原文地址Dynamo
摘要
面对世界上最大的电商网站 Amazon.com,我们遇到的最大挑战之一就是海量规模下后台的可靠性;即使是稍微的短暂停止服务,也会造成重大的经济损失,并影响消费者对Amazon的信任。Amazon.com平台提供了许多互联网服务,分布在全世界各地的多个数据中心的数万台服务器以及网络组件共同构建了Amazon的底层基础设施。在这样的规模下,各个组件的失效持续的发生着,在这些失效情况下仍然需要维持一致状态,这个需求驱动着软件系统的可靠性和扩展性的发展。
本文展示了Dynamo的设计和实现,Dynamo是一个高可用的key-value存储系统,Aamzon的一些服务使用它来提供"永远在线"的服务。要达到这个水平的可用性,Dynamo在一些场景下牺牲了一致性。它广泛的使用了对象版本以及应用程序辅助解决冲突的方式,提供了一个新颖的接口给开发者使用。
关键词
算法, 管理, 测量, 性能, 设计, 可靠性.
1. 简介
Amazon运行着一个全球范围的电商平台,高峰期服务于千万级别的消费者,使用了分布在世界各地的多个数据中心的数万台服务器。Amazon平台对性能,可靠性和效率方面有着严格的要求,同时为了支持连续的扩容,还需要很强的扩展性。可靠性是其中最重要的要求之一,因为即使是稍微的停止一下服务,也会造成重大的经济损失,并影响消费者对Amazon的信任。此外,为了支持持续的增长,平台还需要是可扩展的。
从维护Amazon平台中我们学到一点,一个系统的可靠性和扩展性依赖于如何管理应用程序的状态。Amazon使用了一个高度去中心化,松散耦合,面向服务的架构,其中包含了数百个服务。在这个环境中,对存储技术有个特别的需求,那就是必须永远可用。举例来说,用户应该总是可以看到并添加商品到他们的购物车,即使是硬盘坏掉了,网络路线抖动,或者数据中心被龙卷风摧毁。因此,购物车服务使用的数据存储必须永远是可以读取和写入的,并且可以跨越数据中心使用。
在由数百万个组件组成的基础设施中处理故障的情况是我们的标准运作模式。在任意时间,总有一小部分很小但很重要的服务器以及网络组件是处于故障状态。因此,在构建Amazon的软件系统时,必须把这些故障处理看作是普通情况,并且不影响可用性和性能。
为了达到可靠性和扩展性的要求,Amazon开发了一些存储技术,其中Amazon Simple Storage(在Amazon外部也可使用,叫做Amazon S3)可能是最著名的一个。本文了展示了Dynamo的设计与实现,另外一个为Amazon平台设计的,高可用高扩展性的分布式存储技术。Dynamo被用于管理服务的状态,它有着很高的可靠性要求,并且需要严格的处理可用性、一致性、成本效益、性能之间的平衡。Amazon平台包含了各个差异很大的服务,它们对存储的要求各不相同。一部分应用程序需要存储技术足够灵活,让应用程序设计人员能够通过合适的配置来最低成本的达到高可用和高性能。
Amazon平台上有很多服务,只需要通过主键来访问数据。对于那些提供热销列表,购物车,用户偏好,会话管理,商品排名,产品目录的服务来说,使用关系型数据库会导致性能低下,并且限制了扩展性和可用性。Dynamo提供了一个简单的主键接口,来满足这些应用的需求。
Dynammo混合了一些知名的技术来达到扩展性和可用性: 数据的分片和备份使用一致性哈希[1],一致性使用对象版本技术[2]来提供。副本之间的一致性由一个类仲裁技术以及去中心化的同步协议来保证。Dynamo使用了基于gossip的分布式故障探测技术和成员协议。 Dynamo是一个完全的去中心化系统,需要很少的人工管理。存储节点可以随时添加到Dynamo或者从Dynamo中删除,不需要任何人工参与或者重新分布。
在过去一年,Dynamo已经成为了Amazon商务平台的一些核心服务的底层存储技术。它能够在繁忙的假日购物季不停服的扩展到极高的负载。比如,对于负责购物车的服务,一天之内要处理千万级别的请求,导致超过3百万的结算处理;以及会话管理服务,在同一时刻处理这上百万的并发活跃会话。
