Guava Cache以下的特性:
automatic loading of entries into the cache;
least-recently-used eviction when a maximum size is exceeded;
time-based expiration of entries, measured since last access or last write;
keys automatically wrapped in WeakReference;
values automatically wrapped in WeakReference or SoftReference soft;
notification of evicted (or otherwise removed) entries;
accumulation of cache access statistics.
总结来说:
- 一定要有的读、写、移除等接口;
- 还有loading特性,即if cached, return; otherwise create/load/compute, cache and return;
- 还需要时效策略(基于最大容量的时效、和基于读写时间的时效);
- 基于不同引用级别的key/value;
- 缓存时效后的通知回调;
- 最后是cache相关的统计。
以上特性是可选的,通过CacheBuilder构造自己的Cache。下面是两个简单的例子:
第一个例子,构造一个最大容量为2的cache,插入3个数据。在插入第三个数据后,key为b的entry被失效了,因为基于lru原则,a多访问过一次。
Cache cache = CacheBuilder.newBuilder().maximumSize(2).build();
Obj obj_a = new Obj(1, 2);
Obj obj_b = new Obj(2, 2);
Obj obj_c = new Obj(3, 2);
// first put count=1
cache.put("a", obj_a);
Assert.assertEquals(obj_a, cache.getIfPresent("a"));
// 2nd put count=2
cache.put("b", obj_b);
// use a more than b
cache.getIfPresent("a");
Assert.assertEquals(obj_b, cache.getIfPresent("b"));
Assert.assertEquals(obj_a, cache.getIfPresent("a"));
// 3rd put count=3 need remove one
cache.put("c", obj_c);
Assert.assertEquals(obj_c, cache.getIfPresent("c"));
Assert.assertTrue(cache.getIfPresent("b") == null);
第二个例子,构造了一个自动实现load逻辑的LoadingCache。可以看到,第一次取key为d的数据,会自动调用用户覆盖的load方法返回,loadingcache会自动将该value写入cache。以后再从cache中直接取的时候,就可以得到值。
LoadingCache cache = CacheBuilder.newBuilder().build(new CacheLoader() {
@Override
public Obj load(String key) throws Exception {
return new Obj(3,3);
}
});
Obj obj_d = new Obj(3, 3);
// get method is the same as get(key,new Callable)
Assert.assertEquals(obj_a,cache.get("d"));
Assert.assertEquals(obj_a,cache.getIfPresent("d"));// 从cache重直接取
Guava Cache结构
- Cache配置
- Cache及其实现和扩展(包括不同级别的引用)、 Cache的失效通知回调
- Cache状态
一、Cache及其实现和扩展
通过类图,可以看出有一个Cache接口,不同的Cache均要实现该接口的方法,或者拓展新的方法。还有一个LoadingCache接口,增加了get()方法,实际是一种getorload逻辑(如果cache中存在就get,否则执行用户指定的load逻辑),后面会细说。针对cache和loadingCache有两个实现类,LocalManualCache和基于LocalManualCache实现的LocalLoadingCache。
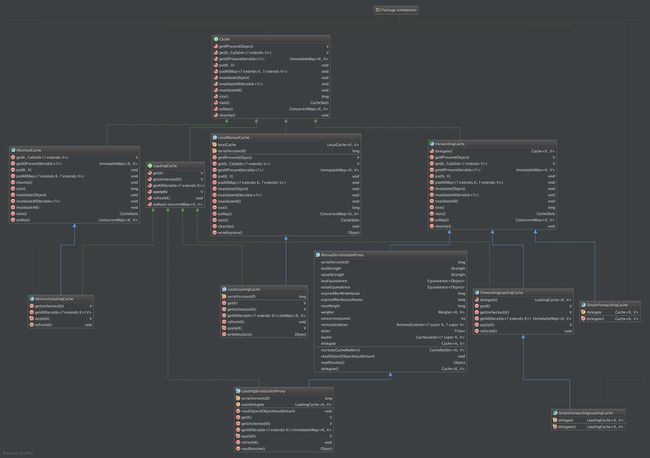
代理模式
这两个类并没有直接实现“缓存”的功能,而是通过另个类的方法去实现缓存所需的所有功能,这个类就是LocalCache,它的变量是包级访问级别。
保护(Protect or Access)代理: 控制对一个对象的访问,可以给不同的用户提供不同级别的使用权限。
那么LocalCache是如何实现cache的呢?
