map-reduce 是 hadoop 的核心概念之一,hadoop 权威指南中以一个天气数据处理的例子说明了 map-reduce 的好处:
- map 阶段将工作划分为可以并行的部分并进行调度;
- 在 reduce 阶段提供了方便的数据整合方式
- 可以将任务分散到多个机器上并行执行,加快任务执行速度
1 map-reduce 的过程
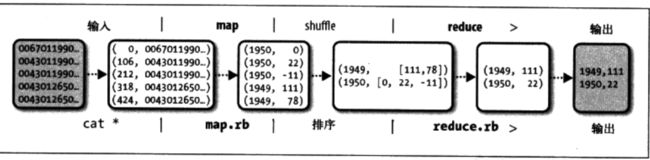
先分别读入数据,得到一个局部的解,然后通过 shuffle,将 key 相同的数据整合起来,最终在 reduce 阶段合并起来,输出数据。
map 示例:
public class MaxTemperatureMapper extends
Mapper {
public static final int MISSING = 9999;
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+') {
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
reduce 代码,注意 reduce 的输入类型与 map 的输出类型要保持一致:
public class MaxTemperatureReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int maxvalue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxvalue = Math.max(maxvalue, value.get());
}
context.write(key, new IntWritable(maxvalue));
}
}
最后将 map-reduce 结合起来:
public class MaxTemperature {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args.length != 2) {
System.out.println("Usage: MaxTemperature ");
System.exit(-1);
}
Job job = Job.getInstance();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max Temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
//combiner 其实也是一个reducer
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2 数据流
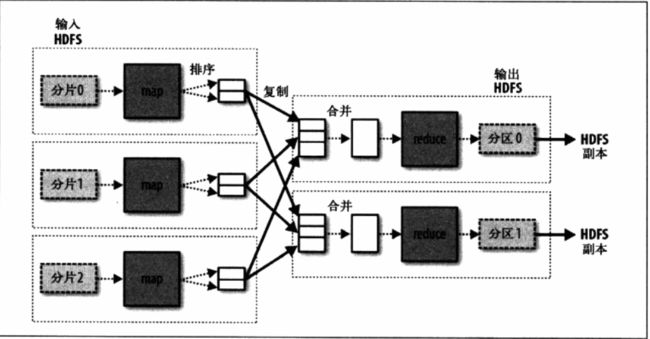
Job 是 hadoop 运行任务的基础单位,job 会被分为 task 来运行,task 会由 YARN 调度在集群的节点上运行,通常每个 task 处理的任务大小最好和 hdfs 的 block 大小相同,防止由于 task 所需数据分布在不同节点所引起的数据交换开销。
map 完成后,数据被写入本地硬盘,而后被发送给 reducer。reducer 可以有一个,也可以有多个,同一个 key 对应的数据将会被发送到同一个 reducer 处理。同时,对于没有必要进行 reduce 操作的 job,也可以没有 reducer。
3 combiner Functions
有些情况下,map 输出的数据可以先进行预先处理,以减少向 reducer 传递的数据。例如在统计每年的最高温度时,同一个 split 输出了若干 key相同的记录:(1950, 0),(1950,20),(1950,10) ,则可以先在 split 内统计出最大值(1950,20),从而减少了数据的传输。注意,combiner 不保证会被执行,所以一定要保证是否存在 combiner 输出的结果都不会有变化。
//通过该方法可以设置 combiner,combiner 其实也是一个 reducer
job.setCombinerClass(MaxTemperatureReducer.class);
4 hadoop streaming
hadoop streaming 提供了一种用其他语言写 map-reduce 的 api,主要是使用了输入输出重定向,个人感觉意义不大。