在平常的编程开发中,数据库是我们经常要打交道的内容。本文主要是自己在数据库方面的学习笔记,先对数据库的一些基本理论作介绍,之后详细介绍Java中与数据库相关的JDBC编程的方法、最后简单介绍下Hibernate和MyBatis框架。
一、数据库相关理论
二、MySQL基本使用
三、JDBC编程
四、Hibernate框架
五、MyBatis框架
六、总结
20世纪60年代后期以来,计算机管理的对象规模越来越大,应用范围又越来越广泛,数据量急剧增长,同时多种应用、多种语言互相覆盖地共享数据集合的要求越来越强烈,数据库技术便应运而生,出现了统一管理数据的专门软件系统——数据库管理系统。
一、数据库相关理论
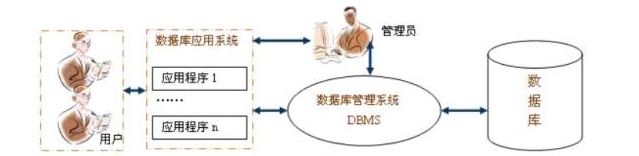
在数据库中,数据不再以各个应用程序各自的要求来分别存储,而是把整个系统所有的数据,根据它们之间固有的关系,分门别类地加以存储。也就是说,数据库是存储在计算机系统内的结构化的、集成的、相关的、共享的和可控制的数据集合。
数据模型
数据模型是数据库系统的核心和基础,任何DBMS都支持一种数据模型。任何一种数据模型都是由3部分组成:1)数据结构:主要描述数据的类型、内容、性质以及数据间的联系等。2)数据操作:主要描述在相应的数据结构上的操作类型和操作方式。3)数据约束:主要描述数据结构内数据间的语法、词义联系、他们之间的制约和依存关系,以及数据动态变化的规则,以保证数据的正确、有效和相容。数据模型主要由三种,分别是层次模型、网状模型和关系模型。
关系模型是目前使用最广泛的数据模型,支持关系模型的DBMS称为关系型数据库管理系统。关系型数据库是一组关系表的集合,关系表是关系模型的数据结构,它用二维表格来组织数据。目前主流的关系型数据库有Mysql、Oracle、SQLServer、DB2、Sybase等等。在下面的内容中,涉及到数据库操作的部分我都是在MySQL数据库中进行的,MySQL是开源的数据库,使用起来很方便。
完整性约束
关系数据库模型的完整性约束是数据库设计的一部分。它的目的是创建检查数据库存储数据的依据和保障数据的正确性。不但可以防止授权用户将不合法的数据存入数据库,还能够避免关系表之间的数据不一致。例如,学生表中学号必须唯一且不能为空,性别只能是男女两个值之一等等。
完整性约束主要由四种,分别是键约束,定义域约束,实体完整性,引用完整性。
- 键约束
关系表中的“键”是指关系表架构中单一属性或者一组属性的集合。键约束是指关系表一定拥有一个唯一和最小的主键。简单的说,主键的目的就是关系表能够从两个及以上的元祖中标识出它们是不同的元祖。
在关系表中还有几个其它的键,超键是关系表中单一熟悉或者一组属性的集合,超键需要满足唯一性。候选键是指满足最小性的超键。外键是关系表的单一或多个属性的集合,其属性值是引用其他关系表的主键。
- 定义域约束
定义域约束是指关系表的属性值一定是定义域的单元值。例如,年龄属性的定义域是int,那么属性值可以是24而不能是24.5。
- 实体完整性
实体完整性是指在基底关系表主键的任何部分都不可以是空值,主键如果是多个属性的集合,任何一个属性都不可以是空值。
- 引用完整性
引用完整性是当关系表存在外键时,外键的值一定来自引用关系表的主键值,或为空值。
关系表的规范化
规范化主要是决定关系表应该拥有哪些属性,其目的是创建良好结构的关系表,去除关系表中的重复数据,去除关系表中的不一致的依赖性,避免在新增、删除或者更新数据时造成错误或者数据不一致的异常情况。关系表的规范化首要工作是处理主键与属性之间的“功能依赖”,它是三级范式的基础。
- 第一范式
第一范式(1NF),是指在关系表中删除多值和复合属性,让关系表只拥有单元值属性。例如,学号和课程组成的学生表中,如果在一条记录中课程属性值同时有语文、数学、英语三门课,那么因为拥有多值属性不符合1NF,应该将这条记录分成3条。
- 第二范式
第二范式(2NF),是指满足第一范式,且关系表没有部分依赖。简单地说,第二范式是指在关系表中,不是主键的属性需要完全依赖于主键。例如,如果在一个表中,有属性学号,姓名,性别,导师编号,导师姓名,导师办公室编号,办公室地址,那么因为导师姓名以及导师办公室编号,办公室地址并非完全依赖主键学号,所以不符合2NF。
- 第三范式
第三范式(3NF),是指满足第二范式,且关系表没有递移依赖。第三范式的目的是移除那些不是直接功能依赖于主键的属性,这些属性是借由另一个属性来功能依赖于主键的。比如上面在第二范式中提到的表,我们将学生表拆分成学生表和导师表两个表,但是导师表中办公室地址并非直接依赖于主键,而是通过办公室编号,不符合3NF。
二、MySQL基本使用
关系型数据库MySQL在现在使用还是比较广泛的,我们平时进行基本的开发时可以安装这个数据库来使用,安装完成后可以使用Navicat来对数据库进行操作。(在开始的学习中建议最好还是在控制台用命令行的方式来操作数据库,Navicat是一个图形化的数据库管理软件,使用它可以很方便地进行数据库管理,但过度依赖图形化操作还是不可取的,当然它也提供了命令行方式我们可以根据需要来选择。)
基本SQL语句
在Navicat中,我们先创建了数据库dbtest,下面主要是通过一些基本操作,来展示SQL,结构化查询语言的使用。
- 创建表
CREATE TABLE tbuser
(userid VARCHAR(10) NOT NULL UNIQUE PRIMARY KEY,
username VARCHAR(15) NOT NULL,
userpasswd VARCHAR(15) NOT NULL,
usersex VARCHAR(2) NOT NULL DEFAULT '男',
userstar INT);
上面就是创建一个用户表的语句,其中userid为主键,usersex表示性别默认值是‘男’。
- 增
//插入一条记录
INSERT INTO tbuser
VALUES('111111','兰博','123123','男',95);
//插入多条记录
INSERT INTO tbuser
VALUES('222222','莫甘娜','133133','女',90),
('333333','巨魔','444444','男',98),
('444444','卡特','555555','女',97);
- 删
//从指定表中删除一条指定记录
DELETE FROM tbuser
WHERE userid='111111';
- 改
UPDATE tbuser
SET username = '卡特琳娜'
WHERE userid = '444444';
- 查
//MySQL数据库中查询语句主要是通过SELECT完成
