
最新修订版本已在个人微信公众号 「AI极客 」发布:
逻辑回归(LR)个人学习总结篇
后续更新文章,首发于个人公众号,敬请关注!
写作计划:
线性模型LR(没有考虑特征间的关联)——>LR +多项式模型(特征组合,不适用于特征稀疏场景,泛化能力弱)——>FM(适用于稀疏特征场景*,泛化能力强)——>FFM【省去零值特征,提高FFM模型训练和预测的速度,这也是稀疏样本采用FFM的显著优势】
0.前言
逻辑回归(LR,Logistic Regression)是传统机器学习中的一种分类模型,由于LR算法具有简单、高效、易于并行且在线学习(动态扩展)的特点,在工业界具有非常广泛的应用。
在线学习算法:LR属于一种在线学习算法,可以利用新的数据对各个特征的权重进行更新,而不需要重新利用历史数据训练。
LR适用于各项广义上的分类任务,例如:评论信息正负情感分析(二分类)、用户点击率(二分类)、用户违约信息预测(二分类)、用户等级分类(多分类 )等场景。
实际开发中,一般针对该类任务首先都会构建一个基于LR的模型作为Baseline Model,实现快速上线,然后在此基础上结合后续业务与数据的演进,不断的优化改进!
1.线性回归模型(Linear Regression)
提到LR,就不得不先从线性回归模型讲起:
概念:对于多维空间中存在的样本点,我们用特征的线性组合(特征加权)去拟合空间中点的分布和轨迹。
有监督训练数据集(X,Y),X表示特征,Y表示标签,w表示该某一特征对应的权重,最终的线性模型如hw(x)所示:
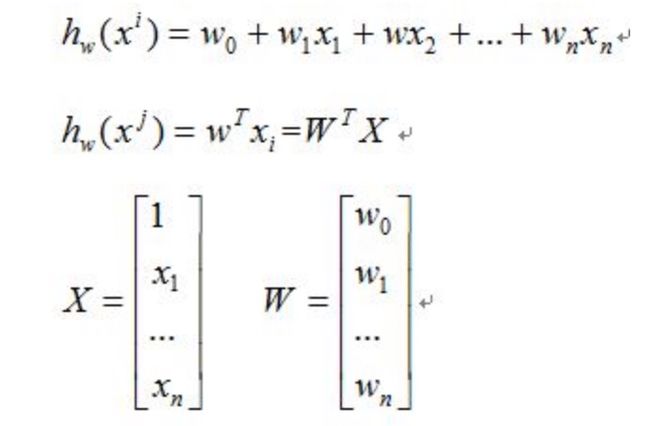
线性回归模型既可以用于回归,也可以用于分类。
- 解决回归问题,可以用于连续目标值的预测。
- 但是针对分类问题,该方法则有点不适应,应为线性回归的输出值是不确定范围的,无法很好的一一对应到我们的若干分类中。即便是一个二分类,线性回归+阈值的方式,已经很难完成一个鲁棒性很好的分类器了。
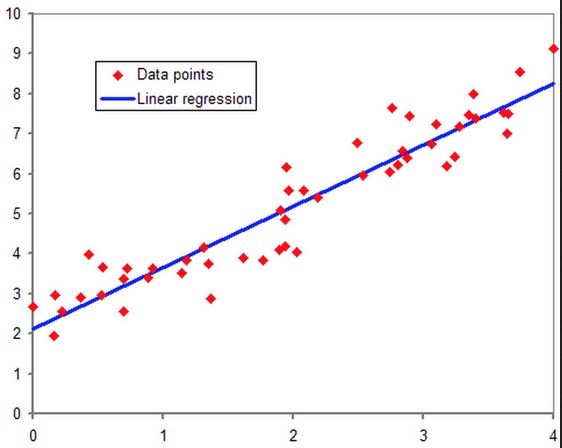
为了更好的实现分类,逻辑回归诞生了。
