写在前面:强烈推荐阅读此文提到的思考问题。
相关定义
对数几率分布
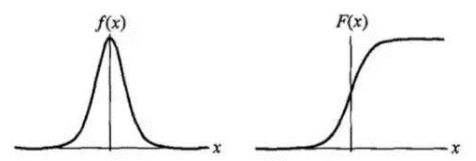
设是连续随机变量,服从对数几率分布是具有以下分布函数和密度函数(分布函数的导数):
其中,称为形状参数,值越小,在临界点附近增长的越快。
下图(来自《统计学习方法》-李航)为密度函数和分布函数的示意图:
条件概率
来源:https://blog.csdn.net/u014722627/article/details/70332459
对于一组随机变量,其中某些变量取特定值时,其余变量的分布称为条件概率分布。
假设数据集共有个样本,记第个样本输入(维向量)和样本标签分别为,,条件概率与参数有关,正确分类的条件概率可以写为 ,简写为 。
正确分类概率:
对正确分类概率取对数可以得到:
公式(s.2)等价于
称为示例函数,当条件满足时取1,条件不满足时取 0.
在二分类问题中,表示满足,表示满足{y_i=0},因此可以写为:
两边都取指数,可以得到:
极大似然估计法
参考:
https://baike.baidu.com/item/%E6%9E%81%E5%A4%A7%E4%BC%BC%E7%84%B6%E4%BC%B0%E8%AE%A1/3350286
https://wenku.baidu.com/view/0d9af6aa172ded630b1cb69a.html
极大似然估计法(the Principle of Maximum Likelihood )由高斯和费希尔(R.A.Figher)先后提出,是被使用最广泛的一种参数估计方法,该方法建立的依据是直观的极大似然原理。
重要前提
训练样本的分布能够代表样本的真实分布(满足VC边界),每个样本集的样本都是独立同分布(iid)的随机变量,且有充分多的训练样本。
极大似然原理
在一次抽样中,若得到观测值 ,则选择作为的估计值。使得当 时,样本出现的概率最大。即 利用已知的样本结果,反推最有可能(最大概率,可以认为实验一次就出现的结果概率最大)导致这样结果的参数。
极大似然估计法(MLE)
若总体 X 为离散型
X 取值的概率分布律为:
其中,为未知参数,设是取自总体的样本容量为 的样本,这组样本的一组观测值为,可以得到样本 取到观测值的概率为:
这一概率随 的取值而变化,称为样本的似然函数。
若总体X为连续型
X 的概率密度函数为,其中,为未知参数,设是取自总体的样本容量为 的样本,这组样本的一组观测值为,可以得到样本 落到点的临边(边长分别为的n维立方体)内的概率近似为,则函数:
这一概率随 的取值而变化,称为样本的似然函数。
极大似然估计值
如果 ,则 为参数的极大似然估计值。
形式变换
由于 与有相同的极大值点,连乘操作很容易由于数据量较大导致数据溢出,因此可以考虑对似然函数求对数,由原来的乘法操作转换为加法操作。
求解步骤
写出似然函数,
对似然函数取对数,并整理;
-
对似然函数的对数对 求导,建立方程组:
求解方程组得到
类别不平衡
不平衡问题是指分类任务中不同类别的训练样本数目相差很多的情况。
缺少 高阶连续凸函数、梯度下降法、牛顿法的定义
模型推导
对数几率回归解决的是二分类问题。对于二分类问题,其输出标记为 。
线性回归模型产生的预测值为实值,因此,将实值转换为 0/1 值即可通过线性回归实现对数几率回归。
最理想的转换方法为"单位阶跃函数",即:预测值大于 0 则取 1 ,预测值小于 0 则 取 0,预测值等于 0 可以任意判别。
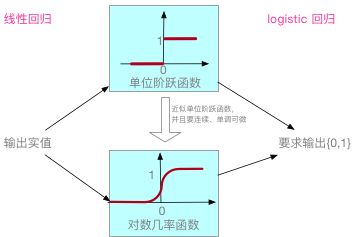
但是由于“单位阶跃函数”不连续,因此选择近似“单位阶跃函数”的对数几率函数进行“替代”,对数几率函数连续并且单调可微,其表达式为:
将 代入,可以得到:
式(1.2)可以整理为:
式(1.3)即为对数几率回归模型,其中,称为“几率”,其中,表示样本作为正例的可能性,表示样本 作为反例的可能性。对“几率”取对数,称为“对数几率”(log odds,也称作 logit ),即式(1.3)等号左侧的部分。
因此,式(1.3)中可以看做使用线性回归模型的预测结果逼近真实标记的“对数几率”。
由于式(1.3) 表示样本 作为正例的可能性, 表示样本 作为反例的可能性。如果将 看做后验概率估计 ,则有:
为了便于讨论,另,,那么,,结合 ,我们可以得到:
这里我们采用“极大似然法”来估计值。
给定数据集 ,我们的目标是最大化“对数似然”:
即令每一个样本属于真实样本的概率越大越好。
式(1.7)可以进一步写为:
因此,我们的目标可以写为:
式(1.9)即为对数几率回归的目标函数,我们对该目标函数进行求解即可得到最优参数。
由于式(1.9)是关于 的高阶可导连续凸函数,根据凸优化理论,经典的数值优化算法如梯度下降法,牛顿法都可以对其进行求导。
softmax 回归