// 查询表中所有记录
select * from tbuser;
// 查询指定的列
select username
from tbuser;
//查询表中所有记录数
select count(*)
from tbuser;
//查询表 并将结果按照userstar属性值从高到低排列
select * from tbuser
order by userstar desc;
// 以性别分组 查询表中userstar平均值大于88的组别
select avg(userstar)
from tbuser
group by usersex
having avg(userstar) > 88;
- 简单多表查询 点击查看更多
select tbuser.userid,tbuser.username,tbuserdo.userdodetails
from tbuser,tbuserdo
where tbuser.userid = tbuserdo.userdoid;
索引
索引是对数据库表中一个或多个列的值进行排序的结构。创建数据表的索引可以提升SQL查询效率,让用户更快速地得到查询结果。
例如这样一个查询:select * from table1 where id=10000。如果没有索引,必须遍历整个表,直到ID等于10000的这一行被找到为止;有了索引之后(必须是在ID这一列上建立的索引),即可在索引中查找。由于索引是经过某种算法优化过的,因而查找次数要少的多。可见,索引是用来定位的。
创建索引的格式如下:
create index index_pk
on tbuser(userid);
其中index_pk为索引名,on后面是表名,括号内是属性。
数据库索引的** 优点 **主要如下:第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
增加索引也有许多** 不利的方面 **:第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
最后,想要深入了解数据库索引原理的请参考下列文章:数据库索引的实现原理
到目前为止,我们都还只是在数据库系统中直接对数据库进行操作,要真正地开发出一款将数据保存在数据库里的应用,我们必须学会有编程语言来操作数据库。下面主要介绍Java中的数据库编程。
三、JDBC编程
JDBC(Java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序。
JDBC在实际编程中主要经历以下几步:
1、加载JDBC驱动程序
2、提供连接参数
3、建立一个数据库的连接
4、创建一个statement
5、执行SQL语句
6、处理结果
7、关闭JDBC对象
下面是利用JDBC来完成数据库表查询的一个例子。
public class JDBCTest {
public static void main(String[] args) {
String USERNAME = "root";
String USERPASSWD = "314159";
String DRIVER = "com.mysql.jdbc.Driver";
String URL = "jdbc:mysql://localhost:3306/dbtest";
try {
Class.forName(DRIVER);
Connection connection = (Connection) DriverManager.getConnection(URL, USERNAME, USERPASSWD);
Statement statement = connection.createStatement();
String sql = "select userid,username,userstar from tbuser";
ResultSet resultSet = statement.executeQuery(sql);
while (resultSet.next()) {
String userid = resultSet.getString("userid");
String username = resultSet.getString("username");
int userstar = resultSet.getInt("userstar");
System.out.println("ID:" + userid + " 英雄:" + username + " 星数:" + userstar);
}
statement.close();
connection.close();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
不难看到,在上面的例子中,先是用 Class.forName("驱动名"); 表示加载数据库的驱动类,之后提供URL、用户名、密码通过DriverManager.getConnection()来获取获取连接,再之后是执行SQL语句并将结果放在resultSet中,然后遍历结果集合获取到查询的所有数据,最后关闭连接。
四、Hibernate框架
对象关系映射(ORMapping),是软件开发过程中,在数据库层比较流行的设计思想。Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。
Hibernate可以应用在任何使用JDBC的场合,既可以在Java的客户端程序使用,也可以在Servlet/JSP的Web应用中使用,最具革命意义的是,Hibernate可以在应用EJB的J2EE架构中取代CMP,完成数据持久化的重任。
五、MyBatis框架
MyBatis本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis。2013年11月迁移到Github。
iBATIS一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框架。iBATIS提供的持久层框架包括SQL Maps和Data Access Objects(DAO)。
MyBatis 是支持普通 SQL查询,存储过程和高级映射的优秀持久层框架。MyBatis 消除了几乎所有的JDBC代码和参数的手工设置以及结果集的检索。MyBatis 使用简单的 XML或注解用于配置和原始映射,将接口和 Java 的POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
六、总结
以上就是自己对于数据库部分的学习笔记,关于MyBatis框架的使用,在之后的博客中会有介绍,欢迎关注。