[逻辑回归是假设数据服从Bernoulli分布,因此LR属于参数模型]
2.逻辑回归(LR)
通过在线性回归模型中引入Sigmoid函数,将线性回归的不确定范围的连续输出值映射到(0,1)范围内,成为一个概率预测问题。
可以把LR看作单层的神经网络。
LR目标函数:
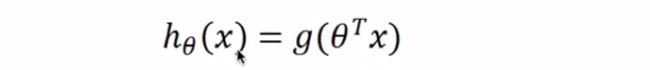
其中Sigmoid函数g(z)的定义如下:
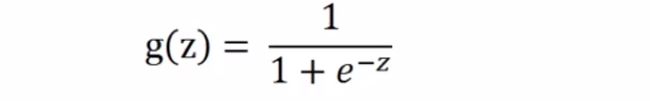
Sigmoid函数的函数图像为:
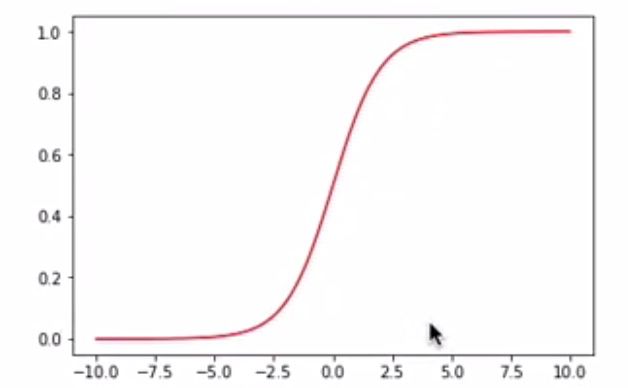
Sigmoid函数的导数形式:
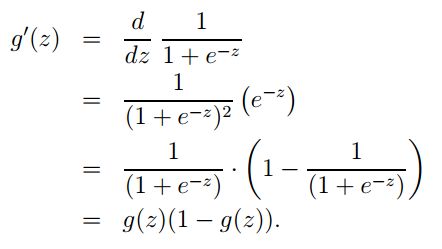
整合一下,LR的单个样本的目标函数为:
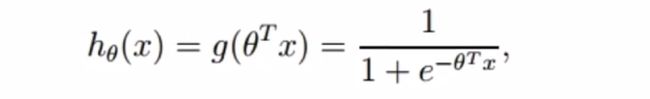
假设有n个独立的训练样本{(x1, y1) ,(x2, y2),…, (xn, yn)},y={0, 1}。那每一个观察到的样本(xi, yi)出现的概率是:
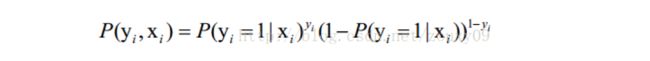
解释一下:
当y=1的时候,后面那一项是不是没有了,那就只剩下x属于1类的概率,当y=0的时候,第一项是不是没有了,那就只剩下后面那个x属于0的概率(1减去x属于1的概率)。所以不管y是0还是1,上面得到的数,都是(x, y)出现的概率。
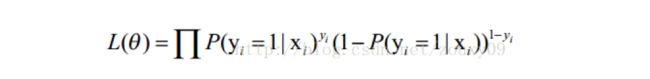
那我们的整个样本集,也就是n个独立的样本出现的似然函数为(因为每个样本都是独立的,所以n个样本出现的概率就是他们各自出现的概率相乘),到整个样本的后验概率:
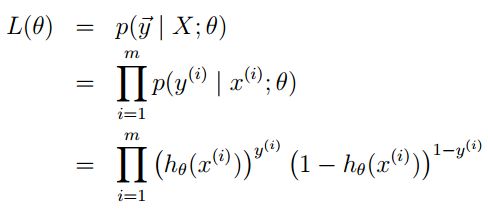
其中:

通过对数进一步化简为,最终LR的目标函数为:
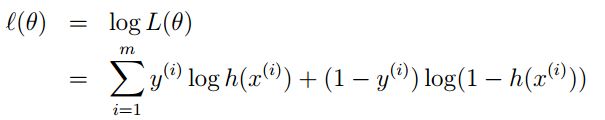
2.1.如何求解模型的参数?
