JobManager协调每个flink应用的部署,它负责执行定时任务和资源管理。
每一个Flink集群都有一个jobManager, 如果jobManager出现问题之后,将不能提交新的任务和运行新任务失败,这样会造成单点失败,所以需要构建高可用的JobMangager。
类似zookeeper一样,构建好了高可用的jobManager之后,如果其中一个出现问题之后,其他可用的jobManager将会接管任务,变为leader。不会造成flink的任务执行失败。可以在单机版和集群版构建jobManager。
下面开始构建一个单机版flink的JobManger高可用HA版。
首先需要设置SSH免密登录,因为启动的时候程序会通过远程登录访问并且启动程序。
执行命令,就可以免密登录自己的机器了。如果不进行免密登录的话,那么启动的hadoop的时候会报 "start port 22 connection refused"。
ssh-keygen -t rsa ssh-copy-id -i ~/.ssh/id_rsa.pub huangqingshi@localhost
接下来在官网上下载hadoop的binary文件,然后开始解压,我下载的版本为hadoop-3.1.3版本。安装Hadoop的目的是用hadoop存储flink的JobManager高可用的元数据信息。
我安装的是hadoop的单机版,可以构建hadoop集群版。接下来进行hadoop的配置。
配置etc/hadoop/coresite.xml,指定namenode的hdfs协议文件系统的通信地址及临时文件目录。
fs.defaultFS hdfs://127.0.0.1:9000 hadoop.tmp.dir /tmp/hadoop/tmp
配置etc/hadoop/hdfs-site.xml, 设置元数据的存放位置,数据块的存放位置,DFS监听端口。
dfs.namenode.name.dir /tmp/hadoop/namenode/data dfs.datanode.data.dir /tmp/hadoop/datanode/data dfs.http.address 127.0.0.1:50070
配置etc/hadoop/yarn-site.xml,配置NodeManager上运行的附属服务以及resourceManager主机名。
<configuration> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.resourcemanager.hostnamename> <value>localhostvalue> property> configuration>
配置etc/hadoop/mapred-site.xml,指定mapreduce作业运行在yarn上。
<property> <name>mapreduce.framework.namename> <value>yarnvalue> property> configuration>
需要执行nameNode的format操作,不执行直接启动会报“NameNode is not formatted.”。
bin/hdfs namenode -format
接下来启动hadoop,如果成功的话,可以访问如下URL:
http://localhost:50070/
http://localhost:8088/ 查看构成cluster的节点
http://localhost:8042/node 查看node的相关信息。

以上说明hadoop单机版搭建完成。
接下来需要下载一个flink的hadoop插件,要不然flink启动的时候会报错的。
下载地址为:https://repo1.maven.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.8.3-7.0/flink-shaded-hadoop-2-uber-2.8.3-7.0.jar
把下载的插件放到flink文件的lib文件夹中。
配置一下flink文件夹的conf/flink-conf.yaml。指定HA高可用模式为zookeeper,元数据存储路径用于恢复master,zookeeper用于flink的 checkpoint 以及 leader 选举。最后一条为zookeeper单机或集群的地址。
high-availability: zookeeper
high-availability.storageDir: hdfs://127.0.0.1:9000/flink/ha
high-availability.zookeeper.quorum: localhost:2181
其他的采用默认配置,比如JobManager的最大堆内存为1G,每一个TaskManager提供一个task slot,执行串行的任务。
接下来配置flink的 conf/masters 用于启动两个主节点JobManager。
localhost:8081
localhost:8082
配置flink的 conf/slaver 用于配置三个从节点TaskManager。
localhost
localhost
localhost
进入zookeeper路径并且启动zookeeper
bin/zkServer.sh start
进入flink路径并启动flink。
bin/start-cluster.sh conf/flink-conf.yaml
启动截图说明启动了两个节点的HA集群。

执行jps,两个JobManager节点和三个TaskManager节点:

浏览器访问 http://localhost:8081 和 http://localhost:8082,查看里边的日志,搜索granted leadership的说明是主JobManager,如下图。8082端口说明为主JobMaster
一个JobManager, 里边有三个TaskManager,两个JobManager共享这三个TaskManager:

接下来我们来验证一下集群的HA功能,我们已经知道8082为主JobManager,然后我们找到它的PID,使用如下命令:
ps -ef | grep StandaloneSession
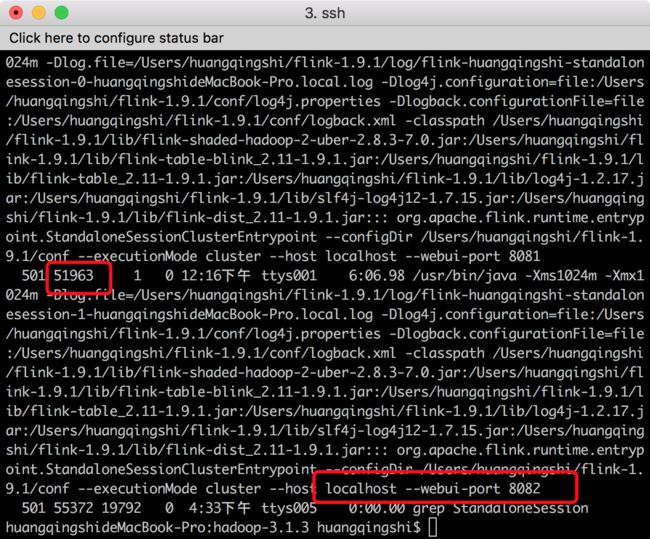
我们将其kill掉,执行命令kill -9 51963,此时在访问localhost:8082 就不能访问了。localhost:8081 还可以访问,还可以提供服务。接下来咱们重新 启动flink的JobManager 8082 端口。
bin/jobmanager.sh start localhost 8082
此时8081已经成为leader了,继续提供高可用的HA了。
好了,到此就算搭建完成了。