(2)而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。
(3)然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
异步IO与信号驱动的区别:
信号驱动I/O由内核通知我们何时可以开始一个I/O操作;异步I/O模型由内核通知我们I/O操作何时已经完成。
select和iocp分别对应第4种与第3种模型,那么epoll与kqueue呢?其实也于select属于同一种模型,只是更高级一些,可以看作有了第4种模型的某些特性,如callback机制。
那么,为什么epoll,kqueue比select高级?
答案是,他们无轮询。因为他们用callback取代了。想想看,当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。总结select、poll和epoll 3种多路复用的差异:
select: 单个进程所能打开的最大连接数有FD_SETSIZE宏定义, 其大小为1024或者2048; FD数目剧增后, 会带来性能问题;消息传递从内核到与到用户空间,需要copy数据;
(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
(2)同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大poll: 基本上与select一样, 不同点在于没有FD数目的限制, 因为底层实现不是一个数组, 而是链表;
epoll: FD连接数虽然有限制, 但是很大几乎可以认为无限制;epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题; 内核和用户通过共享内存来传递消息;
redis 多路复用的应用
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程
采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),
且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,
主要由以上几点造就了 Redis 具有很高的吞吐量。
多路I/O复用模型是利用 select、poll、epoll
可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,
当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,
于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
1.单线程 避免了锁 线程之间的互相竞争
2.多路复用
3.内存的读取
-
下面类比到真实的redis线程模型,如图所示
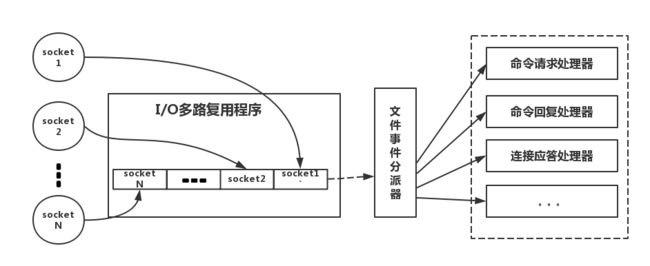
参照上图,简单来说,就是。我们的redis-client在操作的时候,会产生具有不同事件类型的socket。在服务端,有一段I/0多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。
Redis的I/O 多路复用模块
I/O 多路复用模块封装了底层的 select、epoll、avport 以及 kqueue 这些 I/O 多路复用函数,为上层提供了相同的接口
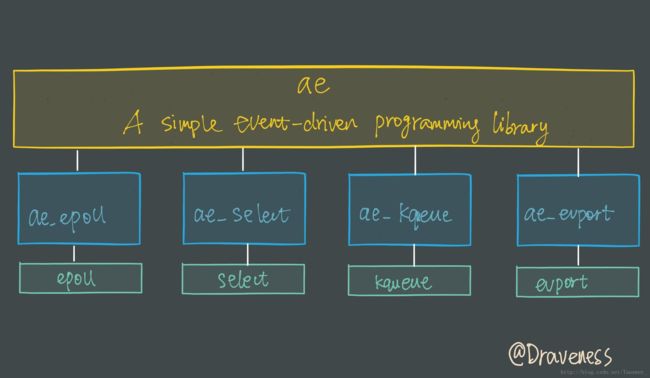
在这里我们简单介绍 Redis 是如何包装 select 和 epoll 的,简要了解该模块的功能,整个 I/O 多路复用模块抹平了不同平台上 I/O 多路复用函数的差异性,提供了相同的接口:
- static int aeApiCreate(aeEventLoop *eventLoop)
- static int aeApiResize(aeEventLoop *eventLoop, int setsize)
- static void aeApiFree(aeEventLoop *eventLoop)
- static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask)
- static void aeApiDelEvent(aeEventLoop *eventLoop, int fd, int mask)
- static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp)
同时,因为各个函数所需要的参数不同,我们在每一个子模块内部通过一个 aeApiState 来存储需要的上下文信息:
// select
typedef struct aeApiState {
fd_set rfds, wfds;
fd_set _rfds, _wfds;
} aeApiState;
// epoll
typedef struct aeApiState {
int epfd;
struct epoll_event *events;
} aeApiState;
这些上下文信息会存储在 eventLoop 的 void *state 中,不会暴露到上层,只在当前子模块中使用。
封装 select 函数
select 可以监控 FD 的可读、可写以及出现错误的情况。
在介绍 I/O 多路复用模块如何对 select 函数封装之前,先来看一下 select 函数使用的大致流程:
int fd = /* file descriptor */
fd_set rfds;
FD_ZERO(&rfds);
FD_SET(fd, &rfds)
for ( ; ; ) {
select(fd+1, &rfds, NULL, NULL, NULL);
if (FD_ISSET(fd, &rfds)) {
/* file descriptor `fd` becomes readable */
}
}
1.初始化一个可读的 fd_set 集合,保存需要监控可读性的 FD;
2.使用 FD_SET将 fd 加入 rfds;
3.调用 select 方法监控 rfds 中的 FD 是否可读;
4.当 select 返回时,检查 FD 的状态并完成对应的操作。
而在 Redis 的 ae_select 文件中代码的组织顺序也是差不多的,首先在 aeApiCreate 函数中初始化 rfds 和 wfds:
static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
if (!state) return -1;
FD_ZERO(&state->rfds);
FD_ZERO(&state->wfds);
eventLoop->apidata = state;
return 0;
}
而 aeApiAddEvent 和 aeApiDelEvent 会通过 FD_SET 和 FD_CLR 修改 fd_set 中对应 FD 的标志位:
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
if (mask & AE_READABLE) FD_SET(fd,&state->rfds);
