本文将从一个 Native Crash 分析入手,带大家了解一下我们平时开发中常用容易忽略但是又很值得学习底层源码知识。
一、问题起因
最近在项目中遇到一个 native crash,引起 crash 的代码如下所示:
jstring stringTojstring(JNIEnv* env, string str)
{
int len = str.length();
wchar_t *wcs = new wchar_t[len * 2];
int nRet = UTF82Unicode(str.c_str(), wcs, len);
jchar* jcs = new jchar[nRet];
for (int i = 0; i < nRet; i++)
{
jcs[i] = (jchar) wcs[i];
}
jstring retString = env->NewString(jcs, nRet);
delete[] wcs;
delete[] jcs;
return retString;
}
这段代码的目的是用来将 c++ 里面的 string 类型转成 jni 层的 jstring 对象,引发崩溃的代码行是 env->NewString(jcs, nRet),最后跟踪到的原因是 Native 层通过 env->CallIntMethod 的方式调用到了 Java 方法,而 Java 方法内部抛出了 Exception,Native 层未及时通过 env->ExceptionClear 清除这个异常就直接调用了 stringTojstring 方法,最终导致 env->NewString(jcs, nRet) 这行代码抛出异常。
二、代码分析与问题发掘
这个 crash 最后的解决方法是及时调用 env->ExceptionClear 清除这个异常即可。回头详细分析这个函数,新的疑惑就出现了,为什么会存在这么一个转换函数,我们知道将 c++ 里面的 string 类型转成 jni 层的 jstring 类型有一个更加简便的函数 env->NewStringUTF(str.c_str()),为什么不直接调用这个函数,而需要通过这么复杂的步骤进行 string 到 jstring 的转换,接下来我们会仔细分析相关源码来解答这个疑惑。先把相关的几个函数源码贴出来:
inline int UTF82UnicodeOne(const char* utf8, wchar_t& wch)
{
//首字符的Ascii码大于0xC0才需要向后判断,否则,就肯定是单个ANSI字符了
unsigned char firstCh = utf8[0];
if (firstCh >= 0xC0)
{
//根据首字符的高位判断这是几个字母的UTF8编码
int afters, code;
if ((firstCh & 0xE0) == 0xC0)
{
afters = 2;
code = firstCh & 0x1F;
}
else if ((firstCh & 0xF0) == 0xE0)
{
afters = 3;
code = firstCh & 0xF;
}
else if ((firstCh & 0xF8) == 0xF0)
{
afters = 4;
code = firstCh & 0x7;
}
else if ((firstCh & 0xFC) == 0xF8)
{
afters = 5;
code = firstCh & 0x3;
}
else if ((firstCh & 0xFE) == 0xFC)
{
afters = 6;
code = firstCh & 0x1;
}
else
{
wch = firstCh;
return 1;
}
//知道了字节数量之后,还需要向后检查一下,如果检查失败,就简单的认为此UTF8编码有问题,或者不是UTF8编码,于是当成一个ANSI来返回处理
for(int k = 1; k < afters; ++ k)
{
if ((utf8[k] & 0xC0) != 0x80)
{
//判断失败,不符合UTF8编码的规则,直接当成一个ANSI字符返回
wch = firstCh;
return 1;
}
code <<= 6;
code |= (unsigned char)utf8[k] & 0x3F;
}
wch = code;
return afters;
}
else
{
wch = firstCh;
}
return 1;
}
int UTF82Unicode(const char* utf8Buf, wchar_t *pUniBuf, int utf8Leng)
{
int i = 0, count = 0;
while(i < utf8Leng)
{
i += UTF82UnicodeOne(utf8Buf + i, pUniBuf[count]);
count ++;
}
return count;
}
jstring stringTojstring(JNIEnv* env, string str)
{
int len = str.length();
wchar_t *wcs = new wchar_t[len * 2];
int nRet = UTF82Unicode(str.c_str(), wcs, len);
jchar* jcs = new jchar[nRet];
for (int i = 0; i < nRet; i++)
{
jcs[i] = (jchar) wcs[i];
}
jstring retString = env->NewString(jcs, nRet);
delete[] wcs;
delete[] jcs;
return retString;
}
由于无法找到代码的出处和作者,所以现在我们只能通过源码去推测意图。
首先我们先看第一个函数 UTF82Unicode,这个函数顾名思义是将 utf-8 编码转成 unicode(utf-16) 编码。然后分析第二个函数 UTF82UnicodeOne,这个函数看起来会比较费解,因为这涉及到 utf-16 与 utf-8 编码转换的知识,所以我们先来详细了解一下这两种常用编码。
