title: 机器学习之逻辑回归
date: 2017-04-23 22:42:16
categories: IT技术
tags: 机器学习
逻辑回归介绍
在介绍Logistic Regression之前我们先简单说一下线性回归,线性回归的主要思想就是通过历史数据拟合出一条直线,用这条直线对新的数据进行预测。线性回归的公式如下:
$$ z={\theta_{0}}+{\theta_{1}x_{1}}+{\theta_{2}x_{2}+{\theta_{3}x_{3}}...+{\theta_{n}x_{n}}}=\theta^Tx $$
而对于Logistic Regression来说,其思想也是基于线性回归(Logistic Regression属于广义线性回归模型)。其公式如下:
$$ h_{\theta}(x)=\frac{1}{1+e{-z}}=\frac{1}{1+e{-\theta^Tx}} $$
其中,$ g(z)=\frac{1}{1+e^{-z}} $
被称作sigmoid函数,我们可以看到,Logistic Regression算法是将线性函数的结果映射到了sigmoid函数中。sigmoid函数的图像如下
# **sigmoid函数**
import matplotlib.pyplot as plt
from math import exp
import numpy as np
def sigmoid(n):
return 1.0/(1+exp(-n))
a1 = [n for n in np.arange(-10, 10, 0.1)]
a2 = [sigmoid(n) for n in a1]
plt.plot(a1, a2)
plt.show()
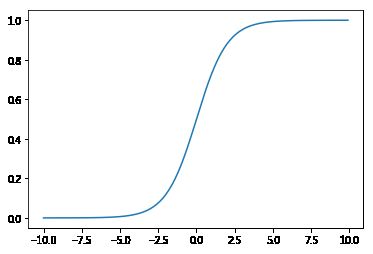
逻辑回归就是一个被logistic函数(一般是sigmoid函数)归一化后的线性回归。
逻辑回归(Logistic Regression)是比较正统的机器学习算法。
机器学习算法的一般步骤
- 对于一个问题,我们用数学语言来描述它,然后建立一个模型(如回归模型或者分类模型等)来描述这个问题;
- 通过最大似然、最大后验概率或者最小化分类误差等等建立模型的代价函数,也就是一个最优化问题。
- 然后我们需要求解这个代价函数,找到最优解。这求解也就分很多种情况了:
- 如果这个优化函数存在解析解。例如我们求最值一般是对代价函数求导,找到导数为0的点,也就是最大值或者最小值的地方了。如果代价函数能简单求导,并且求导后为0的式子存在解析解,那么我们就可以直接得到最优的参数了。
- 如果式子很难求导或者求导后式子得不到解释解,这时候我们就需要借助迭代算法来一步一步找到最优解了。
另外需要考虑的情况是,如果代价函数是凸函数,那么就存在全局最优解。但如果是非凸的,那么就会有很多局部最优的解。
逻辑回归的一般步骤
- 设定拟合函数(hypothesis function):hθ(x),其意义是给定参数θ,根据输入x,给出输出hθ(x),当输出值大于0.5时预测录取,否则预测被拒。
- 设定代价函数(cost function):J(θ),其意义是累加所有样本的预测结果hθ(x)与真实结果y之间的差距。
- 通过优化算法(如梯度下降法)来调整参数θ,迭代求解出最优的模型参数,使得代价函数J( θ )的值最小。
比较线性回归与Logistic回归,可以看出二者非常相似,但是Logistic回归的拟合函数(步骤一)和代价函数(步骤二)的定义方法与线性回归有所不同。
线性回归输出的是连续的实数,而Logistic回归输出的是[0,1]区间的概率值,给我们提供的就是你的这个样本属于正类的可能性是多少,通过概率值来判断因变量应该是1还是0。
假设我们的样本是{x, y},y是0或者1,表示正类或者负类,x是我们的m维的样本特征向量。那么这个样本x属于正类,也就是y=1的概率可以通过下面的逻辑函数来表示:
$$ P(y=1|x;\theta) = σ(\theta^Tx) = \frac{1}{1+e{-\thetaTx}} $$
$$ P(y=0|x;\theta) = 1- σ(\theta^Tx) = 1 - \frac{1}{1+e{-\thetaTx}} $$
$$ \ln{\frac{P(y=1|x;\theta)} {P(y=0|x;\theta)}} = \frac{1- \frac{1}{1+e{-\thetaTx}}} {\frac{1}{1+e{-\thetaTx}}} = \theta^Tx = {\theta_{0}}+{\theta_{1}x_{1}}+{\theta_{2}x_{2}+{\theta_{3}x_{3}}...+{\theta_{n}x_{n}}}$$
这里θ是模型参数,也就是回归系数,σ是sigmoid函数。
举个相亲的例子,y表示你被对方相中的概率,概率值与多个因素有关,如你人品怎样、车子是两个轮的还是四个轮的、长得丑还是美、有千尺豪宅还是三寸茅庐等等,我们把这些因素表示为x1, x2,…, xm。那对方的怎样考量这些因素呢?最快的方式就是把这些因素的得分都加起来,最后得到的和越大,就表示越喜欢。但每个人心里其实都有一杆称,每个人考虑的因素不同,如这个女生更看中你的人品,人品的权值是0.6,不看重你有没有钱,那么有没有钱的权值是0.001等等。我们将这些对应x1, x2,…, xm的权值叫做回归系数,表达为θ1, θ2,…, θm,他们的加权和就是你的总得分了,总分带入sigmoid函数的结果就代表你被接受的概率。
最优化算法
梯度下降(gradient descent)
梯度下降是利用函数的梯度信息找到函数最优解的一种方法,也是机器学习里面最简单最常用的一种优化方法。它的思想很简单,要找最小值,只需要每一步都往下走(也就是每一步都可以让代价函数小一点),然后不断的走,那肯定能走到最小值的地方。为了更快的到达最小值啊,需要每一步都找下坡最快的地方,这个下坡最快的方向就是梯度的负方向了。而每一步的长度叫作步长也叫学习率,一般用参数α表示。α不宜太大也不能太小,太小的话整个迭代过程太慢,太大的话可能会一步跨过了最值点。梯度算法的迭代公式如下:
$$ \theta := \theta + \nabla h_{\theta}(x)$$