if (mask & AE_WRITABLE) FD_SET(fd,&state->wfds);
return 0;
}
整个 ae_select 子模块中最重要的函数就是 aeApiPoll,它是实际调用 select 函数的部分,其作用就是在 I/O 多路复用函数返回时,将对应的 FD 加入 aeEventLoop 的 fired 数组中,并返回事件的个数:
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval, j, numevents = 0;
memcpy(&state->_rfds,&state->rfds,sizeof(fd_set));
memcpy(&state->_wfds,&state->wfds,sizeof(fd_set));
retval = select(eventLoop->maxfd+1,
&state->_rfds,&state->_wfds,NULL,tvp);
if (retval > 0) {
for (j = 0; j <= eventLoop->maxfd; j++) {
int mask = 0;
aeFileEvent *fe = &eventLoop->events[j];
if (fe->mask == AE_NONE) continue;
if (fe->mask & AE_READABLE && FD_ISSET(j,&state->_rfds))
mask |= AE_READABLE;
if (fe->mask & AE_WRITABLE && FD_ISSET(j,&state->_wfds))
mask |= AE_WRITABLE;
eventLoop->fired[numevents].fd = j;
eventLoop->fired[numevents].mask = mask;
numevents++;
}
}
return numevents;
}
- 封装 epoll 函数
Redis 对 epoll 的封装其实也是类似的,使用 epoll_create 创建 epoll 中使用的 epfd:
static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
if (!state) return -1;
state->events = zmalloc(sizeof(struct epoll_event)*eventLoop->setsize);
if (!state->events) {
zfree(state);
return -1;
}
state->epfd = epoll_create(1024); /* 1024 is just a hint for the kernel */
if (state->epfd == -1) {
zfree(state->events);
zfree(state);
return -1;
}
eventLoop->apidata = state;
return 0;
}
在 aeApiAddEvent 中使用 epoll_ctl 向 epfd 中添加需要监控的 FD 以及监听的事件
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee = {0}; /* avoid valgrind warning */
/* If the fd was already monitored for some event, we need a MOD
* operation. Otherwise we need an ADD operation. */
int op = eventLoop->events[fd].mask == AE_NONE ?
EPOLL_CTL_ADD : EPOLL_CTL_MOD;
ee.events = 0;
mask |= eventLoop->events[fd].mask; /* Merge old events */
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.fd = fd;
if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1;
return 0;
}
由于 epoll 相比 select 机制略有不同,在 epoll_wait 函数返回时并不需要遍历所有的 FD 查看读写情况;在 epoll_wait 函数返回时会提供一个 epoll_event 数组:
typedef union epoll_data {
void *ptr;
int fd; /* 文件描述符 */
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll 事件 */
epoll_data_t data;
};
aeApiPoll 函数只需要将 epoll_event 数组中存储的信息加入 eventLoop 的 fired 数组中,将信息传递给上层模块:
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval, numevents = 0;
retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);
if (retval > 0) {
int j;
numevents = retval;
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = state->events+j;
if (e->events & EPOLLIN) mask |= AE_READABLE;
if (e->events & EPOLLOUT) mask |= AE_WRITABLE;
if (e->events & EPOLLERR) mask |= AE_WRITABLE;
if (e->events & EPOLLHUP) mask |= AE_WRITABLE;
eventLoop->fired[j].fd = e->data.fd;
eventLoop->fired[j].mask = mask;
}
}
return numevents;
}
子模块的选择
因为 Redis 需要在多个平台上运行,同时为了最大化执行的效率与性能,所以会根据编译平台的不同选择不同的 I/O 多路复用函数作为子模块,提供给上层统一的接口;在 Redis 中,我们通过宏定义的使用,合理的选择不同的子模块:
因为 select 函数是作为 POSIX 标准中的系统调用,在不同版本的操作系统上都会实现,所以将其作为保底方案:
Redis 会优先选择时间复杂度为 O(1) 的 I/O 多路复用函数作为底层实现,包括 Solaries 10 中的 evport、Linux 中的
epoll 和 macOS/FreeBSD 中的
kqueue,上述的这些函数都使用了内核内部的结构,并且能够服务几十万的文件描述符。
但是如果当前编译环境没有上述函数,就会选择 select 作为备选方案,由于其在使用时会扫描全部监听的描述符,所以其时间复杂度较差 O(n),并且只能同时服务 1024 个文件描述符,所以一般并不会以 select 作为第一方案使用。