三、utf-16 与 utf-8 编码
首先需要明确的一点是我们平时说的 unicode 编码其实指的是 ucs-2 或者 utf-16 编码,unicode 真正是一个业界标准,它对世界上大部分的文字系统进行了整理、编码,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。所以严格意义上讲 utf-8、utf-16 和 ucs-2 编码都是 unicode 字符集的一种实现方式,只不过前两者是变长编码,后者则是定长。
utf-8 编码最大的特点就是变长编码,它使用 1~4 个字节来表示一个符号,根据符号不同动态变换字节的长度;
ucs-2 编码最大的特点就是定长编码,它规定统一使用 2 个字节来表示一个符号;
utf-16 也是变长编码,用 2 个或者 4 个字节来代表一个字符,在基本多文种平面集上和 ucs-2 表现一样;
unicode 字符集是 ISO(国际标准化组织)国际组织推行的,我们知道英文的 26 个字母加上其他的英文基本符号通过 ASCII 编码就完全足够了,可是像中文这种有上万个字符的语种来说 ASCII 就完全不够用了,所以为了统一全世界不同国家的编码,他们废了所有的地区性编码方案,重新收集了绝大多数文化中所有字母和符号的编码,命名为 "Universal Multiple-Octet Coded Character Set",简称 UCS, 俗称 "unicode",unicode 与 utf-8 编码的对应关系:
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
那么既然都已经推出了 unicode 统一编码字符集,为什么不统一全部使用 ucs-2/utf-16 编码呢?这是因为其实对于英文使用国家来说,字符基本上都是 ASCII 字符,使用 utf-8 编码一个字节代表一个字符很常见,如果使用 ucs-2/utf-16 编码反而会浪费空间。
除了上面介绍到的几种编码方式,还有 utf-32 编码,也被称为 ucs-4 编码,它对于每个字符统一使用 4 个字节来表示。需要注意的是,utf-16 编码是 ucs-2 编码的扩展(在 unicode 引入字符平面集概念之前,他们是一样的),ucs-2 编码在基本多文种平面字符集上和 utf-16 结果一致,但是 utf-16 编码可以使用 4 个字节来表示基本多文种平面之外的字符集,前两个字节称为前导代理,后两个字节称为后尾代理,这两个代理构成一个代理对。unicode 总共有 17 个字符平面集:
| 平面 | 始末字符值 | 中文名称 | 英文名称 |
|---|---|---|---|
| 0号平面 | U+0000 - U+FFFF | 基本多文种平面 | BMP |
| 1号平面 | U+10000 - U+1FFFF | 多文种补充平面 | SMP |
| 2号平面 | U+20000 - U+2FFFF | 表意文字补充平面 | SIP |
| 3号平面 | U+30000 - U+3FFFF 表意文字第三平面 | TIP | |
| 4~13号平面 | U+40000 - U+DFFFF | (尚未使用) | |
| 14号平面 | U+E0000 - U+EFFFF | 特别用途补充平面 | SSP |
| 15号平面 | U+F0000 - U+FFFFF | 保留作为私人使用区(A区) | PUA-A |
| 16号平面 | U+100000 - U+10FFFF | 保留作为私人使用区(B区) | PUA-B |
通过上面介绍的内容,我们应该基本了解了几种编码方式的概念和区别,其中最重要的是要记住 utf-8 编码和 utf-16 编码之间的转换公式,后面我们马上就会用到。
四、NewString 与 NewStringUTF 源码分析
我们回到上面的问题:为什么不直接使用 env->NewStringUTF,而是需要先做一个 utf-8 编码到 utf-16 编码的转换,将转换之后的值通过 env->NewString 生成一个 jstring 呢?应该可以确定是作者有意为之,于是我们下沉到源码中去寻找问题的答案。
因为 dalvik 和 ART 的行为表现是有差异的,所以我们有必要来了解一下两者的实现:
4.1、 dalvik 源码解析
首先我们来分析一下 dalvik 中这两个函数的源码,他们的调用时序如下图所示:


可见,NewString 和 NewStringUTF 的调用过程很相似,最大区别在于后者会有额外的 dvmConvertUtf8ToUtf16 操作,接下来我们按照流程剖析每一个方法的源码。这两个函数定义都在 jni.h 文件中,对应的实现在 jni.cpp 文件中(这里选取的是 Android 4.3.1 的源码):
/*
* Create a new String from Unicode data.
*/
static jstring NewString(JNIEnv* env, const jchar* unicodeChars, jsize len) {
ScopedJniThreadState ts(env);
StringObject* jstr = dvmCreateStringFromUnicode(unicodeChars, len);
if (jstr == NULL) {
return NULL;
}
dvmReleaseTrackedAlloc((Object*) jstr, NULL);
return (jstring) addLocalReference(ts.self(), (Object*) jstr);
}
....
/*
* Create a new java.lang.String object from chars in modified UTF-8 form.