来源:http://deeplearning.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
参考:https://www.cnblogs.com/Deep-Learning/p/7073744.html
| logistic回归模型 | softmax回归模型 | |
|---|---|---|
| 解决问题 | 二分类问题 | 多分类问题 |
| 类别 | 注意:从1开始 |
logistic回归模型是 softmax回归模型 k=2 的特例。
对于给定的测试输入 x,假设函数针对每个类别 j 估算的概率为 。即 我们假设 函数输出一个 维向量(和为 1 ) 表示这 个估计的概率。用公式表示为:
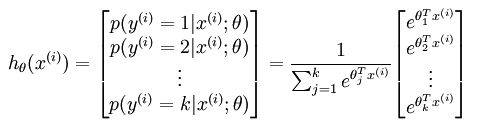
其中,, ,..., ,为归一化系数。
softmax的代价函数为:
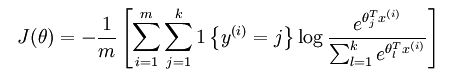
其中:
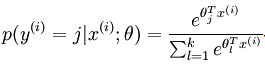
该代价的函数的特点为有一个"冗余"的数据集,为了解决 softmax 回归参数冗余带来的数值问题,我们添加一个权重衰减项目 来修改代价函数,这个衰减项可以惩罚过大的参数,现在代价函数变为:
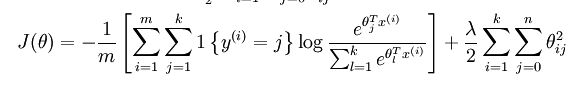
对于的最小化问题,目前还没有闭式解法。因此,使用迭代的优化算法(例如梯度下降法,或 L-BFGS)。经过求导,可以得到梯度公式如下:
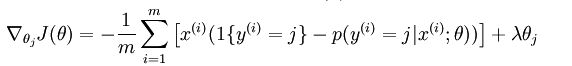
softmax 回归 vs k个二元分类器
如果类别之间相互排斥,使用 softmax 回归。
如果类别之间并不相互排斥,使用 k 个二元分类器。
类别不平衡的基本处理方法
基本策略--再缩放:
这里的 表示训练集的正例数量,表示训练集的反例数量,表示观测几率。
但是我们从训练集的观测几率推断真实几率,现在技术上大体有三类做法:
- 直接对训练集里的反类样例进行“欠采样”,即去除一些反例使正、反例数目接近,再学习;代表算法 EasyEnsemble;
- 对训练集里的正类样例进行‘过采样’,即增加一些正例使正、反例数目接近,再学习;代表算法 SMOTE;
- 直接基于原始训练集进行学习,在用训练好的分类器进行预测时,将再缩放公式嵌入决策过程,称为“阈值移动”
sklearn 相关参数
原文:http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression
sklearn.linear_model.LogisticRegression
Logistic Regression(又称为 logit, MaxEnt) 分类器。
对于多分类的情况,如果 “multi_class” 选项设置为‘ovr’,训练算法将使用 one-vs-rest(OvR)策略;如果 “multi_class” 选项设为 ‘multinormial’,则使用交叉熵损失(cross-entropy loss)(目前,只有‘lbfgs’、'sag' 和 'newton-cg' 算法支持“multinormial”)。
这个类使用 'liblinear' 库、'newton-cg' 、‘lbfgs’、'sag' 求解器实现了正则化 logistic 回归。既可以处理密集输入也可以处理稀疏输入。程序使用 64 位浮点型 C-ordered 序列或 CSR 矩阵以获得最佳性能,任何其他格式的输入都将转化为这种格式(并复制)。
'newton-cg' 、‘lbfgs’、'sag' 求解器只支持原始公式的 L2 正则化。 'liblinear' 求解器支持 L1 和 L2 正则化,并且只为 L2 惩罚提供对偶公式的求解。
更多内容见 用户指南 。
| 参数 | 意义 | 备注 |
|---|---|---|
| penalty | str,'l1' 或'l2' 用于指定正则化函数,'newton-cg' 、‘lbfgs’、'sag' 仅支持 l2 |
0.19版本新增加了支持 l1 惩罚的SAGA 求解器 |
| dual | bool,默认 False 对偶或原始公式。对偶公式只用于使用 liblinear 求解器的 l2 惩罚。 |
当n_samples>n_features (样本较多)时最好设置 dual = False |
| tol | float,默认 1e-4 停止迭代的最小误差。 |
|
| C | float,默认 1.0 正则项系数的倒数,与支持向量机相似,值越小正则化影响越大。 |
必须为正浮点数 |
| fit_intercept | bool,默认 True 决策函数是否需要添加常数( 偏差或截距)。 |
|