LocalCache实现了ConcurrentMap,并且使用了Segment的设计思想(不知道是否因为ConcurrentHashMap的影响,EhCache也使用了这种思想)。
补充:
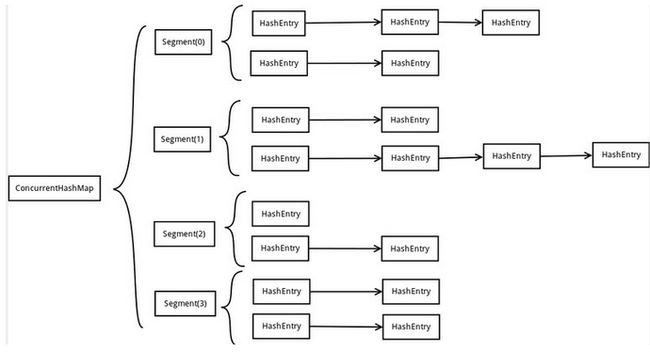
ConcurrentHashMap采用了二次hash的方式,第一次hash将key映射到对应的segment,而第二次hash则是映射到segment的不同桶中。为什么要用二次hash,主要原因是为了构造 分离锁 ,使得对于map的修改不会锁住整个容器,提高并发能力。
// map维护segment数组
final Segment[] segments;
1. Segment
Segment继承ReentrantLock,说明在cache的segments数组中的每个segment加锁。基本上所有的cache功能都是在segment上实现的。我们一步一步来看:
Segment中的put操作
-
首先它需要获得锁,然后做一些清理工作(guava的cache都是这种基于懒清理的模式,在put、get等操作的前/后执行清理);
long now = map.ticker.read();//当次进入的时间,nano preWriteCleanup(now);// 基于当前时间做清理,比如写入后3s中失效这种场景 -
接下来,根据长度判断是否需要expand,expand后会生成一个newTable;
if (newCount > this.threshold) { // ensure capacity expand(); newCount = this.count + 1; } 然后,根据put的语义,如果已存在entry,需要返回旧的entry。那么根据二次hash找到segment中的一个链表的头,开始遍历,找到存在的entry。
当找到一个已存在的entry时,需要先判断当前的ValueRefernece中的值事实上已经被回收,因为它们可以是WeakReference或者SoftReferenc类型。对于弱引用和软引用如果被回收,valueReference.get()会返回null。如果没有回收,就替换旧的值,换做新值。
-
然后,针对移除的对象,构造移除通知对象(RemovalNotification),指定相应的原因:COLLECTED、REPLACED等,进入队列。之后,会统一顺序利用LocalCache注册的RemovalListener,执行针对通知对象的回调。由于回调事件处理可能会有很长时间,因而这里将事件处理的逻辑在退出锁以后才做。代码中是hash值,是第二次的hash值。
enqueueNotification(key, hash, valueReference, RemovalCause.COLLECTED); enqueueNotification(key, hash, valueReference, RemovalCause.REPLACED); -
如果链表中没有该key对应的entry。create后,加入到链表头。
// Create a new entry. ++modCount; ReferenceEntry
注意,返回null不能代表需要被移除
因为有一种value是LoadingValueReference类型的。在需要动态加载一个key的值时(场景就是第二个例子:如果cache中没有key,会调用load方法加载),实现是:
- 先把该值封装在LoadingValueReference中,以表达该key对应的值已经在加载了;
- 如果其他线程也要查询该key对应的值,就能得到该引用,然后同步执行load方法;
- 在该只加载完成后,将LoadingValueReference替换成其他ValueReference类型。
所以,在load()执行完成之前,在其他线程得到的value一定是一个 不完全对象 ,因此不能认为应该将它remove。
那么如何区分呢
在valueReference增加了一个active方法,用来标明这个entry是否已经正确在cache中,由于新建的LoadingValueReference,其内部初始值是UNSET,它的isActive为false,这样通过isActive就可以判断该ValueReference是否是一个完全状态。
-
put中对Active的判断,可以看到如果active为false就直接赋值。不过很可能,一会load执行完后,值又被替换成load后的值了(替换的时候,count会减1)。
if (valueReference.isActive()) { enqueueNotification(key, hash, valueReference, RemovalCause.COLLECTED); setValue(e, key, value, now); newCount = this.count; // count remains unchanged } else { setValue(e, key, value, now); newCount = this.count + 1; }
Segment的get操作
get操作分为两种,一种是get,另一种是带CacheLoader的get。逻辑分别是:
- get从缓存中取结果;
- 带CacheLoader的get,如果缓存中无结果,返回cacheloader的load的方法返回的结果,然后写入缓存entry。
具体介绍一下带CacheLoader的get操作:
则获取对象引用(引用可能是非alive的,比如是需要失效的、比如是loading的);
判断对象引用是否是alive的(如果entry是非法的、部分回收的、loading状态、需要失效的,则认为不是alive)。
如果对象是alive的,如果设置refresh,则异步刷新查询value,然后等待返回最新value。
针对不是alive的,但却是在loading的,等待loading完成(阻塞等待)。
这里如果value还没有拿到,则查询loader方法获取对应的值(阻塞获取)。
以上就是get的逻辑,代码如下:
V get(K key, int hash, CacheLoader loader) throws ExecutionException {
checkNotNull(key);
checkNotNull(loader);
try {
if (count != 0) { // read-volatile
// don't call getLiveEntry, which would ignore loading values
ReferenceEntry e = getEntry(key, hash);
if (e != null) {
// 记录进入时间
