导语
数据持久化是一种非易失性存储技术,在重启动计算机或设备后也不会丢失数据,是将内存中的数据模型转换为存储模型,以及将存储模型转换为内存中的数据模型的统称。数据模型可以是任何数据结构或对象模型,存储模型可以是关系模型、XML、二进制流等。持久化技术主要用于MVC模型中的model层。目前iOS平台上主要使用如下的四种技术:
一.NSUserDefaults(关键词:属性列表、xml序列化)
什么是NSUserDefaults?
在介绍NSUserDefaults之前,我们有必要先了解属性列表的概念:属性列表是一种基于xml序列化的数据永久存储文件,又称plist文件,原理是将一些基本数据类型读写进plist文件(注:plist文件是xml格式文件,因为常用于存储配置信息,所以又称作plist格式文件)并以明文方式存储于设备中。许多OC的基本数据类型(如NSArray、NSString等)本身提供了向plist文件读写的方法,但实际项目中我们用的更多的是NSUserDefaults,NSUserDefaults是苹果基于属性列表所封装的一个单例类,该类提供了基本数据类型的plist文件存储方法,因其使用方便,代码易懂,NSUserDefaults成为了最常用的数据持久化方式之一。
NSUserDefaults常用方法
//从 NSUserDefaults 中取出 key 值所对应的 Value
id = [[NSUserDefaults standardUserDefaults] objectForKey:(NSString *)];
//将数据对象存储到 NSUserDefaults 中
[[NSUserDefaults standardUserDefaults] setObject:(id)
forKey:(NSString *)];
//将数据对象从 NSUserDefaults 中移除
[[NSUserDefaults standardUserDefaults] removeObjectForKey(NSString *)];
//同步更新到Plist文件,当修改了 NSUserDefaults 的数据后,必须进行此步操作
[[NSUserDefaults standardUserDefaults] synchronize];
NSUserDefaults特点
- NSUserDefaults常用于存储OC基本数据类型,不适合存储自定义对象,NSUserDefaults支持的数据类型有:NSNumber(NSInteger、float、double),NSString,NSDate,NSArray,NSDictionary,BOOL.
- 自定义对象可以转化成基本类型NSData后再使用NSUserDefaults进行存储,但并不常用。
- 当plist文件存储的数据发生改变(写操作)时,需要调用synchronize方法同步,否则数据无法同步保存。
- Key值应具有唯一性,重名时将覆盖先前的key值。
- 实际开发中,NSUserDefaults常用于存储配置信息,优点是简便,缺点是所有数据都以明文存储在plist文件中,容易被解读导致安全性不高。
二.对象归档(关键词:序列化)
什么是对象归档?
和属性列表一样,对象归档也是将对象写入文件并保存在硬盘内,所以本质上是另一种形式的序列化(储存模型不同)。虽说任何对象都可以被序列化,但只有某些特定的对象才能放置到某个集合类(例如:NSArray、NSMutableArray、NSDictionary、NSData等)中,并使用该集合类的方法在属性列表存储中读写,一旦将包含了自定义对象的数组写入属性列表,程序就会报错。归档与属性列表方式不同,属性列表只有指定的一些对象才能进行持久化且明文存储,而归档是任何实现了NSCopying协议的对象都可以被持久化,且归档后的文件是加密的。对象归档涉及两个类:NSKeyedArchiver和NSKeyedUnarchiver,这两个类是NSCoder的子类,分别用于归档以及解档。下面将介绍如何对自定义对象进行归档。
对象归档示例
现在,我们有一个自定义的Person类,该类有name,age,height三个属性,其.h文件如下
//Person.h
#import
@interface Person:NSObject
@property(nonatomic,copy)NSString *name;