LR模型的数学形式确定后,剩下就是如何去求解模型中的参数。
统计学中常用的一种方法是最大似然估计(MLE),即找到一组参数,使得在这组参数下,我们的数据的似然度(概率)越大。对于该优化问题,存在多种求解方法,这里以梯度下降的为例说明。
梯度下降(Gradient Descent)又叫作最速梯度下降,是一种迭代求解的方法,通过在每一步选取使目标函数变化最快的一个方向调整参数的值来逼近最优值。
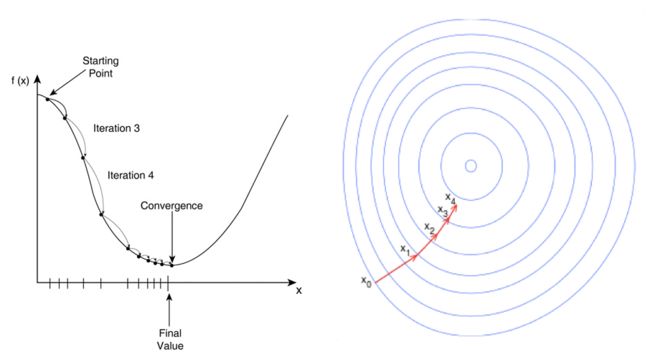
基本步骤如下:
利用链式法对目标函数则进行求导:
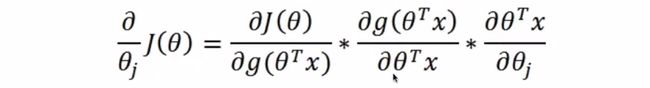
其中,一共可以分为三部分分别求导:
第一部分:

第二部分:
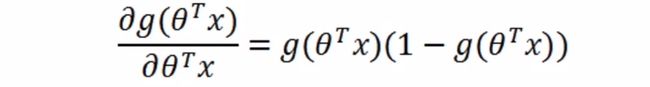
第三部分:
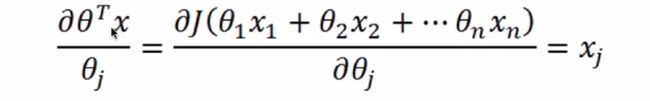
最终整体的求导形式:
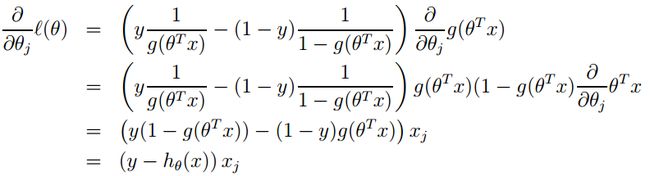
模型参数的更新公式为:
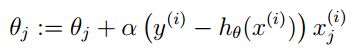
沿梯度负方向选择一个较小的步长可以保证损失函数是减小的,另一方面,逻辑回归的损失函数是凸函数(加入正则项后是严格凸函数),可以保证我们找到的局部最优值同时是全局最优。
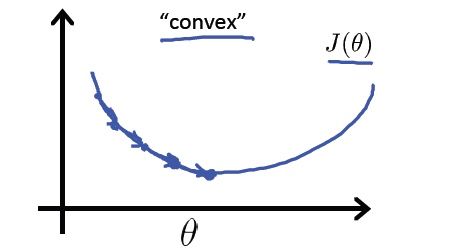
此外,常用的凸优化的方法都可以用于求解该问题。例如共轭梯度下降,牛顿法,LBFGS等。
2.2.python实现LR的核心代码片段
# coding:utf-8
'''
Created on Oct 27, 2010
Logistic Regression Working Module
@author: Peter
代码来源:机器学习实战-第五章的源码片段
'''
def sigmoid(inX):
return 1.0/(1+exp(-inX))
def stocGradAscent(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n) #initialize to all ones
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #apha decreases with iteration, does not
randIndex = int(random.uniform(0,len(dataIndex)))#go to 0 because of the constant
h = sigmoid(sum(dataMatrix[randIndex]*weights))
# 标签的真实值-预测值
error = classLabels[randIndex] - h
# 模型参数更新公式(与我们推导的形式一致)
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
2.3.模型的优化-引入正则化
当模型的参数过多时,很容易遇到过拟合的问题。这时就需要有一种方法来控制模型的复杂度,典型的做法在优化目标中加入正则项,通过惩罚过大的参数来防止过拟合.