long now = map.ticker.read();
// 判断是否为alive(此处是懒失效,在每次get时才检查是否达到失效时机)
V value = getLiveValue(e, now);
if (value != null) {
// 记录
recordRead(e, now);
// 命中
statsCounter.recordHits(1);
// 刷新
return scheduleRefresh(e, key, hash, value, now, loader);
}
ValueReference valueReference = e.getValueReference();
if (valueReference.isLoading()) {
// 如果正在加载的,等待加载完成后,返回加载的值。(阻塞,future的get)
return waitForLoadingValue(e, key, valueReference);
}
}
}
// 此处或者为null,或者已经被失效。
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
Throwable cause = ee.getCause();
if (cause instanceof Error) {
throw new ExecutionError((Error) cause);
} else if (cause instanceof RuntimeException) {
throw new UncheckedExecutionException(cause);
}
throw ee;
} finally {
postReadCleanup();
}
}
lockedGetOrLoad方法
V lockedGetOrLoad(K key, int hash, CacheLoader loader)
throws ExecutionException {
ReferenceEntry e;
ValueReference valueReference = null;
LoadingValueReference loadingValueReference = null;
boolean createNewEntry = true;
// 对segment加锁
lock();
try {
// re-read ticker once inside the lock
long now = map.ticker.read();
// 加锁清清理GC遗留引用数据和超时数据(重入锁)
preWriteCleanup(now);
int newCount = this.count - 1;
AtomicReferenceArray> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry first = table.get(index);
for (e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
// 在链表中找到e
valueReference = e.getValueReference();
// 正在loading 不需要新load
if (valueReference.isLoading()) {
createNewEntry = false;
} else {
V value = valueReference.get();
// 为null,说明被gc回收了。
if (value == null) {
// 相关通知操作
enqueueNotification(entryKey, hash, valueReference, RemovalCause.COLLECTED);
} else if (map.isExpired(e, now)) {
// This is a duplicate check, as preWriteCleanup already purged expired
// entries, but let's accomodate an incorrect expiration queue.
enqueueNotification(entryKey, hash, valueReference, RemovalCause.EXPIRED);
} else {
recordLockedRead(e, now);
statsCounter.recordHits(1);
// we were concurrent with loading; don't consider refresh
return value;
}
// 清除掉非法的数据(被回收的、失效的)
writeQueue.remove(e);
accessQueue.remove(e);
this.count = newCount; // write-volatile
}
break;
}
}
if (createNewEntry) {
// LoadingValueReference类型
loadingValueReference = new LoadingValueReference();
if (e == null) {
// 新建一个entry
e = newEntry(key, hash, first);
e.setValueReference(loadingValueReference);
// 写入index的位置
table.set(index, e);
} else {
// 到此,说e找到,但是是非法的,数据已被移除。e放入新建的引用
e.setValueReference(loadingValueReference);
}
}
} finally {
unlock();
postWriteCleanup();
}
// 上面加锁部分建完了新的entry,设置完valueReference(isAlive为false,isLoading 为false),到此,锁已经被释放,其他线程可以拿到一个loading状态的引用。这就符合get时,拿到loading状态引用后,阻塞等待加载的逻辑了。
if (createNewEntry) {
try {
// 这里只对e加锁,而不是segment,允许get操作进入。
synchronized (e) {
// 这个方法同步、线程安全的将key和value都放到cache中。
return loadSync(key, hash, loadingValueReference, loader);
}
} finally {
statsCounter.recordMisses(1);
}
} else {
// The entry already exists. Wait for loading.