@property(nonatomic,assign)int age;
@property(nonatomic,assign)double height;
在.m文件中,我们要实现NSCoding中的两个协议方法,这两个方法分别在归档和解档时会被调用,Person类的.m文件如下
//Person.m
#import"Person.h"
@implementation Person
/*
* 归档时调用该方法,该方法说明哪些数据需要储存,怎样储存
*/
- (void)encodeWithCoder:(NSCoder *)encoder
{
[encoder encodeObject:_name forKey:@"name"];
[encoder encodeInt:_age forKey:@"age"];
[encoder encodeDouble:_name forKey:@"height"];
}
/*
* 归档时调用该方法,该方法说明哪些数据需要解析,怎样解析
*/
-(id)initWithCoder:(NSCoder *)decode
{
if (self = [super init]) {
_name = [decode decodeObjectForKey:@"name"];
_age = [decode decodeIntForKey:@"age"];
_height = [decode decodeDoubleForKey:@"height"];
}
return self;
}
@end
这个Person类就具有了归档与解档能力,当你需要对一个Person类的实力对象进行储存或者解析时,在你自己的方法中只要键入如下代码即可,下面两个方法对应两个按钮的回调,点击按钮时分别执行person对象的归档和解档。
//写操作
- (IBAction)Write {
Person *p = [[Person alloc]init];
p.name = @"jin";
p.age = 10;
p.height = 176.0;
//设置归档后文件路径
NSString *path = @"/Users/macbookair/Desktop/person.data";
//归档
[NSKeyedArchiver archiveRootObject:p toFile:path];
}
//读操作
- (IBAction)read {
//设置路径
NSString *path = @"/Users/macbookair/Desktop/person.data";
//解档
Person *p = [NSKeyedUnarchiver unarchiveObjectWithFile:path];
NSLog(@"%@--%d---%f",p.name ,p.age ,p.height);
}
对象归档特点
- 可以将自定义对象写入文件或从文件中读出。
- 由于归档时进行了加密处理,因此安全性高于属性列表。
三.CoreData(关键词:集成化)
什么是CoreData?
当你的应用程序需要在本地存储大量的关系型数据模型时,显然上述方法并不适合,因为不论对象归档还是数据列表,一旦数据模型之间存在依赖关系,问题就将变得复杂。而此时iPhone自带的轻量级数据库Sqlite便成为我们的首选,如果你熟悉数据库,那么恭喜,CoreData也将不再神秘,你可以理解为它是苹果对Sqlite封装的一个框架,你可以在Xcode中进行Sqlite数据库的可视化操作。倘若你对Sqlite感到陌生,那么本文最后也将对Sqlite进行简单的讲解。
如何使用CoreData?
1.新建自带CoreData文件的工程项目,当你创建成功后,左边文件列表里将看到xxx.xcdatamodeld。并且在AppDelegate类中会自动生成一系列相关属性和方法用于管理CoreData。当然你也可以为已有项目添加CoreData文件,不过AppDelegate类则需要你重新构造相关方法。
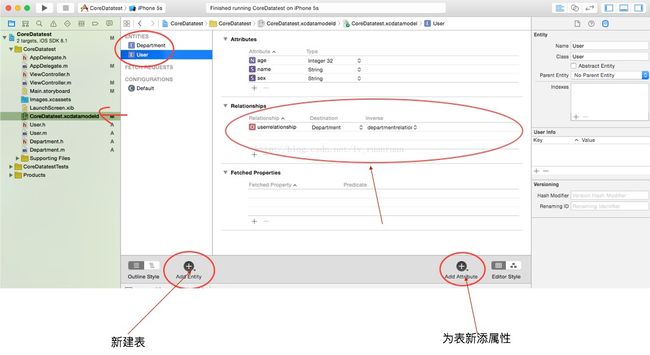
2.点击xxx.xcdatamodeld文件,你会看到一个CoreData文件相当于一个数据库,在这里你可以进行建表、添加属性、连接表与表之间的依赖关系等可视化操作。但是不能进行数据的增删改查,增删改查需要代码中自行实现。这里我们创建了名为User(用户)和Department(部门)两张表