引入正则项的LR目标函数:
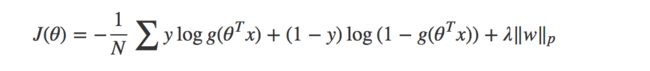
一般情况下,取p=1或p=2,分别对应L1,L2正则化,两者的区别可以从下图中看出来,L1正则化(左图)倾向于使参数变为0,因此能产生稀疏解。
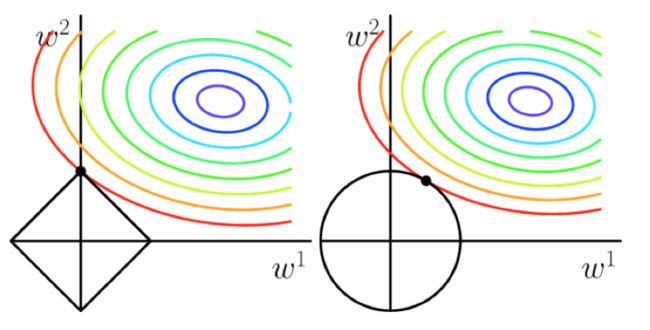
实际应用时,由于我们数据的维度可能非常高,L1正则化因为能产生稀疏解,使用的更为广泛一些。
3.LR如何解决多分类问题?
简言之,把Sigmoid函数换成softmax函数,即可适用于多分类的场景。
Softmax 回归是直接对逻辑回归在多分类的推广,相应的模型也可以叫做多元逻辑回归(Multinomial Logistic Regression)。
softmax函数为:
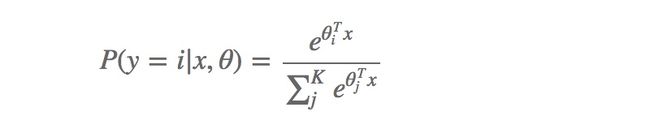
整体的目标函数:
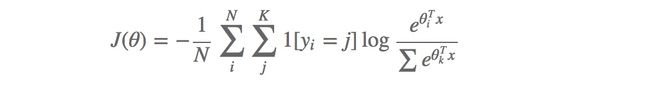
使用softmax的多分类与使用Sigmoid的二分类有什么区别与联系?

通过上面的推导可知,当多分类的K=2时,与使用Sigmoid的二分类是一致的。
4.LR如何解决线性不可分问题?