*/
static jstring NewStringUTF(JNIEnv* env, const char* bytes) {
ScopedJniThreadState ts(env);
if (bytes == NULL) {
return NULL;
}
/* note newStr could come back NULL on OOM */
StringObject* newStr = dvmCreateStringFromCstr(bytes);
jstring result = (jstring) addLocalReference(ts.self(), (Object*) newStr);
dvmReleaseTrackedAlloc((Object*)newStr, NULL);
return result;
}
可以看到这两个函数步骤是类似的,先创建一个 StringObject 对象,然后将它加入到 localReference table 中。两个函数的差别在于生成 StringObject 对象的函数不一样, NewString 调用的是 dvmCreateStringFromUnicode,NewStringUTF 则调用了 dvmCreateStringFromCstr。于是我们继续分析 dvmCreateStringFromUnicode 和 dvmCreateStringFromCstr 这两个函数,他们的实现是在 UtfString.c 中:
/*
* Create a new java/lang/String object, using the given Unicode data.
*/
StringObject* dvmCreateStringFromUnicode(const u2* unichars, int len)
{
/* We allow a NULL pointer if the length is zero. */
assert(len == 0 || unichars != NULL);
ArrayObject* chars;
StringObject* newObj = makeStringObject(len, &chars);
if (newObj == NULL) {
return NULL;
}
if (len > 0) memcpy(chars->contents, unichars, len * sizeof(u2));
u4 hashCode = computeUtf16Hash((u2*)(void*)chars->contents, len);
dvmSetFieldInt((Object*)newObj, STRING_FIELDOFF_HASHCODE, hashCode);
return newObj;
}
....
StringObject* dvmCreateStringFromCstr(const char* utf8Str) {
assert(utf8Str != NULL);
return dvmCreateStringFromCstrAndLength(utf8Str, dvmUtf8Len(utf8Str));
}
/*
* Create a java/lang/String from a C string, given its UTF-16 length
* (number of UTF-16 code points).
*/
StringObject* dvmCreateStringFromCstrAndLength(const char* utf8Str,
size_t utf16Length)
{
assert(utf8Str != NULL);
ArrayObject* chars;
StringObject* newObj = makeStringObject(utf16Length, &chars);
if (newObj == NULL) {
return NULL;
}
dvmConvertUtf8ToUtf16((u2*)(void*)chars->contents, utf8Str);
u4 hashCode = computeUtf16Hash((u2*)(void*)chars->contents, utf16Length);
dvmSetFieldInt((Object*) newObj, STRING_FIELDOFF_HASHCODE, hashCode);
return newObj;
}
这两个函数流程类似,首先通过 makeStringObject 函数生成 StringObjcet 对象并且根据类型分配内存,然后通过 memcpy 或者 dvmConvertUtf8ToUtf16 函数分别将 jchar 数组或者 char 数组的内容设置到这个对象中,最后将计算好的 hash 值也设置到 StringObject 对象中。很明显的区别就在于 memcpy 函数和 dvmConvertUtf8ToUtf16 函数,我们对比一下这两个函数。
memcpy 函数这里就不分析了,内存拷贝函数,将 unichars 指向的 jchar 数组拷贝到 StringObject 内容区域中;dvmConvertUtf8ToUtf16 函数我们仔细分析一下:
/*
* Convert a "modified" UTF-8 string to UTF-16.
*/
void dvmConvertUtf8ToUtf16(u2* utf16Str, const char* utf8Str)
{
while (*utf8Str != '\0')
*utf16Str++ = dexGetUtf16FromUtf8(&utf8Str);
}
通过注释我们可以看到,这个函数用来将 utf-8 编码转换成 utf-16 编码,继续跟到 dexGetUtf16FromUtf8 函数中,这个函数在 DexUtf.h 文件中:
/*
* Retrieve the next UTF-16 character from a UTF-8 string.