这项工作对于研发团队最大的贡献是,评估了如何将多个不同的技术结合在一起,以提供一个高可用的系统。它说明了一个最终一致性的存储系统是可以用在生产环境中,并被最严格的应用程序使用的。同时它提供了一些洞见,关于如何调试这些技术以满足生产环境中对性能要求及其严格的应用程序。
本文的结构如下: 第二节讲述背景,第三节介绍相关工作。第四节讲述系统设计,第五节描述了实现。第六节详述了通过在生产环境运行Dynamo得到的经验和洞见,第七节总结了全文。这篇论文有些地方本应该多添加一些信息,但是由于要保护Amazon的商业利益,只能减少细节讨论。出于这个原因,第六节中的数据中心内和跨数据中心延迟,6.2节中的绝对请求速率,6.3节中的停服时长和工作负载,都是总体测量而不是完全的细节。
2. 背景
Amazon商业平台由数百个服务共同组成,它们协同工作,提供包括推荐,完成订单,欺诈检测等功能。每个服务都提供一组定义良好的接口,并且只能通过网络来访问。这些服务运行在位于世界各地的许多数据中心的数万台服务器组成的基础设施之上。其中一些服务是无状态的(比如聚合其他服务响应的服务),一些服务是有状态的(比如执行业务逻辑的服务会根据持久存储中的状态来产生响应)。
传统的生产环境将服务状态存储在关系型数据库中。然而,对于通用的状态存储来说,关系型数据库是远不够理想的。大多数的服务只需要通过主键来读写数据,它们用不上RDBMS提供的哪些复杂的查询和管理功能。这些多出来的功能需要昂贵的硬件以及高技能的人员来维护,导致这种方案非常低效。此外,可用的副本技术是很有限的,而且通常牺牲可用性来达到一致性。虽然近些年出现了很多进展,但数据库的扩容和负载均衡仍然不好做。
本文描述的高可用数据存储技术Dynamo,正是为了满足这一类服务的需求而研发的。Dynamo提供简单的key/value接口,它是高可用的,并有一个定义清晰的一致性窗口,它在资源使用方面是非常高效的,并且有一个简单的扩容方案,以应对数据量或者请求量的增长。每个使用Dynamo的服务都运行它自己的Dynamo实例。
2.1 系统假设和要求
这一类服务的存储系统有如下要求:
查询模型:简单的读写操作, 通过唯一主键。状态被存储为二进制对象,并通过唯一主键识别。没有操作会跨多条数据,同时不需要关系schema。这个要求是基于以下观察得出的:Amazon的服务中有相当大的部分都可以使用这种简单的查询模型,不需要任何关系schema。Dynamo的目标应用程序需要存储的对象都比较小(通常小于1M)。
ACID属性:ACID(原子性,一致性,隔离性,持久性)是一组用于保证数据库事务可以可靠的执行的属性。在数据库中,一个单独的逻辑操作叫做一次事务。根据在Amazon的经验,提供了ACID保证的数据存储系统的可用性都比较差。业界和学术界已经广泛的认识到这一点[3]。Dynamo的目标应用程序需要的是高可用性,在弱一致性的情况下也可以工作。Dynamo不提供任何隔离级别的保证,并且只允许单个key的更新操作。
效率:这个系统需要运行在廉价的硬件设备上。在Amazon平台中,服务都有严格的延迟限制,这个延迟都是在99.9%分位进行测量。由于获取状态在服务逻辑中是比较核心的角色,存储系统必须能够满足这个SLA(参见后面2.2章节)。这些服务必须能够通过配置Dynamo来保证他们的低延迟和高吞吐要求。因此需要在性能,效益,可用性和持久性之间做权衡取舍。
其他假设:Dynamo只会被Amazon内部服务使用。假设它的运行环境是没有敌意的,没有认证鉴权之类的安全要求。除此之外,由于每个服务都使用自己的Dynamo实例,最初的设计是认为Dynamo最多会扩展到上百台主机。 在后续章节我们会继续讨论扩展性的限制以及可用的扩展方案。
2.2 服务水平协议(SLA)