逻辑回归本质上是一个线性模型,但是,这不意味着只有线性可分的数据能通过LR求解,实际上,我们可以通过2种方式帮助LR实现:
(1)利用特殊核函数,对特征进行变换:把低维空间转换到高维空间,而在低维空间不可分的数据,到高维空间中线性可分的几率会高一些。
(2)扩展LR算法,提出FM算法。
使用核函数(特征组合映射)
针对线性不可分的数据集,可以尝试对给定的两个feature做一个多项式特征的映射,例如:
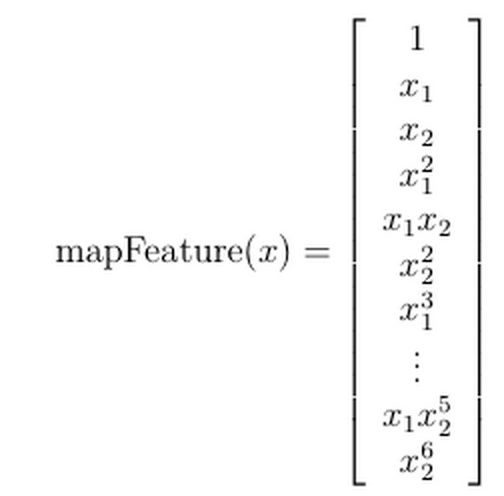
下面两个图的对比说明了线性分类曲线和非线性分类曲线(通过特征映射)

左图是一个线性可分的数据集,右图在原始空间中线性不可分,但是利用核函数,对特征转换 [x1,x2]=>[x1,x2,x21,x22,x1x2]
后的空间是线性可分的,对应的原始空间中分类边界为一条类椭圆曲线。
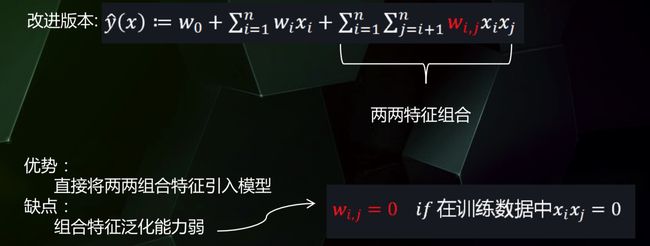
在LR中,我们可以通过在基本线性回归模型的基础上引入交叉项,来实现非线性分类,如下:
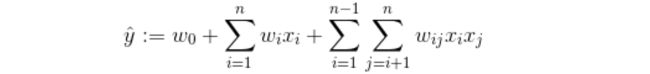
但是这种直接在交叉项xixj的前面加上交叉项系数wij的方式在稀疏数据的情况下存在一个很大的缺陷,即在对于观察样本中未出现交互的特征分量,不能对相应的参数进行估计。
即,在数据稀疏性普遍存在的实际应用场景中,二次项参数的训练是很困难的。其原因是,每个参数 wij的训练需要大量xi和 xj都非零的样本;由于样本数据本来就比较稀疏,满足xi 和 xj都非零”的样本将会非常少。训练样本的不足,很容易导致参数 wij 不准确,最终将严重影响模型的性能。
为什么特征稀疏?
one-hote编码带来的问题
在机器学习中,尤其是计算广告领域,特征并不总是数值型,很多时候是分类值,对于categorical feature,通常会采用one-hot encoding转换成数值型特征,转化过程会产生大量稀疏数据。

可以这么理解:对于每一个特征,如果它有m个可能取值,那么经过one-hot encoding之后,就变成了m个二元特征,并且,这些特征互斥,每次只有一个激活,因此,数据会变得稀疏。
one-hot编码带来的另一个问题是特征空间变大。同样以上面淘宝上的item为例,将item进行one-hot编码以后,样本空间有一个categorical变为了百万维的数值特征,特征空间一下子暴增一百万。所以大厂动不动上亿维度,就是这么来的。
在工业界,很少直接将连续值(eg.年龄特征)作为逻辑回归模型的特征输入,而是将连续特征离散化为一系列0、1特征交给LR。
LR为什么要对连续数值特征进行离散化?