*/
DEX_INLINE u2 dexGetUtf16FromUtf8(const char** pUtf8Ptr)
{
unsigned int one, two, three;
one = *(*pUtf8Ptr)++;
if ((one & 0x80) != 0) {
/* two- or three-byte encoding */
two = *(*pUtf8Ptr)++;
if ((one & 0x20) != 0) {
/* three-byte encoding */
three = *(*pUtf8Ptr)++;
return ((one & 0x0f) << 12) |
((two & 0x3f) << 6) |
(three & 0x3f);
} else {
/* two-byte encoding */
return ((one & 0x1f) << 6) |
(two & 0x3f);
}
} else {
/* one-byte encoding */
return one;
}
}
这段代码的核心就是我们上面提到的 utf-8 和 utf-16 转换的公式。我们详细解析一下这个函数,先假设传递过来的字符串是“a中文”,对应 utf-8 编码十六进制是 "0x610xE40xB80xAD0xE60x960x87",转换步骤如下:
- 先执行一个语句
one = *(*pUtf8Ptr)++;将入参char** pUtf8Ptr解引用,获取字符串指针,再解一次,并将指针后移,其实就是获取字符代表的 'a'(0x61),然后 0x61&0x80 = 0x00,说明这是单字节的 utf-8 字符,返回 0x61 给上层,由于上层是 u2(typedef uint16_t u2),所以上层将结果存储为 0x000x61; - 外层循环继续执行该函数,走到了第二个字符 0xE4,0xE4&0x80 = 0x80,表示其为双字节或三字节的 utf-8 编码,继续走到下一个字节 0xB8,0xB8&0x20 = 0x20,代表是三字节编码的 utf-8 编码,然后执行
((one & 0x0f) << 12) | ((two & 0x3f) << 6) | (three & 0x3f);,这个语句对应的就是 utf-8 与 utf-16 的转换公式,最后返回结果是 0x4E2D,这个也是 “中” 的 unicode 字符集,返回给外层存储为 0x4E2D; - 外层地址继续往后自增,再次执行到该函数时,one 字符就成了 0xE6,此时步骤和第二步类似,返回结果是 0x6587,外层存储为 0x6587,代表 unicode 中的 “文”;
- 函数执行完成后, utf-8 编码就被转成了 utf-16 编码。
回顾整个过程我们可以发现,NewString 和 NewStringUTF 生成的 jstring 对象都是 utf-16 编码,所以这里我们可以得出一个推论:在 dalvik 虚拟机中,native 方法创建的 String 对象都是 utf-16 编码。那么 Java 类中创建的 String 对象是什么编码呢?其实也是 utf-16,后面我们会证实这个推论。
4.2 ART 源码分析
分析完 dalvik 源码之后,我们来分析一下 ART 的相关源码(这里选取的是 Android 8.0 源码),同样的流程,先是两个函数的调用时序图:


这两个函数实现在 jni_internal.cc 文件中:
static jstring NewString(JNIEnv*env, const jchar*chars, jsize char_count) {
if (UNLIKELY(char_count < 0)) {
JavaVmExtFromEnv(env)->JniAbortF("NewString", "char_count < 0: %d", char_count);
return nullptr;
}
if (UNLIKELY(chars == nullptr && char_count > 0)) {
JavaVmExtFromEnv(env)->JniAbortF("NewString", "chars == null && char_count > 0");
return nullptr;
}
ScopedObjectAccess soa (env);
mirror::String * result = mirror::String::AllocFromUtf16(soa.Self(), char_count, chars);
return soa.AddLocalReference < jstring > (result);
}
...
static jstring NewStringUTF(JNIEnv*env, const char*utf) {
if (utf == nullptr) {
return nullptr;
}
ScopedObjectAccess soa (env);
mirror::String * result = mirror::String::AllocFromModifiedUtf8(soa.Self(), utf);
return soa.AddLocalReference < jstring > (result);
}
可以看到他们调用的函数分别是 AllocFromUtf16 和 AllocFromModifiedUtf8,这两个函数在 string.cc 文件中:
String*String::AllocFromUtf16(Thread*self, int32_t utf16_length, const uint16_t*utf16_data_in) {
CHECK(utf16_data_in != nullptr || utf16_length == 0);
gc::AllocatorType allocator_type = Runtime::Current () -> GetHeap()->GetCurrentAllocator();
const bool compressible = kUseStringCompression &&
String::AllASCII < uint16_t > (utf16_data_in, utf16_length);
int32_t length_with_flag = String::GetFlaggedCount (utf16_length, compressible);
SetStringCountVisitor visitor (length_with_flag);
ObjPtr string = Alloc < true > (self, length_with_flag, allocator_type, visitor);
if (UNLIKELY(string == nullptr)) {
return nullptr;
}
if (compressible) {
for (int i = 0; i < utf16_length; ++i) {
string -> GetValueCompressed()[i] = static_cast < uint8_t > (utf16_data_in[i]);
}
} else {
uint16_t * array = string -> GetValue();
memcpy(array, utf16_data_in, utf16_length * sizeof(uint16_t));
}
return string.Ptr();
}
....
String* String::AllocFromModifiedUtf8(Thread* self, const char* utf) {
DCHECK(utf != nullptr);
size_t byte_count = strlen(utf);
size_t char_count = CountModifiedUtf8Chars(utf, byte_count);
return AllocFromModifiedUtf8(self, char_count, utf, byte_count);
}
String* String::AllocFromModifiedUtf8(Thread* self,
int32_t utf16_length,
const char* utf8_data_in,
int32_t utf8_length) {
gc::AllocatorType allocator_type = Runtime::Current()->GetHeap()->GetCurrentAllocator();
const bool compressible = kUseStringCompression && (utf16_length == utf8_length);
const int32_t utf16_length_with_flag = String::GetFlaggedCount(utf16_length, compressible);
SetStringCountVisitor visitor(utf16_length_with_flag);
ObjPtr string = Alloc(self, utf16_length_with_flag, allocator_type, visitor);
if (UNLIKELY(string == nullptr)) {
return nullptr;
}
if (compressible) {
memcpy(string->GetValueCompressed(), utf8_data_in, utf16_length * sizeof(uint8_t));
} else {
uint16_t* utf16_data_out = string->GetValue();
ConvertModifiedUtf8ToUtf16(utf16_data_out, utf16_length, utf8_data_in, utf8_length);
}
return string.Ptr();
}
CountModifiedUtf8Chars 和 ConvertModifiedUtf8ToUtf16 函数在 utf.cc 文件中:
/*
* This does not validate UTF8 rules (nor did older code). But it gets the right answer
* for valid UTF-8 and that's fine because it's used only to size a buffer for later
* conversion.