为了保证一个应用程序能够在指定的时间内完成它的所有功能,它所依赖的每个服务则需要在更加严格的时间内完成其功能。客户端和服务端共同遵从服务水平协议,这个协议指定了一些系统相关的特性,其中比较重要的一点是,客户端承若对指定API的请求量,而服务端则承诺在这个请求量下服务的响应延迟。举个简单例子,服务端承若在每秒请求量不超过500时,保证99.9%的请求都可以在300ms内响应。
在Amazon的去中心化面向服务的架构中,SLA扮演着非常重要的角色。比如,当一个页面请求到达渲染引擎时,后者往往需要向后端超过150个服务发送请求,才能构建响应的数据。这些服务又会有很多依赖,而这些依赖又是一些其他服务,因此一个应用的调用栈往往不止一层。为了保证渲染引擎能够在确定的时间范围内响应页面请求,这些服务都需要严格遵守他们的性能约定,也就是SLA。

图1是Amazon平台架构的一个简化描述,其中渲染组件需要向许多其他服务发起请求,以产生最终的动态页面内容。一个服务可以使用多种存储系统来管理它们的状态,并且这些存储系统只有这个服务能够访问。一些服务做着聚合的工作,通过使用几个其他服务来产生一个复合的响应。这些聚合服务一般都是无状态的,虽然他们使用了大量缓存。
业界经常使用平均数,中位数,预期变化来描述SLA。在Amazon,我们发现如果想要构建一个让所有用户满意而不是大部分用户满意的系统,这些测量方式还是不够的。比如,如果为了满足老顾客的需求而大量使用个性化的技术,会影响高位分布的性能。通过中位数来描述的SLA,是不能照顾到那部分重要用户的。为了解决这个问题,Amazon内部都通过99.9%来表示和测量SLA。之所以选择99.9%而不是更高,是基于成本收益的考虑,分析显示当进一步提高性能时,耗费的成本将会显著提高。从维护Amazon生产环境得到的经验看,这种方案相比于使用中位数的SLA,在整体上提供了更好的性能表现。
本文中多次提到99.9%分位,这反映了Amazon的工程师开始从用户的角度来看待性能问题。很多论文报告都用平均数来指定SLA,本文使用了这些报告作为对比之用。然而,Amazon的工作不是针对平均数的,一些技术手段例如负载均衡,完全是用来达到99.9%分位的性能目标的。
存储系统在构建服务的SLA中是非常重要的,特别是像大多数Amzon服务那样,业务逻辑很轻量。状态管理就变成了服务SLA中最核心的组件。Dynamo最重要的设计考虑之一就是,让服务能控制系统属性,比如持久性、一致性,服务能够自己在功能、性能、成本收益方面做出权衡取舍。
2.3 设计考虑
传统商用系统中的数据拷贝算法通常使用同步复制的方式,以保证数据的强一致性。为了达到这种程度的一致性,这些算法被迫在某些故障场景下降低可用性。比如,这些算法不会去处理结果的正确性,而是让数据保持不可用直到确认数据是正确的。从很早的数据库复制研究中可以看到,当需要处理网络故障的情况,强一致性和高可用性是不能同时做到的[4]。因此系统和程序都需要了解在哪种情况下能够达到哪种要求。
对于容易出现服务器和网络故障的系统,可以通过乐观复制技术来提升可用性,在这种方式中,副本的更新操作都在后台进行,可以容忍并发、网络断开的情形。这种方法的问题在于它会导致数据冲突,而冲突是必须被检测到并解决的。解决冲突的过程又引入两个问题:何时解决以及谁来解决。Dynamo被设计为最终一致性的数据存储,也就说所有副本最终会达到一致状态。
一个重要的设计考虑是决定何时去解决更新导致的冲突,即,是应该在读还是写的过程中解决冲突。很多传统的数据存储系统在写的过程中处理冲突,从而保持读操作的简单性[5]。在这种系统中,如果无法在指定的时间内将数据写入到所有副本(或者大部分副本)中时,写操作会被拒绝。另一方面,Dynamo的设计目标是一个"总是可以写入"的数据存储系统,即,一个对写操作来说高可用的存储。对一些Amazon的服务来说,拒绝用户的更新操作会导致很差劲的用户体验。比如,购物车服务必须能够让用户随时的添加和删除商品到他们的购物车中,无论是网络还是服务器出了故障。这个需求迫使我们把冲突解决的复杂性放到读操作中处理,从而保证写操作永远不会被拒绝。