- 离散特征的增加和减少都很容易,易于模型的快速迭代;
- 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
- 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
- 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
- 离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
- 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
- 特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
李沐曾经说过:模型是使用离散特征还是连续特征,其实是一个“海量离散特征+简单模型” 同 “少量连续特征+复杂模型”的权衡。既可以离散化用线性模型,也可以用连续特征加深度学习。就看是喜欢折腾特征还是折腾模型了。通常来说,前者容易,而且可以n个人一起并行做,有成功经验;后者目前看很赞,能走多远还须拭目以待。
使用FM模型
另一种方法是对LR进行扩展,因子分解机(Factorization Machine,FM)是对LR算法的扩展。FM模型是一种基于矩阵分解的机器学习模型,对于稀疏数据具有很好的学习能力;
对于因子分解机FM来说,最大的特点是对于稀疏的数据具有很好的学习能力。
FM解决了LR泛化能力弱的问题,其目标函数如下所示:
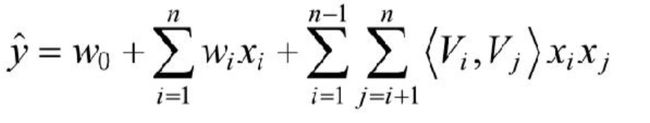
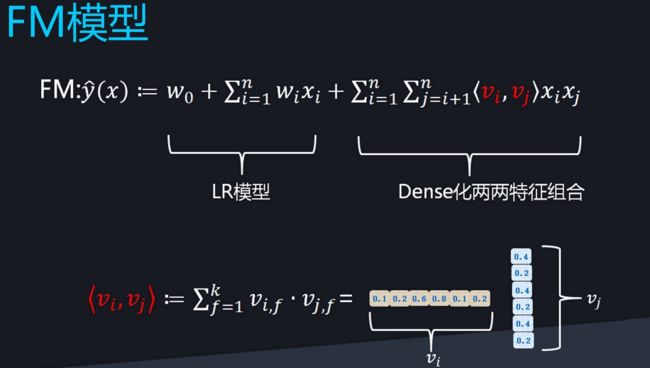
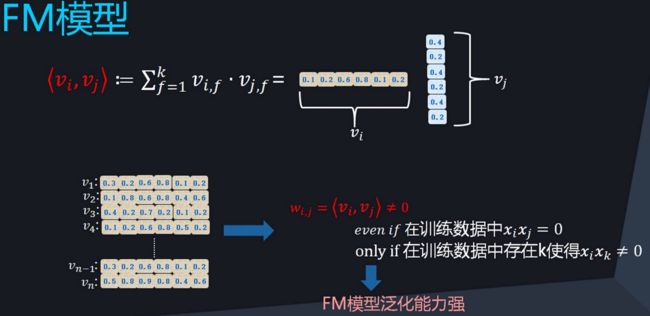
上面两张精简的PPT来自于新浪微博AI-Lab的张俊林老师的技术分享。
后续有时间继续从FM-->FFM开始写
5.面试常问题:
针对学生党的福利时刻,自己记录的几个有关LR的面试题:
LR与SVM的联系与区别:
联系:
1、LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题)
2、两个方法都可以增加不同的正则化项,如l1、l2等等。所以在很多实验中,两种算法的结果是很接近的。
区别:
1、LR是参数模型[逻辑回归是假设y服从Bernoulli分布],SVM是非参数模型,LR对异常值更敏感。
2、从目标函数来看,区别在于逻辑回归采用的是logistical loss,SVM采用的是hinge loss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
3、SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
4、逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
5、logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。
如何选择LR与SVM?
非线性分类器,低维空间可能很多特征都跑到一起了,导致线性不可分。
- 如果Feature的数量很大,跟样本数量差不多,这时候选用LR或者是Linear Kernel的SVM
- 如果Feature的数量比较小,样本数量一般,不算大也不算小,选用SVM+Gaussian Kernel
- 如果Feature的数量比较小,而样本数量很多,需要手工添加一些feature变成第一种情况。
模型复杂度:SVM支持核函数,可处理线性非线性问题;LR模型简单,训练速度快,适合处理线性问题;决策树容易过拟合,需要进行剪枝
损失函数:SVM hinge loss; LR L2正则化; adaboost 指数损失
数据敏感度:SVM添加容忍度对outlier不敏感,只关心支持向量,且需要先做归一化; LR对远点敏感
数据量:数据量大就用LR,数据量小且特征少就用SVM非线性核
什么是参数模型(LR)与非参数模型(SVM)?
在统计学中,参数模型通常假设总体(随机变量)服从某一个分布,该分布由一些参数确定(比如正太分布由均值和方差确定),在此基础上构建的模型称为参数模型;非参数模型对于总体的分布不做任何假设,只是知道总体是一个随机变量,其分布是存在的(分布中也可能存在参数),但是无法知道其分布的形式,更不知道分布的相关参数,只有在给定一些样本的条件下,能够依据非参数统计的方法进行推断。