return waitForLoadingValue(e, key, valueReference);
}
}
2. ReferenceEntry和ValueReference
之前说过,guava cache支持不同级别的的引用。首先来确认一下,java中的四种引用。
四种引用
- 强引用
- StringBuffer buffer = new StringBuffer();
- 如果一个对象通过一串强引用链接可到达(Strongly reachable),它是不会被回收的
- 弱引用
在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
-
不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
Car obj = new Car("red"); WeakReferenceweakCar = new WeakReference (obj); // obj=new Car("blue"); while(true){ String[] arr = new String[1000]; if(weakCar.get()!=null){ // do something }else{ System.out.println("Object has been collected."); break; } } 如上述代码,weak引用的对象,有个强引用也就是red Car,所以是不会回收的。
但是,如果就上面的注释删去,那么原来的obj引用了新的对象也就是blue car。原来对象已经没有强引用了,所以虚拟机会将weak回收掉。
- 软引用
- 软引用基本上和弱引用差不多,只是相比弱引用
- 当内存不足时垃圾回收器才会回收这些软引用可到达的对象。
- 虚引用
- 与软引用,弱引用不同,虚引用指向的对象十分脆弱,我们不可以通过get方法来得到其指向的对象。
- 它的唯一作用就是当其指向的对象被回收之后,自己被加入到引用队列,用作记录该引用指向的对象已被销毁。
引用队列(Reference Queue)
- 引用队列可以很容易地实现跟踪不需要的引用。
- 一旦弱引用对象开始返回null,该弱引用指向的对象就被标记成了垃圾。
- 当你在构造WeakReference时传入一个ReferenceQueue对象,当该引用指向的对象被标记为垃圾的时候,这个引用对象会自动地加入到引用队列里面。
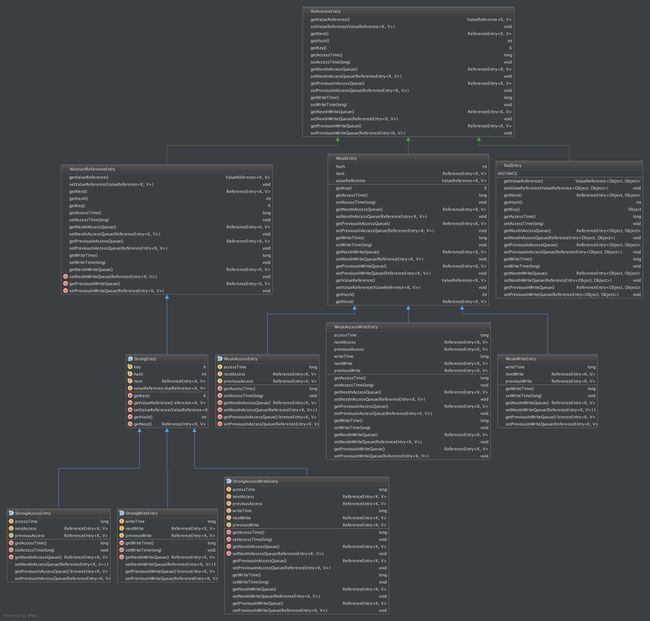
ReferenceEntry的类图
- Cache中的所有Entry都是基于ReferenceEntry的实现。
- 信息包括:自身hash值,写入时间,读取时间。每次写入和读取的队列。以及链表指针。
- 每个Entry中均包含一个ValueReference类型来表示值。
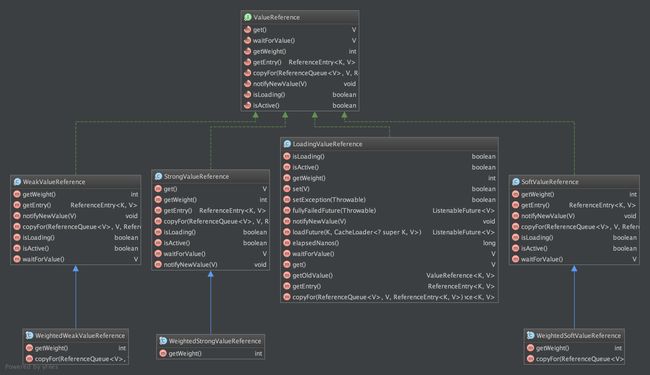
ValueReference的类图
- 对于ValueReference,有三个实现类:StrongValueReference、SoftValueReference、WeakValueReference。为了支持动态加载机制,它还有一个LoadingValueReference,在需要动态加载一个key的值时,先把该值封装在LoadingValueReference中,以表达该key对应的值已经在加载了,如果其他线程也要查询该key对应的值,就能得到该引用,并且等待改值加载完成,从而保证该值只被加载一次(可以在evict以后重新加载)。在该值加载完成后,将LoadingValueReference替换成其他ValueReference类型。(后面会细说)
- 每个ValueReference都纪录了weight值,所谓weight从字面上理解是“该值的重量”,它由Weighter接口计算而得。