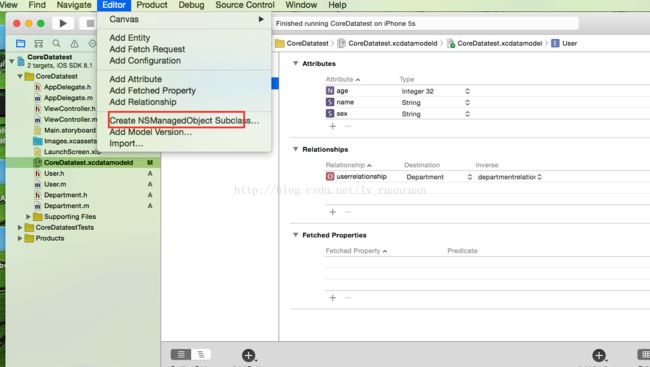
3.设置完表的属性以及关系后,为每张表创建model。如图所示,创建完成后左边文件列表中会多每张表对应的两个文件(iOS7.0以后每张表对应四个文件)
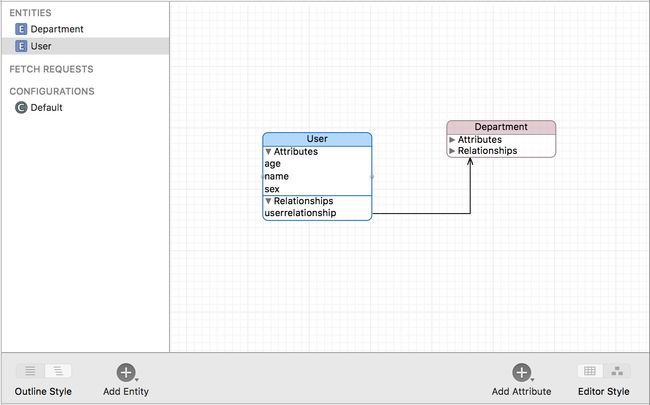
4.至此,CoreData基本配置已经完成,User表和Department表之间也已经建立起联系,点击style可以看到每张表的Attributes及表之间Relationships。
5.如果你熟悉Sqlite,那么接下来我们要做的就是键入代码进行数据的增删改查,实现增删改查之前,我们需要先认识几个核心类。
NSManagedObjectContext: (管理对象上下文) 负责应用和数据库之间的交互
NSPersistentStoreCoordinator: (持久化存储协调器)处理数据存储的连接
NSManagedObjectModel: (对象模型) 代表CoreData模型文件,相当于实体
NSEntityDescription: (实体结构) 用来描述实体
NSPredicate: (查询条件) 相当于Sqlite中的Sql语句
NSFetchRequest: (数据请求) 可以给request设置请求的条件
如何对已经建好实体表进行增删改查?最好的方法是自己再封装一个单利类,该类能够提供表名查询方法,传入某张表名后,我们便可以利用上述的几个核心类提供的一系列方法创建数据的实例变量并读写进表内,如果你是新建的工程项目并勾选了Use Core Data选项,那么AppDelegate类会自动生成一些CoreData的管理方法(这些方法在你自己封装过程中可以借鉴)供我们直接使用。现仅以User表举例实现增删改查,以下.m文件里包含了四个xib创建的Button的回调,当你点击按钮后,分别会向User表增删改查某个用户的个人信息。
//ViewController.m
#import "ViewController.h"
#import "User.h"
#import "AppDelegate.h"
#import
@interface ViewController()
@property(nonatomic,strong)AppDelegate *app;
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
self.app = [UIApplication sharedApplication].delegate;
}
//insert增
- (IBAction)coreDataInsert {
//1.初始化一个user数据
User *user = [NSEntityDescription insertNewObjectForEntityForName:@"User" inManagedObjectContext:self.app.managedObjectContext];
user.name = @"lcc";
user.sex= @"boy";
user.age = @15;
//2.保存
[self.app.managedObjectContext save:nil];
}
//delete删
- (IBAction) coreDataDelete {
//1.读取所有用户
NSEntityDescription *entity = [NSEntityDescription entityForName:@"User" inManagedObjectContext:self.app.managedObjectContext];
//2.建立请求
NSFetchRequest *request = [[NSFetchRequest alloc]init];
[request setEntity:entity];
//3.设置查找条件
NSPredicate *predicate = [NSPredicate predicateWithFormat:@"name =%@",@"lcc"];
[request setPredicate:predicate];
//4.遍历user表,找到该用户后,删除对象