接下来要考虑的是谁来处理冲突。这个既可以让存储系统做,也可以让应用程序做。如果让存储系统来解决冲突,它的选择会相当受限。这样的情况下,存储系统只能用简单的策略来解决冲突,比如"最后一个写有效"[6]。另一方面,应用程序了解数据的结构,它可以据此得到对用户体验最好的数据冲突解决方案。比如,购物车服务可以选择合并冲突的数据,返回一个统一的购物车。尽管这样做很灵活,但是应用程序开发者可能不想写自己的冲突解决方案,而是将问题推给数据存储层,最终导致仍然使用"最后一个写入有效"的简单策略来解决冲突。
其他重要的设计考虑包括:
增量可扩展性:Dynamo应该能够支持一次扩展一个节点,同时最小化对操作者和系统的影响。
对称性:Dynamo中的每个节点都应该和其他节点具有相同的职责;不应该有不同的节点,或者扮演特殊角色的节点。根据我们的经验,对称结构简化了系统的配置和维护。
去中心化:对称性的延伸,系统应该使用去中心化的P2P技术,而不是集中控制。集中控制系统曾经导致停服,我们的目标是尽可能的避免这种情况。这种设计可以得到一个更简单、更易于扩展、可用性更强的系统。
异构性:系统需要有能力利用异构的基础设施。例如,工作负载必须能够根据单个服务器的能力不同来按比例的分配。想要在添加高性能的新节点时避免升级全部的节点,这个能力是至关重要的。
3. 相关研究
3.1 P2P系统
有几个P2P系统曾研究过数据的存储和分布问题。第一代P2P系统,比如Freenet,Gnutella[7],主要用作文件分享系统。这些都是节点间任意连接的非结构化P2P网络的例子。这种网络中充满了查询请求,这些请求都尽力寻找尽可能多的共享数据节点。P2P演化到第二代,也就是知名的结构化P2P网络。这种网络使用了一个全局一致性协议,以保证任意节点都可以将一个查询请求路由到包含需求数据的节点上。像Pastry[8]和Chord[9]之类的系统,使用路由机制来保证查询请求可以在有限的几个网络跳转来回中得到响应。为了减少多跳路由带来的额外延迟,一些P2P系统维护了一个本地路由信息,这样它就可以在常数跳转次数内将请求路由到合适的节点。
各种不同的存储系统,比如Oceanstore[10]和PAST[11],构建在这些路由机制之上。Oceanstore提供了一个全局的,事务的,持久性的存储服务,支持对大量复制数据的顺序更新。为了能够在并发更新时避免大面积锁导致的问题,它使用了基于冲突解决的数据更新模型。引入冲突解决方案[12]是为了减少事务失败的次数。Oceanstore处理冲突的方式是,对一系列更新操作,确定一个最终的顺序,然后按照这个顺序来原子的执行这些更新。它是针对数据会被复制到不可信任的基础设施上这种情况建立的。作为对比,PAST提供了一个构建在Pastry之上的简单抽象层,主要用于持久性和不可变对象。它假设应用程序可以在此基础之上构建自己所需的存储语义(比如不可变文件)。
3.2 分布式文件系统和数据库
数据分布的性能,可用性和持久性在文件系统和数据库系统社区被广泛的研究过。相比与P2P存储系统的扁平命名空间,分布式文件系统能够支持层次命名空间。像Ficus[13]和Coda[14]这样的系统给文件做副本,以一致性为代价提供高可用性。更新冲突通常由指定的冲突解决方案来处理。Farsite[15]是一个没有使用任何中心服务器的分布式文件系统,类似于NFS。Farsite通过使用副本来达到高可用性和可扩展性。Google文件系统是另外一个分布式文件系统,主要用于存储Google内部应用的状态。GFS使用了一个简洁的设计: 使用一个master服务器来存储所有的metadata,同时文件数据被拆分为多个块(chunk),存储在chunkserver中。Bayou是一个分布式的关系型数据库,可以容忍网络断开的情况,提供最终一致性[16]。