梯度下降算法的伪代码如下:
初始化回归系数为1
重复下面步骤直到收敛{
计算整个数据集的梯度
使用alpha x gradient来更新回归系数
}
返回回归系数值
随机梯度下降SGD (stochastic gradient descent)
梯度下降算法在每次更新回归系数的时候都需要遍历整个数据集(计算整个数据集的回归误差),该方法对小数据集尚可。但当遇到有数十亿样本和成千上万的特征时,就有点力不从心了,它的计算复杂度太高。改进的方法是一次仅用一个样本点(的回归误差)来更新回归系数。这个方法叫随机梯度下降算法。由于可以在新的样本到来的时候对分类器进行增量的更新(假设我们已经在数据库A上训练好一个分类器h了,那新来一个样本x。对非增量学习算法来说,我们需要把x和数据库A混在一起,组成新的数据库B,再重新训练新的分类器。但对增量学习算法,我们只需要用新样本x来更新已有分类器h的参数即可),所以它属于在线学习算法。与在线学习相对应,一次处理整个数据集的叫“批处理”。
初始化回归系数为1
重复下面步骤直到收敛{
对数据集中每个样本
计算该样本的梯度
使用alpha xgradient来更新回归系数
}
返回回归系数值
改进的随机梯度下降
评价一个优化算法的优劣主要是看它是否收敛,也就是说参数是否达到稳定值,是否还会不断的变化?收敛速度是否快?
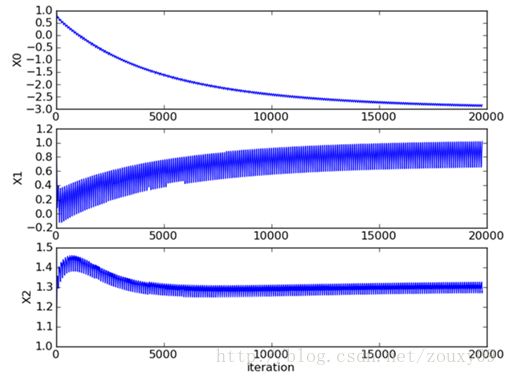
上图展示了随机梯度下降算法对三个回归系数的变化过程,对100个二维样本进行200次迭代,每次迭代都要遍历这100个样本来调整系数,所以共有200*100=20000次调整。其中系数X2经过50次迭代就达到了稳定值。但系数X1和X0到100次迭代后稳定。而且可恨的是系数X1和X2还在很调皮的周期波动,迭代次数很大了,还停不下来。产生这个现象的原因是存在一些无法正确分类的样本点,也就是我们的数据集并非线性可分,但我们的logistic regression是线性分类模型,对非线性可分情况无能为力。然而我们的优化程序并没能意识到这些不正常的样本点,还一视同仁的对待,调整系数去减少对这些样本的分类误差,从而导致了在每次迭代时引发系数的剧烈改变。对我们来说,我们期待算法能避免来回波动,从而快速稳定和收敛到某个值。
对随机梯度下降算法,我们做两处改进来避免上述的波动问题:
在每次迭代时,调整更新步长alpha的值。随着迭代的进行,alpha越来越小,这会缓解系数的高频波动(也就是每次迭代系数改变得太大,跳的跨度太大)。当然了,为了避免alpha随着迭代不断减小到接近于0(这时候,系数几乎没有调整,那么迭代也没有意义了),我们约束alpha一定大于一个稍微大点的常数项。
每次迭代,改变样本的优化顺序。也就是随机选择样本来更新回归系数。这样做可以减少周期性的波动,因为样本顺序的改变,使得每次迭代不再形成周期性。
改进的随机梯度下降算法的伪代码如下:
初始化回归系数为1
重复下面步骤直到收敛{
对随机遍历的数据集中的每个样本
随着迭代的逐渐进行,减小alpha的值
计算该样本的梯度
使用alpha x gradient来更新回归系数
}
返回回归系数值
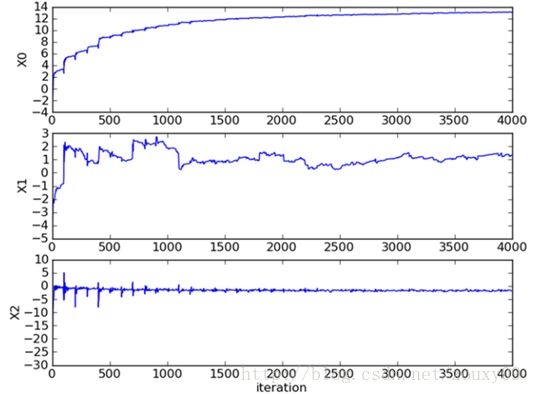
比较原始的随机梯度下降和改进后的梯度下降,可以看到两点不同:
- 系数不再出现周期性波动。
- 系数可以很快的稳定下来,也就是快速收敛。这里只迭代了20次就收敛了。而上面的随机梯度下降需要迭代200次才能稳定。
代码实现
import numpy as np
import matplotlib.pyplot as plt
import time
def load_data():
train_x = []
train_y = []
with open('testSet.txt') as f:
for line in f.readlines():
line = line.strip().split()
train_x.append([1.0, float(line[0]), float(line[1])])
train_y.append(float(line[2]))
return np.mat(train_x), np.mat(train_y).transpose()
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
# train a logistic regression model using some optional optimize algorithm
# input: train_x is a mat datatype, each row stands for one sample
# train_y is mat datatype too, each row is the corresponding label
# opts is optimize option include step and maximum number of iterations
def train(train_x, train_y, opts):
start_time = time.time()
num_samples, num_features = np.shape(train_x)
alpha = opts['alpha']
max_iter = opts['max_iter']
weights = np.ones((num_features, 1))
for k in range(max_iter):
if opts['optimize_type'] == 'grad_descent': # gradient descent algorilthm
output = sigmoid(train_x * weights)
error = train_y - output
weights = weights + alpha * train_x.transpose() * error
elif opts['optimize_type'] == 'stoc_grad_descent': # stochastic gradient descent
for i in range(num_samples):