| intercept_scaling | float,默认 1 只有使用 liblinear 算法并且 fit_intercept 设为True 时才有用,在这种情况下,x变为[x,self.intercept_scaling],即将值为 intercept_scaling 的“合成”特性添加到实例向量中,截距变为 intercept_scaling*synthetic_feature_weight。 |
合成特性权重与其它特性一样受 l1/l2 正则化影响。为了减少正则化对合成特性权重(以及截距)的影响,需要增大intercept_scaling。 |
| class_weight | dict 或者 'balanced',默认为 None。 {class_label:weight}格式的类别权重。如果没有给定,所有类别的权重都为1。 "balanced"模式使用 y 值自动校正权重,使其为输入数据出现频率的倒数,即 n_samples/(n_classes * np.bincount(y))。 |
如果指定了 sample_weight 则这些权重将与 sample_weight 相乘。 |
| random_state | int, RandomState 实例或 None,可选,默认:None 伪随机数发生器打乱数据时使用的种子(seed) 。如果为 int,random_state 表示随机数发生器的 seed 。如果为 RandomState 实例,random_state 表示随机数发生器。如果为 None,则使用 np.random 使用的RandomState 实例作为随机数发生器。 |
用于 solver 为”sag“或 ”liblinear“的情况。 |
| solver | str , {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}默认:'liblinear' 求解优化问题使用的算法。 小数据集使用”liblinear“是个不错的选择,但是”sag“和”saga“对于较大的数据集速度更快 多分类问题只能使用”newton-cg“,"sag","saga"和”lbfgs“处理多分类损失,”liblinear“限于 one-versus-rest方案。 "newton-cg","lbfgs"和”seg"只支持 L2 正则,“liblinear"和”saga“只支持 L1正则。 |
"sag"和"saga"快速卷积只有在特征规模大致相同时才能保证快速收敛。 可以使用sklearn.preprocessing的缩放器对数据进行预处理。 |
| max_iter | int,默认 100 只用于 newton-cg 、sag 和 lbfgs 算法。用于算法收敛的最大迭代次数。 |
|
| multi_class | str,{‘ovr’, ‘multinomial’,'auto'},默认: ‘ovr’ 如果选择'ovr',将对每个标签进行二分类拟合。对于‘multinomial’,最小化损失为拟合整体概率分布的多分类损失(即使数据为二分类)。liblinear 算法不能使用 ‘multinomial’。 设置为'auth'时,如果数据为二分类或者 solver='liblinear',选择"ovr",其它情况使用’multinomial' |
|
| verbose | int,默认:0 将 verbose 设置为正数来表示 liblinear 和 lbfgs 的冗余。 |
|
| warm_start | bool,默认 False 设置为 True 时,使用上一次调用的解来作为拟合的初始值,否则,只释放上次的解决方案。这项设置对 liblinear 算法不起作用。 |
|
| n_jobs | int,默认 1。 如果 multi_class='ovr'时并行计算类别时使用的处理器数量 。如果“solver"设置为 ”liblinear“,则无论是否设置了”multi_class“,这个参数都将被忽略。 除了 joblib.parallel_backend 之外 None 表示 1,如果值为 -1,则使用所有的处理器。详细内容见Glossary. |
属性:
| 属性 | 意义 | 备注 |
|---|---|---|
| coef_ | array,格式:(1,n_features) 或(n_classes,n_features) 决策函数中特征的系数,二分类问题的 coef_ 格式为 (1,n_features) |
|
| intercept_ | array,格式:(1,) 或(n_classes,) 决策函数的截距,如果 fit_intercept 设置为 False,截距为 0,二分类问题的 intercept_ 格式为(1,) |
|
| n_iter_ | array,格式:(n_classes,)或 (1,) 所有类的实际迭代次数。对于二分类或多分类,只返回1个元素。 liblinear算法只返回所有类的迭代值的最大值。 |