- 还定义了Stength枚举类型作为ValueReference的factory类,它有三个枚举值:Strong、Soft、Weak,这三个枚举值分别创建各自的ValueReference。
WeakEntry为例子
在cache的put操作和带CacheBuilder中的都有newEntry的操作。newEntry根据cache builder的配置生成不用级别的引用,比如put操作:
// Create a new entry.
++modCount;
// 新建一个entry
ReferenceEntry newEntry = newEntry(key, hash, first);
// 设置值,也就是valueRerence
setValue(newEntry, key, value, now);
newEntry方法
根据cache创建时的配置(代码中生成的工厂),生成不同的Entry。
ReferenceEntry newEntry(K key, int hash, @Nullable ReferenceEntry next) {
return map.entryFactory.newEntry(this, checkNotNull(key), hash, next);
}
调用WEAK的newEntry,其中segment.keyReferenceQueue是key的引用队列。还有一个value的引用队列,valueReferenceQueue一会会出现。
WEAK {
@Override
ReferenceEntry newEntry(
Segment segment, K key, int hash, @Nullable ReferenceEntry next) {
return new WeakEntry(segment.keyReferenceQueue, key, hash, next);
}
},
setValue方法
首先要生成一个valueReference,然后set到entry中。
ValueReference valueReference =
map.valueStrength.referenceValue(this, entry, value, weight);
entry.setValueReference(valueReference);
Value的WEAK跟key的WEAK形式很像。只不过,增加了weight值(cachebuilder复写不同k,v对应的权重)和value的比较方法。
WEAK {
@Override
ValueReference referenceValue(
Segment segment, ReferenceEntry entry, V value, int weight) {
return (weight == 1)
? new WeakValueReference(segment.valueReferenceQueue, value, entry)
: new WeightedWeakValueReference(
segment.valueReferenceQueue, value, entry, weight);
}
@Override
Equivalence cache如何基于引用做清理
如果key或者value的引用不是Strong类型,那么它们必然会被gc回收掉。回收掉后,引用对象依然存在,只是值为null了,这也是上文提到从entry中得到的ValueReference要判断的原因了。
/**
* Drain the key and value reference queues, cleaning up internal entries containing garbage
* collected keys or values.