以上系统中,Bayou,Coda和Ficus允许网络断开下的操作,对网络分裂和停运具有弹性。这些系统在冲突解决方案上各不相同。比如,Coda和Ficus采用了系统级的解决方法,而Bayou则允许应用程序基本的解决方法。然而以上所有系统,都提供最终一致性。和这些系统相似,Dynamo也允许在网络分裂的情况下执行读写操作,同事说使用多种机制来解决冲突。分布式块存储系统,比如FAB[17],将大尺寸对象拆分为多个小的块,单独存储每个块,并保证高可用。相比于这些系统,key-value式存储可能更合适,原因如下: (a) 主要用于存储相对比较小的对象(小于1M),(b)对应用程序来说,key-value式存储更容易配置。Antiquity是一个广域的分布式存储系统,能够应对多个服务器故障的情形[18]。它使用安全日志来保证数据的完整性,这些日志被持久化记录到多个副本,同时使用拜占庭容错协议来保证数据的一致性。和Antiquity不同,Dynamo不用太关注数据完整性和安全性,因为它主要用于一个信任的环境。Bigtable是一个用于管理结构化数据的分布式数据库。它维护了一个稀疏的,多维的有序map,允许应用程序使用多个属性来访问数据[19]。和Bigtable相比,Dynamo的目标应用程序只需要key-value式的访问数据,首要关注高可用性,保证即使在网络断开和服务器故障情况下也不会拒绝更新请求。
传统的复制型关系数据库主要关注副本数据的强一致性问题。虽然强一致性能让应用程序的编程模型非常简单,但是这样的系统在扩展性和可用性方面是很受限制的[20]。这些系统无法处理网络分裂的情形,因为他们通常提供强一致性保证。
3.3 讨论
由于目标需求不同,Dynamo和上述的去中心化存储系统都不相同。首先,Dynamo的目标应用程序需要一个"永远可写"的数据存储,即使在故障和并发写的情况下,也不会拒绝更新请求。第二,如上面提到的,Dynano被假设构建在一个单独的环境中,其中每个节点都是可信任的。第三,使用Dynamo的应用程序并不需要层次命名空间(类似于文件系统)和数据结构schema(关系型数据库)。第四,Dynamo的目标应用程序都与延迟敏感,需要至少99.9%的请求能够在几百ms内完成。为了满足延迟的需求,我们必须避免在多个节点间进行请求路由(这是一些基于hash的分布式系统典型做法,如Chord和Pastry)。这是因为多次路由增加了响应次数,从而提高了整体响应耗时。Dynamo可以认为是一个零跳(zero-hop)的分布式hash表(DHT),其中每个节点都在本地维护了足够的路由信息,从而使得请求可以一次就转发到合适的节点上。
4. 系统架构
一个能够在生产环境中工作的存储系统的架构是比较复杂的。除了数据持久化组件之外,系统还需要在复制均衡,成员管理,故障探测,副本同步,过载处理,状态迁移,并发,任务调度,请求编组,请求路由,系统监控和告警,配置管理这些方面做到可扩展和健壮。讨论所有这些解决方案的细节是不可能的,因此本文将主要关注Dynamo中使用的核心分布式系统技术:分片,复制,版本,成员管理,故障处理,扩展。
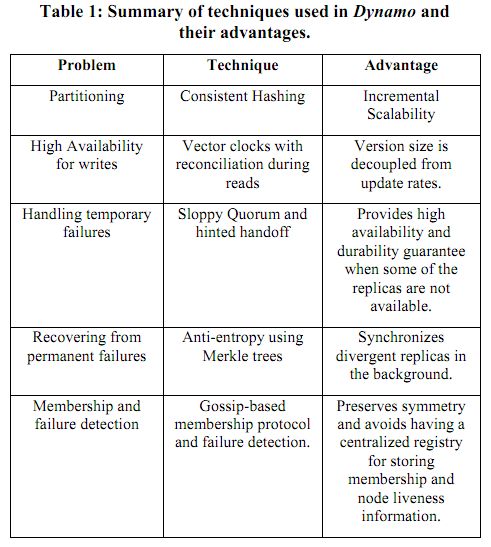
表 1展示了Dynamo使用的技术以及它们各自的优势
4.1 系统接口
Dynamo使用一个简单的接口来存储对象,这些对象都通过一个key关联起来;它暴露了两种操作:get()和put()。get(key)操作会定位key所关联的对象副本所在位置,然后返回这个对象,或者返回一个对象列表,其中包括冲突的版本以及上下文。put(key, context, object)操作通过key来决定应该把object放在哪些位置,然后将副本写入硬盘。上下文包括了对调用方不透明的对象元数据,以及一些其他信息,比如对象的版本。上下文信息和object存储在一起,这样能够让系统在处理put请求时验证上下文的有效性。
Dynamo将调用方提供的key和object看作是不透明的字节数组。它对key进行MD5哈希运算,得到一个128位的标识符,通过这个标识符来决定哪些节点应该对这个key负责。
4.2 分片算法
