
这是菜鸟学Python的第87篇原创文章
阅读本文大概需要4分钟
前几天讲了全网爬取6500多只基金的思路篇(全网爬取6500多只基金|看看哪家基金最强),现在我们要开始动手写代码了,有同学说也可以用爬虫框架啊,确实拿现成的轮子可以省很多事情,但是自己动手写轮子对功力的提高比较有帮助,当你熟练之后可以开始考虑用框架。另外我会把整个代码的难点和注意事项一一告诉大家,大家可以一起动手练练,那我们快开始吧
代码思路结构:
爬虫获取6500只基金的url
用所有的url放入一个队列
设计一个类去专门分析每个基金的重点数据
用多线程处理队列里面的url
把处理好的数据立刻写入文件
1.获取全网所有基金信息
1).因为我们要分析所有的基金
第一步要拿到所有基金的url,然后才能进一步解析呀,那如何获取所有的基金名字信息呢 ? 很简单,有很多财经网站都提供这样的信息,我选取了比较有名的"xx基金网站"的数据
url='http://fund.eastmoney.com/allfund.html#0'
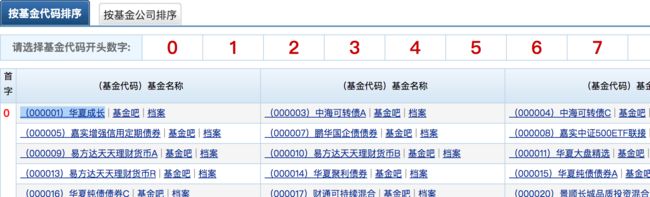
2).分析目标网站的结构
这个是一个静态网站,还比较好处理,我们可以用chrome简单的查看一下每个基金的源码,发现还比较规则,如下:

我们只需把绿色的url链接和红色的基金名字,提取出来就行了.
3).代码主体部分
我们用BeautifulSoup和requests这个两个强大的库去处理,当然可以用其他的库(爬虫的库很多,看个人喜好).我个人很喜欢request这个库,强大简洁,非常优美的库.
#获取整个网页
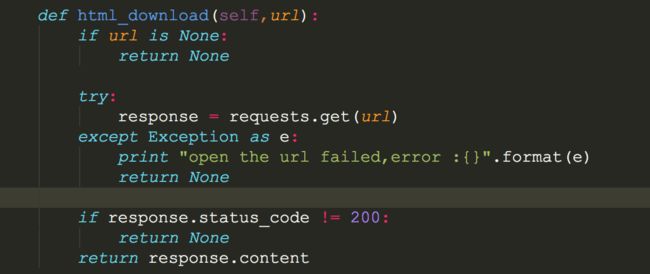
a).传入url
b).用requests分析url
c).异常判断一下,如出现异常就处理一下,若没有异常,判断一下返回的status_code是不是正确的,正确的话就返回整个html的content
#分析网页,提取网站里的基金名字和url
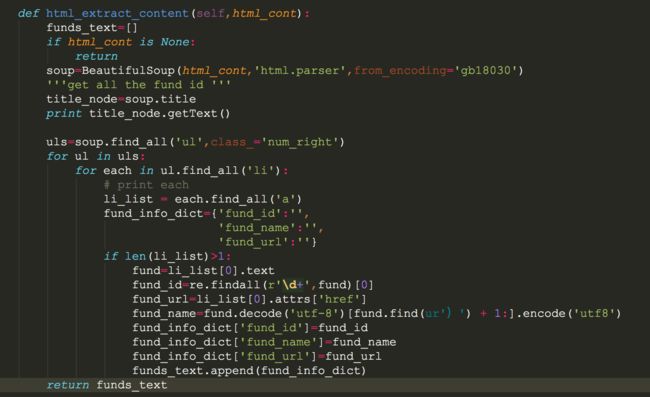
用BeautifulSoup解析上面返回的网页html_content,然后开始解析html
我们的数据在ul/li/div 用bs的find_all很容易取出div里面的数据
数据清洗,有一点在注意我们的基金的名字:"(000001)华夏成长"是数字和中文字符的组合,需要用正则取提取(这里面有一些技巧,大家仔细看一下上面的代码段)
中文字符的问题:因为我们要提取基金的中文名字,一定要在代码前加下面的代码,不然是无法正确解析的
importsys
reload(sys)
sys.setdefaultencoding('utf-8')
2.设计线程类解析每个基金网页
a).这么多基金要分析,我们肯定是要用多线程取处理,所以我们设计一个线程类,这个类继承来自Thread父类
b).我们设计成多线程爬取网页,所以我们要把基金的url都放在一个队列里面,让每个线程从队列里面一个一个取网页,然后分析

c).线程里面的run函数是主函数,主要提取近1个月/近3个月/近6个月/近1年/近3年/成立以来的数据,提取的办法也是用BeautifulSoup和requests去处理,方法跟前面的类似.