*
* Modified UTF-8 consists of a series of bytes up to 21 bit Unicode code points as follows:
* U+0001 - U+007F 0xxxxxxx
* U+0080 - U+07FF 110xxxxx 10xxxxxx
* U+0800 - U+FFFF 1110xxxx 10xxxxxx 10xxxxxx
* U+10000 - U+1FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
*
* U+0000 is encoded using the 2nd form to avoid nulls inside strings (this differs from
* standard UTF-8).
* The four byte encoding converts to two utf16 characters.
*/
size_t CountModifiedUtf8Chars(const char* utf8, size_t byte_count) {
DCHECK_LE(byte_count, strlen(utf8));
size_t len = 0;
const char* end = utf8 + byte_count;
for (; utf8 < end; ++utf8) {
int ic = *utf8;
len++;
if (LIKELY((ic & 0x80) == 0)) {
// One-byte encoding.
continue;
}
// Two- or three-byte encoding.
utf8++;
if ((ic & 0x20) == 0) {
// Two-byte encoding.
continue;
}
utf8++;
if ((ic & 0x10) == 0) {
// Three-byte encoding.
continue;
}
// Four-byte encoding: needs to be converted into a surrogate
// pair.
utf8++;
len++;
}
return len;
}
void ConvertModifiedUtf8ToUtf16(uint16_t* utf16_data_out, size_t out_chars,
const char* utf8_data_in, size_t in_bytes) {
const char *in_start = utf8_data_in;
const char *in_end = utf8_data_in + in_bytes;
uint16_t *out_p = utf16_data_out;
if (LIKELY(out_chars == in_bytes)) {
// Common case where all characters are ASCII.
for (const char *p = in_start; p < in_end;) {
// Safe even if char is signed because ASCII characters always have
// the high bit cleared.
*out_p++ = dchecked_integral_cast(*p++);
}
return;
}
// String contains non-ASCII characters.
for (const char *p = in_start; p < in_end;) {
const uint32_t ch = GetUtf16FromUtf8(&p);
const uint16_t leading = GetLeadingUtf16Char(ch);
const uint16_t trailing = GetTrailingUtf16Char(ch);
*out_p++ = leading;
if (trailing != 0) {
*out_p++ = trailing;
}
}
}
首先, AllocFromUtf16 函数中是简单的赋值或者 memcpy 操作,而 AllocFromModifiedUtf8 函数则是根据 compressible 变量来选择调用 memcpy 或者 ConvertModifiedUtf8ToUtf16 函数。AllocFromUtf16 和 ConvertModifiedUtf8ToUtf16 这两个函数中都有对 compressible 这个变量的判断,看看这个变量的赋值过程,首先是 AllocFromUtf16 函数 :
const bool compressible = kUseStringCompression && String::AllASCII < uint16_t > (utf16_data_in, utf16_length)
Android 8.0 源码中 kUseStringCompression 该变量设置的值为 TRUE,所以如果字符全是 ASCII 则 compressible 变量也为 TRUE,但是很重要的一点是 Android 8.0 以下并没有针对 compressible 变量的判断,所有逻辑统一执行 ConvertModifiedUtf8ToUtf16 操作;再来看一下 AllocFromModifiedUtf8 函数对于 compressible 的赋值操作:
const bool compressible = kUseStringCompression && (utf16_length == utf8_length);
如果 utf-8 编码的字符串中字符数和字节数相等,即字符串都是 utf-8 单字节字符,那么直接执行 memcpy 函数进行拷贝;如果不相等,即字符串不都是 utf-8 单字节字符,需要经过函数 ConvertModifiedUtf8ToUtf16 将 utf-8 编码转换成 utf-16 编码。现在我们来着重分析这个过程,AllocFromModifiedUtf8 对于存在非 ASCII 编码的字符会执行到下面的一个 for 循环中,在循环中分别执行了 GetUtf16FromUtf8、GetLeadingUtf16Char 和 GetTrailingUtf16Char 函数,这三个函数在 utf-inl.h 中:
inline uint16_t GetTrailingUtf16Char(uint32_t maybe_pair) {
return static_cast(maybe_pair >> 16);
}
inline uint16_t GetLeadingUtf16Char(uint32_t maybe_pair) {
return static_cast(maybe_pair & 0x0000FFFF);
}
inline uint32_t GetUtf16FromUtf8(const char** utf8_data_in) {
const uint8_t one = *(*utf8_data_in)++;
if ((one & 0x80) == 0) {
// one-byte encoding
return one;
}
const uint8_t two = *(*utf8_data_in)++;
if ((one & 0x20) == 0) {
// two-byte encoding
return ((one & 0x1f) << 6) | (two & 0x3f);
}
const uint8_t three = *(*utf8_data_in)++;
if ((one & 0x10) == 0) {
return ((one & 0x0f) << 12) | ((two & 0x3f) << 6) | (three & 0x3f);
}
// Four byte encodings need special handling. We'll have
// to convert them into a surrogate pair.
const uint8_t four = *(*utf8_data_in)++;
// Since this is a 4 byte UTF-8 sequence, it will lie between
// U+10000 and U+1FFFFF.