*/
@GuardedBy("this")
void drainReferenceQueues() {
if (map.usesKeyReferences()) {
drainKeyReferenceQueue();
}
if (map.usesValueReferences()) {
drainValueReferenceQueue();
}
}
如何失效,因为k和v的失效方法基本一样,只举例drainValueReferenceQueue。(执行前都会tryLock,执行时保证有锁)
void drainValueReferenceQueue() {
Reference ref;
int i = 0;
while ((ref = valueReferenceQueue.poll()) != null) {
@SuppressWarnings("unchecked")
ValueReference valueReference = (ValueReference) ref;
// 回收
map.reclaimValue(valueReference);
if (++i == DRAIN_MAX) {
break;
}
}
}
如何回收呢
- map是segment维护的cache的引用,再次hash到segment。
- 找到segment后,加锁,hash找到entry table。遍历链表,根据key找到一个entry。
- 如果找到,且跟入参的valueReference==比较相等,执行removeValueFromChain(一会细讲)。
- 如果没找到,返回false。
- 如果找到,不等,返回false。
removeValueFromChain
ReferenceEntry removeValueFromChain(ReferenceEntry first,
ReferenceEntry entry, @Nullable K key, int hash, ValueReference valueReference,
RemovalCause cause) {
enqueueNotification(key, hash, valueReference, cause);
writeQueue.remove(entry);
accessQueue.remove(entry);
if (valueReference.isLoading()) {
valueReference.notifyNewValue(null);
return first;
} else {
return removeEntryFromChain(first, entry);
}
}
- 需要执行remove的通知,入队列。
- 针对LoadingValueReference,直接返回。
- 非loading执行移除。
具体如何执行remove呢?removeEntryFromChain
ReferenceEntry removeEntryFromChain(ReferenceEntry first,
ReferenceEntry entry) {
int newCount = count;
ReferenceEntry newFirst = entry.getNext();
for (ReferenceEntry e = first; e != entry; e = e.getNext()) {
// 这个方法是copy当前结点(e),然后将新的结点指向newFirst,返回copy得到的结点(next)。
// 如果改entry是需要回收的,那么该方法返回null。
ReferenceEntry next = copyEntry(e, newFirst);
if (next != null) {
newFirst = next;
} else {
// 如果偶遇k或者v已经回收了的entry,进入需要通知的队列。
removeCollectedEntry(e);
newCount--;
}
}
this.count = newCount;
return newFirst;
}
这段逻辑是,从first开始,一直到要remove结点(entry)的next(newFirst),依次copy每个结点,指向newFirst,然后将newFirst变成自身。最后这条链表的头就变成,最后copy的那个结点,也就是entry的上一个结点。不过为什么要copy呢?
3. Cache的失效和回调
基于读写时间失效
失效逻辑和过程:
-
Entry在进行一次读写操作后,会标识accessTime和writeTime。
f (map.recordsAccess()) { entry.setAccessTime(now); } if (map.recordsWrite()) { entry.setWriteTime(now); } -
accessQueue和writeQueue分别会在读写操作适时的添加。
accessQueue.add(entry); writeQueue.add(entry); -
遍历accessQueue和writeQueue
void expireEntries(long now) { drainRecencyQueue(); ReferenceEntry -
判断是否失效
if (expiresAfterAccess() && (now - entry.getAccessTime() >= expireAfterAccessNanos)) { return true; } removeEntry就是调用上文的removeValueFromChain。
write链(writeQueue)和access链(accessQueue)
这两条链都是一个双向链表,通过ReferenceEntry中的previousInWriteQueue、nextInWriteQueue和previousInAccessQueue、nextInAccessQueue链接而成,但是以Queue的形式表达。
WriteQueue和AccessQueue都是自定义了offer、add(直接调用offer)、remove、poll等操作的逻辑。
- 对于offer(add)操作,如果是新加的节点,则直接加入到该链的队首,如果是已存在的节点,则将该节点链接的链首。(head始终保持在队首,新节点不断插入到队首。逻辑上最先插入的结点保持在,允许访问的头部)
- 对remove操作,直接从该链中移除该节点;
- 对poll操作,将头节点的下一个节点移除,并返回。
代码如下:
@Override
public boolean offer(ReferenceEntry entry) {
// unlink
connectAccessOrder(entry.getPreviousInAccessQueue(), entry.getNextInAccessQueue());
// add to tail
connectAccessOrder(head.getPreviousInAccessQueue(), entry);
connectAccessOrder(entry, head);
return true;
}
失效的通知回调
enqueueNotification
void enqueueNotification(@Nullable K key, int hash, ValueReference valueReference,
RemovalCause cause) {
totalWeight -= valueReference.getWeight();