NSArray *array = [self.app.managedObjectContext executeFetchRequest:request error:nil];
if(array.count){
for(User *newUser in array){
//删除该用户
[self.app.managedObjectContext deleteObject:newUser];
}
//保存结果
[self.app.managedObjectContext save:nil];
NSLog(@"删除成功");
}else{
NSLog(@"未找到该用户数据");
}
}
//upDate改
- (IBAction) coreDataUpdate {
//1.读取所有用户
NSEntityDescription *entity = [NSEntityDescription entityForName:@"User" inManagedObjectContext:self.app.managedObjectContext];
//2.建立请求
NSFetchRequest *request = [[NSFetchRequest alloc]init];
[request setEntity:entity];
//3.设置查找条件
NSPredicate *predicate = [NSPredicate predicateWithFormat:@"name = %@",@"lcc"];
[request setPredicate:predicate];
//4.遍历user表,找到该用户后,修改对象
NSArray *array = [self.app.managedObjectContext executeFetchRequest:request error:nil];
if(array.count){
for(User *newUser in array){
//修改该用户
newUser.name = @"lcc2";
}
//保存结果
[self.app.managedObjectContext save:nil];
NSLog(@"修改成功");
}else{
NSLog(@"未找到该用户数据");
}
}
//select查
- (IBAction) coreDataSelect {
//1.读取User表
NSEntityDescription *entity = [NSEntityDescription entityForName:@"User"inManagedObjectContext:self.app.managedObjectContext];
//2.建立请求
NSFetchRequest *request = [[NSFetchRequest alloc]init];
[request setEntity:entity];
//3.遍历所有用户,取出相关用户
NSArray *array = [self.app.managedObjectContext executeFetchRequest:request error:nil];
for (User *user in array){
NSLog(@"%@",user.name);
}
}
@end
如此一来,我们便可以实现已经实体化的User表的增删改查,当然,这里的增删改查相当简便,实际项目中要进行各种情况判断,数据库操作成功失败会有返回信息,该信息应该反馈给用户。此外,因为CoreData并不是线程安全的,如果你希望自己封装一个单利类,那么必须要考虑到数据库的并发操作。
为什么要使用CoreData?
- CoreData脱离了Sql语句,集成化更高。实际上,一个成熟的工程中一定是对数据持久化进行了封装的,应该避免在业务逻辑中直接编写Sql语句。
- CoreData对版本迁移支持的较好,App升级之后数据库字段或者表有更改会导致crash,CoreData的版本管理和数据迁移变得非常有用,手动写sql语句操作相对麻烦一些。
- CoreData不光能操纵SQLite,CoreData和iCloud的结合也很好,如果有这方面需求的话优先考虑CoreData。
- CoreData是支持多线程的,但需要thread confinement的方式实现,使用了多线程之后可以最大化的防止阻塞主线程。
四.Sqlite(关键词:灵活)
什么是Sqlite?