output = sigmoid(train_x[i, :] * weights)
error = train_y[i, 0] - output
weights = weights + alpha * train_x[i, :].transpose() * error
elif opts['optimize_type'] == 'smooth_stoc_grad_descent': # smooth stochastic gradient descent
# randomly select samples to optimize for reducing cycle fluctuations
data_index = list(range(num_samples))
for i in range(num_samples):
alpha = 4.0 / (1.0 + k + i) + 0.01
rand_index = int(np.random.uniform(0, len(data_index)))
output = sigmoid(train_x[rand_index, :] * weights)
error = train_y[rand_index, 0] - output
weights = weights + alpha * train_x[rand_index, :].transpose() * error
del(data_index[rand_index]) # during one interation, delete the optimized sample
else:
raise NameError('Not support optimize method type!')
print('训练结束,花费时间: %fs!' % (time.time() - start_time))
return weights
# test your trained Logistic Regression model given test set
def test(weights, test_x, test_y):
numSamples, numFeatures = np.shape(test_x)
matchCount = 0
for i in range(numSamples):
predict = sigmoid(test_x[i, :] * weights)[0, 0] > 0.5
if predict == bool(test_y[i, 0]):
matchCount += 1
accuracy = float(matchCount) / numSamples
return accuracy
# show your trained logistic regression model only available with 2-D data
def show(weights, train_x, train_y):
# notice: train_x and train_y is mat datatype
num_samples, num_features = np.shape(train_x)
if num_features != 3:
print("Sorry! I can not draw because the dimension of your data is not 2!")
return 1
# 画出所有的点
for i in range(num_samples):
if int(train_y[i, 0]) == 0:
plt.plot(train_x[i, 1], train_x[i, 2], 'or')
elif int(train_y[i, 0]) == 1:
plt.plot(train_x[i, 1], train_x[i, 2], 'ob')
# 画出分割线
min_x = min(train_x[:, 1])[0, 0]
max_x = max(train_x[:, 1])[0, 0]
weights = weights.getA() # convert mat to array
y_min_x = float(-weights[0] - weights[1] * min_x) / weights[2]
y_max_x = float(-weights[0] - weights[1] * max_x) / weights[2]
plt.plot([min_x, max_x], [y_min_x, y_max_x], '-g')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
if __name__ == '__main__':
# 加载数据
print("step 1: load data...")
train_x, train_y = load_data()
test_x = train_x
test_y = train_y
# 训练
print("step 2: training...")
opts = {'alpha': 0.01, 'max_iter': 20, 'optimize_type': 'smooth_stoc_grad_descent'}
optimalWeights = train(train_x, train_y, opts)
# 测试
print("step 3: testing...")
accuracy = test(optimalWeights, test_x, test_y)
# 查看结果
print("step 4: show the result...")
print('The classify accuracy is: %.3f%%' % (accuracy * 100))
show(optimalWeights, train_x, train_y)
step 1: load data...
step 2: training...
训练结束,花费时间: 0.170251s!
step 3: testing...
step 4: show the result...
The classify accuracy is: 95.000%