if (cause.wasEvicted()) {
statsCounter.recordEviction();
}
if (map.removalNotificationQueue != DISCARDING_QUEUE) {
V value = valueReference.get();
RemovalNotification notification = new RemovalNotification(key, value, cause);
map.removalNotificationQueue.offer(notification);
}
}
- 首先判断移除的原因RemovalCause:EXPLICIT(remove、clear等用户有预期的操作),REPLACED(put、replace),COLLECTED,EXPIRED,SIZE。RemovalCause有个方法wasEvicted,表示是否是被驱逐的。前两种是false,后三种是true。
- cause.wasEvicted(),只是对命中的计数略有不同。
- 生成一个notification对象,入队列。
removalNotificationQueue何时被清理
在读写操作的finally阶段,都会执行。
void processPendingNotifications() {
RemovalNotification notification;
while ((notification = removalNotificationQueue.poll()) != null) {
try {
// 这里就是回调构造cache时注册的listener了
removalListener.onRemoval(notification);
} catch (Throwable e) {
logger.log(Level.WARNING, "Exception thrown by removal listener", e);
}
}
}
二、Cache的统计功能
1. CacheStats
描述了cache的统计方便的表现,类的实例是不可变的。其中包含了以下属性:
private final long hitCount;//命中次数
private final long missCount;// 未命中次数
private final long loadSuccessCount;//load成功的次数
private final long loadExceptionCount;//load发生异常的次数
private final long totalLoadTime;//执行load所花费的时间
private final long evictionCount;//被移除的entry的数量
提供的方法:
requestCount()//总体请求次数
hitRate()//命中率
missRate()//未命中率
loadCount()//执行load的总数
loadExceptionRate()
averageLoadPenalty()//平均执行load所花费的时间
统计对象的比较
CacheStats minus(CacheStats other)//表示两个缓存统计的区别
CacheStats plus(CacheStats other)//表示两个缓存统计的总和
2. StatsCounter
提供了在操作缓存过程中的统计接口比如命中、未命中、成功load时间、异常load时间、返回一个CacheStats的snapshot。
SimpleStatsCounter是一个线程安全的实现类。代码中利用的是LongAdder。而不是AtomicLong。
这篇文章对LongAdder有着详细的阐述,http://coolshell.cn/articles/11454.html(作者是追风)
为什么说LongAdder引起了我的注意,原因有二:作者是Doug lea ,地位实在举足轻重。他说这个比AtomicLong高效。
三、Cache配置
现在,已经大致了解guava cache的结构,再来看cache的配置就一目了然了。
在Effective Java第二版中,Josh Bloch在第二章中就提到使用Builder模式处理需要很多参数的构造函数。他不仅展示了Builder的使用,也描述了相这种方法相对使用带很多参数的构造函数带来的好处。在本文的结尾我将进一步总结Builde模式的优点。需要指出的是Josh Bloch已经在他的书本贯穿了这一思想。
Guava Cache它为我们提供了CacheBuilder工具类来构造不同配置的Cache实例。
1. CacheBuilder
参数
Map相关变量和初始值
-
map的容量相关
private static final int DEFAULT_INITIAL_CAPACITY = 16; // 默认的初始化Map大小 static final int UNSET_INT = -1; int initialCapacity = UNSET_INT; int concurrencyLevel = UNSET_INT; long maximumSize = UNSET_INT; long maximumWeight = UNSET_INT; -
CONCURRENCY_LEVEL:这个参数决定了其允许多少个线程并发操作修改该数据结构。这是因为这个参数是最后map使用的segment个数,而每个segment对应一个锁,因此,对于一个map来说,并发环境下,理论上最大可以有segment个数的线程同时安全地操作修改数据结构。
private static final int DEFAULT_CONCURRENCY_LEVEL = 4; // 默认并发水平
补充变量:
-
权重:用来定量每个entry的权重;
Weigher weigher; -
key和value的引用类型:
Strength keyStrength; Strength valueStrength; -
失效时间和刷新时间:
private static final int DEFAULT_EXPIRATION_NANOS = 0; // 默认超时 private static final int DEFAULT_REFRESH_NANOS = 0; // 默认刷新时间 long expireAfterWriteNanos = UNSET_INT; long expireAfterAccessNanos = UNSET_INT; long refreshNanos = UNSET_INT; -
key和value的比较相等的策略:
Equivalence -
失效的回调逻辑:
RemovalListener removalListener;
构造
采用默认参数构造一个CacheBuilder。
public static CacheBuilder newBuilder() {
return new CacheBuilder();
}
通过builder的方法,设置参数。
public CacheBuilder initialCapacity(int initialCapacity) {
checkState(this.initialCapacity == UNSET_INT, "initial capacity was already set to %s",
this.initialCapacity);
checkArgument(initialCapacity >= 0);
this.initialCapacity = initialCapacity;