Sqlite是iPhone自带的的数据库管理系统。如果你对数据库和Sql语句不陌生,那么在介绍完CoreData后,你一定不满足CoreData,作为一个程序员,也许你更希望能够直接操作数据库。既然苹果选择Sqlite作为数据库,自然也提供了一系列可以直接操作它的函数(C语言函数),利用这些函数你完全能够自己封装一个sqlite数据库框架,但同时你必须熟悉sql语句以及C语言语法。我在gitHub上上传了一个自己封装的轻量级Sqlite框架LCCSqliteManager 。目前版本只实现了一些基本的数据库功能,如果感兴趣你可以参考一下。
如何直接操作Sqlite?
libsqlite3.0这个函数库提供了许多C语言函数用于直接操作Sqlite,你的项目中导入该函数库即可,具体导入方法LCCSqliteManager的文档中有说明,这里不在过多详述,仅介绍几个核心函数。
/*
** 打开或创建数据库
* char * filePath : 文件路径 (UTF-8)
* sqlite3 **ppDb : 指向数据库文件指针的指针
*/
int sqlite3_open(const char* filePath, sqlite3** ppDb);
//你可以这样调用该函数
sqlite3 *_sqlite;
NSString *filePath = [NSHomeDirectory()stringByAppendingFormat: @"/Documents/%@.sqlite",filename];
int result = sqlite3_open([filePath UTF8String], &_sqlite);
if (result != SQLITE_OK) {
NSLog(@"error:数据库%@打开失败",filename)
}
/*
** 关闭数据库
sqlite3* : 指向该数据库的指针
*/
int sqlite3_close(sqlite3*);
/*
** 创建一张表
*/
SQLITE_API int SQLITE_STDCALL sqlite3_exec(
sqlite3*, /* 非空数据库指针 */
const char *sql, /* 用于创建表的SQL语句 */
int (*callback)(void*,int,char**,char**), /* 回调函数 */
void *, /* 第一个参数回调 */
char **errmsg /* 错误信息 */
);
//第三、四个参数一般传入NULL即可。你可以这样调用该函数
char *error = NULL;
sqlite3 *_sqlite;
NSString *targetSql = @"CREATE TABLE User(name TEXT,age INT,SEX TEXT)"
int result = sqlite3_exec(_sqlite, [targetSql UTF8String], NULL, NULL, &error);
if (result != SQLITE_OK) {
NSLog(@"创建表失败:%s", error);
return NO;
}
/*
** 预编译sql语句
*/
int sqlite3_prepare_v2(
sqlite3 *db, /* 非空数据库指针 */
const char *zSql, /* 要执行的SQL语句 */
int nByte, /* zSql字节的最大长度 */
sqlite3_stmt **ppStmt, /* 能够使用sqlite3_step()执行的编译好的准备语句的指针 */
const char **pzTail /* 超过zSql最大长度的的剩余部分*/
);
/*
** 执行预编译好的sql语句。
*/
int sqlite3_step(sqlite3_stmt*);
/*
** 释放内存。
*/
int sqlite3_finalize(sqlite3_stmt *pStmt);
上述三个方法配套使用,一般在含有查找操作的sql语句时都需要预编译后再执行,并且手动释放内存。
上面的方法比较常用,表的删除和修改操作因为都需要查找操作,所以需要sqlite3_prepare_v2 和sqlite3_step配合使用,sqlite3_exec同样可以执行sql语句,因为增加和查找数据一般不需要预编译。两者具体的区别这里不在过多阐述,读者可以根据参数的不同自行理解,或者查找网上有关libsqlite3.0函数库的相关技术博客,该函数库的大部分函数以及参数作用都有详细解释。
Sqlite和CoreData相比的优劣
- 直接操作Sqlite更容易理解数据的存储方式,灵活度更高。
- 在大量数据的批量读写速度上,Sqlite占有优势。
- Sqlite需要自己写Sql语句,且多线程、批量操作等都需要代码实现。
总结
本文大致介绍了iOS的四种数据持久化方式,且对他们之间的关系进行了一定讲解,笔者在封装过LCCSqliteManager后,反而更倾向于使用CoreData,因为其更稳定便捷,而大部分项目中,NSUSerDefaults与CoreData基本可以满足数据持久化需求,所以笔者较为推荐。
最后感谢阅读,也欢迎提出宝贵意见或纠正错误。