//
// TODO: What do we do about values in (U+10FFFF, U+1FFFFF) ? The
// spec says they're invalid but nobody appears to check for them.
const uint32_t code_point = ((one & 0x0f) << 18) | ((two & 0x3f) << 12)
| ((three & 0x3f) << 6) | (four & 0x3f);
uint32_t surrogate_pair = 0;
// Step two: Write out the high (leading) surrogate to the bottom 16 bits
// of the of the 32 bit type.
surrogate_pair |= ((code_point >> 10) + 0xd7c0) & 0xffff;
// Step three : Write out the low (trailing) surrogate to the top 16 bits.
surrogate_pair |= ((code_point & 0x03ff) + 0xdc00) << 16;
return surrogate_pair;
}
GetUtf16FromUtf8 函数首先判断字符是几个字节编码,如果是四字节编码需要特殊处理,转换成代理对(surrogate pair);
GetTrailingUtf16Char 和 GetLeadingUtf16Char 逻辑就很简单了,获取返回字符串的低两位字节和高两位字节,如果高两位字节不为空就组合成一个四字节 utf-16 编码的字符并返回。所以最后得出的结论就是:AllocFromModifiedUtf8 函数返回的结果要么全是 ASCII 字符的 utf-8 编码字符串,要么就是 utf-16 编码的字符串。
分析到此处,我们可以知道 Android 8.0 及以上版本,在 Native 层创建 String 对象时,如果内容全部为 ASCII 字符,String 就是 utf-8 编码,否则为 utf-16 编码。那么通过 Java 层创建的 String 对象呢?其实和从 Native 层创建的 String 对象情况一致,接下来我们会验证。
五、 推论验证
上面我们提出了两个推论:
- Dalvik 中,String 对象编码方式为 utf-16 编码;
- ART 中,String 对象编码方式为 utf-16 编码,但是有一个情况除外:如果 String 对象全部为 ASCII 字符并且 Android 系统为 8.0 及之上版本,String 对象的编码则为 utf-8;
为了验证上面的推论,我们用两种方式来论证:
5.1、 获取 String 对象中字符占用字节数
首先想到最直接的方式就是在 Android 4.3 的手机上获取一个 String 字符串的占用字节数,测试代码如下所示:
String str = "hello from jni中文";
byte[] bytes = str.getBytes();
最后观察一下 byte[] 数组的大小,最后发现是 20,并不是 32,也就是说该字符串是 utf-8 编码,并不是 utf-16 编码,和之前得出的结论不一致;我们同样在 Android 6.0 手机上执行相同的代码,发现大小同样是 20。具体什么原因呢,我们来看一下 getBytes 源码(分别在 String.java 与 Charset.java 类中):
/**
* Encodes this {@code String} into a sequence of bytes using the
* platform's default charset, storing the result into a new byte array.
*
* The behavior of this method when this string cannot be encoded in
* the default charset is unspecified. The {@link
* java.nio.charset.CharsetEncoder} class should be used when more control
* over the encoding process is required.
*
* @return The resultant byte array
*
* @since JDK1.1
*/
public byte[] getBytes() {
return getBytes(Charset.defaultCharset());
}
/**
* Returns the default charset of this Java virtual machine.
*
* Android note: The Android platform default is always UTF-8.
*
* @return A charset object for the default charset
*
* @since 1.5
*/
public static Charset defaultCharset() {
// Android-changed: Use UTF_8 unconditionally.