return this;
}
通过build方法生成cache
-
默认配置
publicCache -
带cacheLoader
publicLoadingCache
2. LocalCache
从CacheBuilder中的build()方法看出,生成的cache分别是LocalManualCache和LocalLoadingCache。之前还说过,LocalCache作为缓存的直接实现,LocalManualCache和LocalLoadingCache分别利用LocalCache去实现cache接口,对外提供功能。
-
LocalManualCache的构造
LocalManualCache(CacheBuilder builder) { this(new LocalCache -
LocalLoadingCache的构造
LocalLoadingCache(CacheBuilder builder, CacheLoader loader) { super(new LocalCache
LocalCache的构造:从构造函数可以看到,Cache的所有参数配置都是从Builder对象中获取的,Builder完成了作为该模式最典型的应用,多配置参数构建对象。
/**
* Creates a new, empty map with the specified strategy, initial capacity and concurrency level.
*/
LocalCache(
CacheBuilder builder, @Nullable CacheLoader loader) {
concurrencyLevel = Math.min(builder.getConcurrencyLevel(), MAX_SEGMENTS);
keyStrength = builder.getKeyStrength();
valueStrength = builder.getValueStrength();
keyEquivalence = builder.getKeyEquivalence();
valueEquivalence = builder.getValueEquivalence();
maxWeight = builder.getMaximumWeight();
weigher = builder.getWeigher();
expireAfterAccessNanos = builder.getExpireAfterAccessNanos();
expireAfterWriteNanos = builder.getExpireAfterWriteNanos();
refreshNanos = builder.getRefreshNanos();
removalListener = builder.getRemovalListener();
removalNotificationQueue = (removalListener == CacheBuilder.NullListener.INSTANCE)
? LocalCache.>discardingQueue()
: new ConcurrentLinkedQueue>();
ticker = builder.getTicker(recordsTime());
entryFactory = EntryFactory.getFactory(keyStrength, usesAccessEntries(), usesWriteEntries());
globalStatsCounter = builder.getStatsCounterSupplier().get();
defaultLoader = loader;
int initialCapacity = Math.min(builder.getInitialCapacity(), MAXIMUM_CAPACITY);
if (evictsBySize() && !customWeigher()) {
initialCapacity = Math.min(initialCapacity, (int) maxWeight);
}
// Find the lowest power-of-two segmentCount that exceeds concurrencyLevel, unless
// maximumSize/Weight is specified in which case ensure that each segment gets at least 10
// entries. The special casing for size-based eviction is only necessary because that eviction
// happens per segment instead of globally, so too many segments compared to the maximum size
// will result in random eviction behavior.
int segmentShift = 0;
int segmentCount = 1;
while (segmentCount < concurrencyLevel
&& (!evictsBySize() || segmentCount * 20 <= maxWeight)) {
++segmentShift;
segmentCount <<= 1;
}
this.segmentShift = 32 - segmentShift;
segmentMask = segmentCount - 1;
this.segments = newSegmentArray(segmentCount);
int segmentCapacity = initialCapacity / segmentCount;
if (segmentCapacity * segmentCount < initialCapacity) {
++segmentCapacity;
}
int segmentSize = 1;
while (segmentSize < segmentCapacity) {
segmentSize <<= 1;
}
if (evictsBySize()) {
// Ensure sum of segment max weights = overall max weights
long maxSegmentWeight = maxWeight / segmentCount + 1;
long remainder = maxWeight % segmentCount;
for (int i = 0; i < this.segments.length; ++i) {
if (i == remainder) {
maxSegmentWeight--;
}
this.segments[i] =
createSegment(segmentSize, maxSegmentWeight, builder.getStatsCounterSupplier().get());
}
} else {
for (int i = 0; i < this.segments.length; ++i) {
this.segments[i] =
createSegment(segmentSize, UNSET_INT, builder.getStatsCounterSupplier().get());
}
}
}