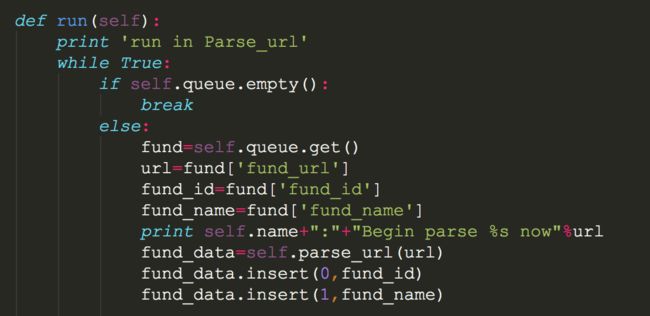
#具体解析基金网页的数据,我们用3个函数去处理(一个是下载网页(html_download),一个是解析网页(html_decode),一个调用2个函数的处理结果)
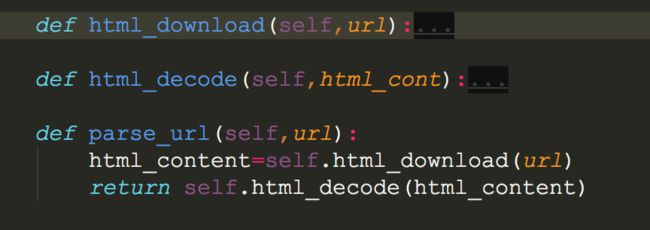
3.多线程写文件
1).我们这次简单处理直接写如csv文件,以后我会讲写数据库处理比如MySql或者是Mongodb用法. 写入csv文件参考我的历史文章(近20年五粮液股价分析|CSV文件实战处理)
2).先写csv文件的头部

3).把每一条基金的数据写入文件
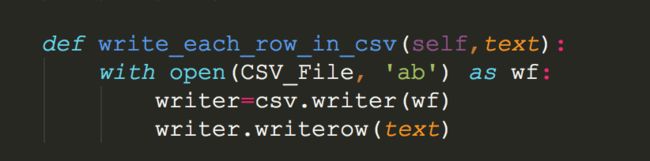
大家有没有想过一个问题,多个线程对同一个文件同时写入,一定会有问题,所以我们必须要加锁
4).多线程的锁
需要创建一个threading模块里面的Lock对象
lock=threading.Lock()
每次对文件的写入的都需要上锁,用完之后解锁
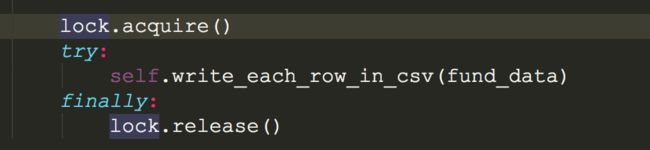
4.主程序
经过上面的几步,基本的程序框架已经完成了,下面就是写主函数,把上面的一个一个功能块串联起来.
1).创建队列
fromQueueimportQueue
queue=Queue()
threads=[]
2).获取所有的基金信息,并放入队列
#get all the funds info
funds=url_download.get_all_funds_dict()
#put all the fund_text info queue
forfund_textinfunds:
queue.put(fund_text)
3).创建多个线程
#create the multi-thread
foriinrange(8):
c=Handle_Url(queue)
threads.append(c)
c.start()
#wait for all thread finish
fortinthreads:
t.join()
我的电脑配置比较高,所以我创建了8个线程,大家可以根据自己的cpu情况决定创建多少个线程
5.看结果,跑个分吧
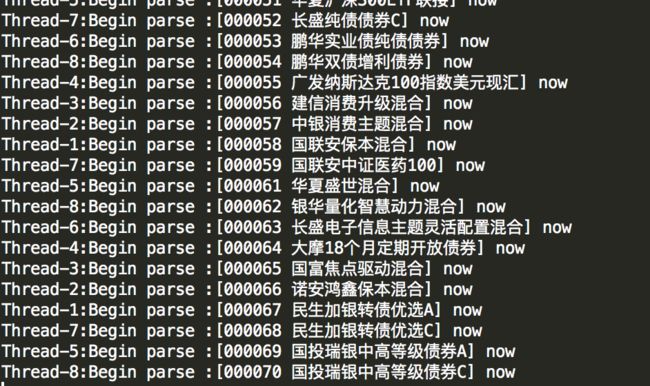
1).写个这么久,我们跑一下程序,看看8个线程同时跑,运行如何:
2).然后在加上一个计算程序运行的时间
importtime
start=time.time()
# main code
print'Cost:{0} seconds'.format(time.time()-start)
Cost:1607.84072995 seconds
3).CSV 文件内容
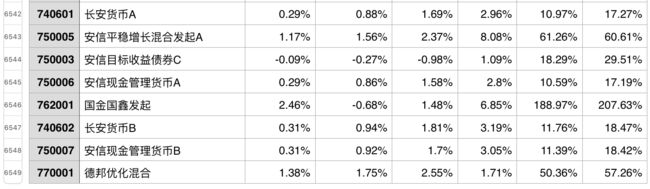
。。。
结论:
全网爬取6500多只基金,大概要20几分钟。好了,今天的全网爬基金实战篇就先讲到这里,上面只是把代码的重点部分列出了,大家可以试着写写.希望能给初学者一些启发,若有什么不懂的,也可以留言跟我探讨交流.等下一篇数据分析讲完之后,我会把源码放在Github上,如果心急的小伙伴想看看6500基金的csv数据,可以文章底部留言.
另外最精彩的6500基金数据分析篇即将呈现,敬请期待
历史人气文章
Python语言如何入门
最全的零基础学Python的问题,你想知道的都在这里
Python入门原创文章,2016年度大盘点
Python写个迷你聊天机器人|生成器的高级用法
用Python破解微软面试题|24点游戏
一道Google的算法题 |Python巧妙破解