synchronized (Charset.class) {
if (defaultCharset == null) {
defaultCharset = java.nio.charset.StandardCharsets.UTF_8;
}
return defaultCharset;
}
}
通过源码已经可以清晰的看到使用 getBytes 函数获取的是 utf-8 编码的字符串。那么我们怎么知晓 Java 层 String 真正的编码格式呢,可不可以直接查看对象的内存占用?我们来试一下,通过 Android Profiler 的 Dump Java Heap 功能我们可以清楚的看到一个对象占用的内存,首先通过 String str = "hello from jni中文" 代码简单的创建一个 String 对象,然后通过 Android Profiler 工具查看这个对象的内存占用,切换到 App Heap 与 Arrange by callstack,找到创建的 String 对象:


可以看到对象占用大小是 48 个字节,其中 char 数组占用的字节是 32,每个字符都是占用两字节,这个行为在 Android 8.0 之前的版本一致,所以我们可以很明确地推断在 Android 8.0 之前通过上述方式创建的 String 对象都是 utf-16 编码。
另外我们同时验证一下在 Android 8.0 版本及以上全为 ASCII 字符的 String 对象内存占用详细情况,测试代码为 String output = "hello from jni":
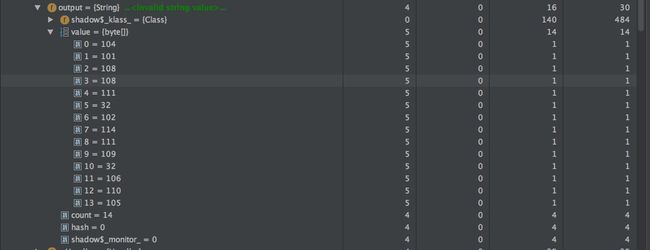
可以看到占用字节数是 14,也就是单字节的 utf-8 编码,所以我们的推论 2 也成立。
上面分析完通过 String str = "hello from jni中文" 方式创建的 String 对象是 utf-16 编码,另外,String 对象还有一种创建方式:通过 new String(byte[] bytes),我们来直接分析源码:
public String(byte[] data, int high, int offset, int byteCount) {
if ((offset | byteCount) < 0 || byteCount > data.length - offset) {
throw failedBoundsCheck(data.length, offset, byteCount);
}
this.offset = 0;
this.value = new char[byteCount];
this.count = byteCount;
high <<= 8;
for (int i = 0; i < count; i++) {
value[i] = (char) (high + (data[offset++] & 0xff));
}
}
通过代码我们可以知道,因为 char 为双字节,high 对应的是高位字节,(data[offset++] & 0xff) 则为低位字节,所以我们可以得出结论,String 对象通过这种情况下创建的同样是 utf-16 编码。
5.2、 官方资料
通过 5.1 小节的分析,我们已经可以通过实际表现来支撑我们上面的两点推论,作为补充,我们同时查阅相关官方资料来对这些推论得到更加全面的认识:
一、 How is text represented in the Java platform?
The Java programming language is based on the Unicode character set, and several libraries implement the Unicode standard. Unicode is an international character set standard which supports all of the major scripts of the world, as well as common technical symbols. The original Unicode specification defined characters as fixed-width 16-bit entities, but the Unicode standard has since been changed to allow for characters whose representation requires more than 16 bits. The range of legal code points is now U+0000 to U+10FFFF. An encoding defined by the standard, UTF-16, allows to represent all Unicode code points using one or two 16-bit units.
The primitive data type char in the Java programming language is an unsigned 16-bit integer that can represent a Unicode code point in the range U+0000 to U+FFFF, or the code units of UTF-16. The various types and classes in the Java platform that represent character sequences - char[], implementations of java.lang.CharSequence (such as the String class), and implementations of java.text.CharacterIterator - are UTF-16 sequences. Most Java source code is written in ASCII, a 7-bit character encoding, or ISO-8859-1, an 8-bit character encoding, but is translated into UTF-16 before processing.
The Character class as an object wrapper for the char primitive type. The Character class also contains static methods such as isLowerCase() and isDigit() for determining the properties of a character. Since J2SE 5, these methods have overloads that accept either a char (which allows representation of Unicode code points in the range U+0000 to U+FFFF) or an int (which allows representation of all Unicode code points).
我们重点看这一句
The various types and classes in the Java platform that represent character sequences - char[], implementations of java.lang.CharSequence (such as the String class), and implementations of java.text.CharacterIterator - are UTF-16 sequences.
String 类是实现了 CharSequence 接口,所以自然而然是 utf-16 编码;
二、Java HotSpot VM Options
-XX:+UseCompressedStrings
Use a byte[] for Strings which can be represented as pure ASCII. (Introduced in Java 6 Update 21 Performance Release)
这个选项就是和上面的 kUseStringCompression 变量对应。
六. 最后结论
经过上面的分析我们可以得出以下结论:
- Dalvik 中 String 对象编码方式为 utf-16 编码;
- ART 中 String 对象编码方式为 utf-16 编码,但是有一个情况例外:如果 String 对象全部为 ASCII 字符并且 Android 系统为 8.0 及之上,String 对象的编码则为 utf-8;
- Android dalvik 中 utf-8 编码转 utf-16 编码的函数有缺陷,没有对 4 字节的 utf-8 编码做特殊处理,直到 ART 中才对该缺陷进行了修复。
6.1、 结论 3 验证
结论 3 就回答了我们最早的那个疑问,这个结论需要做一个简单的比较分析。我们回到最上面的问题:为什么不直接使用 env->NewStringUTF() 函数进行转换,而需要额外写一个 UTF82UnicodeOne 函数。其实细心的人可能已经注意到了,上面 dalvik 和 ART 源码中 utf-8 到 utf-16 转换函数是有区别的,我们把关键代码放到一起来进行对比:
dalvik:
DEX_INLINE u2 dexGetUtf16FromUtf8(const char** pUtf8Ptr)
{
unsigned int one, two, three;
one = *(*pUtf8Ptr)++;
if ((one & 0x80) != 0) {
/* two- or three-byte encoding */
two = *(*pUtf8Ptr)++;
if ((one & 0x20) != 0) {
/* three-byte encoding */
three = *(*pUtf8Ptr)++;
return ((one & 0x0f) << 12) |
((two & 0x3f) << 6) |
(three & 0x3f);
} else {
/* two-byte encoding */
return ((one & 0x1f) << 6) |
(two & 0x3f);
}
} else {
/* one-byte encoding */
return one;
}
}
ART:
inline uint16_t GetTrailingUtf16Char(uint32_t maybe_pair) {
return static_cast(maybe_pair >> 16);
}
inline uint16_t GetLeadingUtf16Char(uint32_t maybe_pair) {
return static_cast(maybe_pair & 0x0000FFFF);
}
inline uint32_t GetUtf16FromUtf8(const char** utf8_data_in) {
const uint8_t one = *(*utf8_data_in)++;
if ((one & 0x80) == 0) {
// one-byte encoding
return one;
}
const uint8_t two = *(*utf8_data_in)++;
if ((one & 0x20) == 0) {
// two-byte encoding
return ((one & 0x1f) << 6) | (two & 0x3f);
}
const uint8_t three = *(*utf8_data_in)++;
if ((one & 0x10) == 0) {
return ((one & 0x0f) << 12) | ((two & 0x3f) << 6) | (three & 0x3f);
}
// Four byte encodings need special handling. We'll have
// to convert them into a surrogate pair.
const uint8_t four = *(*utf8_data_in)++;
// Since this is a 4 byte UTF-8 sequence, it will lie between
// U+10000 and U+1FFFFF.
//
// TODO: What do we do about values in (U+10FFFF, U+1FFFFF) ? The
// spec says they're invalid but nobody appears to check for them.
const uint32_t code_point = ((one & 0x0f) << 18) | ((two & 0x3f) << 12)
| ((three & 0x3f) << 6) | (four & 0x3f);
uint32_t surrogate_pair = 0;
// Step two: Write out the high (leading) surrogate to the bottom 16 bits
// of the of the 32 bit type.
surrogate_pair |= ((code_point >> 10) + 0xd7c0) & 0xffff;
// Step three : Write out the low (trailing) surrogate to the top 16 bits.
surrogate_pair |= ((code_point & 0x03ff) + 0xdc00) << 16;
return surrogate_pair;
}
发现了么?dalvik 代码中并没有对 4 字节 utf-8 编码的字符串进行处理,而 ART 中专门用了很详细的注释说明了针对 4 字节编码的 utf-8 需要转成代理对(surrogate pair)!为什么之前 Android 版本没有针对 4 字节编码进行处理?我的一个推测是:可能老版本的 Android 系统使用的是 ucs-2 编码,并没有对 BMP 之外的平面集做处理,所以也不存在 4 字节的 utf-8,在扩展为 utf-16 编码之后,自然而然就需要额外对 4 字节的 utf-8 进行转换成代理对的操作。
测试这个结论也很简单,比如 "" 是 4 字节 utf-8 编码字符(“” 的 utf-8 编码为 F0A0B296,在线查询网站:Unicode和UTF编码转换),在 Android 4.3 上通过 env->NewStringUTF 的方式转换之后会出现崩溃,在 Android 6.0 上则可以正常转换并且交给 Java 层展示,测试代码如下:
char* c_str = new char[5];
c_str[0] = 0xF0;//“”
c_str[1] = 0xA0;
c_str[2] = 0xB2;
c_str[3] = 0x96;
c_str[4] = 0x00;//end
__android_log_print(ANDROID_LOG_INFO, "jni", "%s", c_str);
return /*stringTojstring(env, temp)*/env->NewStringUTF(c_str);
如果在 Android 4.3 上将 env->NewStringUTF 替换成 stringTojstring 函数,就不会运行崩溃了。虽然不会崩溃,但是将转换之后的 String 对象交给 Java 层却显示成乱码,这是因为 stringTojstring 函数中并没有针对 4 字节编码的 utf-8 字符转换成代理对,解决办法可以参考 ART 的 GetUtf16FromUtf8 函数,感兴趣的读者可以自己实践一下。
经过上面的测试,我们做一个推测,UTF82UnicodeOne 函数的作者发现了上面我们描述的行为差异或者因为这个差异所引发的一些问题,才自己专门写了这个 stringTojstring 函数做转换,针对 4 字节(5 字节和 6 字节的处理多余)编码的 utf-8 进行了单独处理。
七、引用
JavaScript 的内部字符编码是 UCS-2 还是 UTF-16
Dalvik虚拟机中NewStringUTF的实现