Dynamo的核心需求之一是它必须能够支持增量扩展。这需要一个机制能够动态的将数据分布到系统中的节点上。Dynamo的分片方案依赖于一致性哈希将数据分布到多个存储节点上。在一致性哈希[21]中,哈希函数的输出范围被当作一个固定的圆形空间,或者一个环(hash的最大值和最小值连接)。系统中的每个节点都被随机分配到这个环上的某个位置。每条数据都按照以下方式被分配到一个节点:先计算这个数据key的hash值,将hash值映射到环上,然后在环上顺时针寻找第一个节点。这样每个节点都只需要对上一个节点到当前节点之间的区间负责。一致性hash的好处是,一个节点的进入和退出都只影响它邻近的节点,而其他的节点不会收到影响。
基本的一致性哈希算法带来了一些问题。首先,节点被随机的分片到环上,这会导致数据和压力分布不均匀。第二,基本算法忽视了各个节点间的不同。为了解决这些问题,Dynamo使用了一致性哈希的一个变体(和附录[22]中的相似);每个节点映射到哈希环上的多个节点,而不是一个节点上。为此,Dynamo使用了"虚拟节点"的概念。一个虚拟节点看上去就像系统中的一个节点,但是每个节点可以对应多个虚拟节点。当一个节点添加到系统中时,它被分配到哈希环上的多个位置(后面称作tokens)。第六章会讨论Dynamo中微调分片方案的过程。
使用虚拟节点有以下好处:
- 如果一个节点不可用了(故障或者路由问题),这个节点的压力会平均的分配到其他可用的节点上
- 当故障节点恢复可用,或者一个新节点加入到系统中,其他各个节点会分配大致相同的压力给新节点
- 一个节点负责的虚拟节点个数可以根据节点的能力,即基础设施状态,来确定。
4.3 复制
为了达到高可用性和持久性,Dynamo将数据复制到多个服务器上。每条数据被复制到N个服务器上,其中N由配置项"per-instance"指定。每个key,k,被分配给协调节点(下一节说明)。协调者负责落到它的范围中的数据的复制。协调者除了将落到自己的范围中的数据存储在本地之外,还要将这些数据存储在后续N-1个节点上,也就是哈希环上顺时针方向后续N-1个节点。这导致系统中的每个节点都需要负责从它自己到后续第N个节点的范围。在图2中,节点B除了k存储在本地之外,还将k复制到节点C和D。节点D会存储落到(A,B], (B,C], (C,D]范围内的key。

用于存储某个指定key的节点列表被称作首选列表(preference list)。在第4.8节中将会说明,系统被设计为,每个节点都可以知道任意key的首选列表包括哪些节点。考虑到节点故障,首选列表中的节点数会大于N。需要注意到,由于使用了虚拟节点,对某个指定key,前N个后续节点可能被少于N个不同的物理节点拥有(一个节点可能对应这个N个节点中的多个)。为了解决这个问题,在构建一个key的首选列表时,可能会跳过一些节点,导致首选列表是一个不连续的列表,从而保证列表中只包含不同的物理节点。
4.4 数据版本
Dynamo提供最终一致性,允许数据更新异步的传播到各个副本上。put操作可能在更新同步到所有副本之前就返回了,这会导致后续的get()操作得不到最新的数据。如果没有故障,所有副本的更新有确定的时间范围。然而,在故障的情形下(比如服务器宕机或者网络断开),即使在更长的时间内,更新也可能没有到达所有的副本。
Amazon平台上有一类应用可以容忍这种不一致,并且能够在这种情况下工作。比如,购物车服务需要保证"添加到购物车"操作永远不会被拒绝或者遗忘。如果购物车最新状态是不可用的,用户就将在老版本的购物车上进行更改,这些更改仍然是有意义并且应该被保留的。但同时,购物车的这个状态不应该确定当前不可用的状态,因为不可用的状态可能包含一些应该保留的更改。注意到,"添加到购物车"和"从购物车删除"操作都被转化为Dynamo的put请求。当用户向购物车中添加商品,同时购物车最新状态是不可用的,那么这些商品就会被添加到一个老的版本中,状态的分歧在之后再进行解决。
为了保证这一点,Dynamo将每次修改都看作是数据的一个新的,不可更改的版本。它允许一个对象的多个版本同时出现在系统中。大部分情况下,新版本会合并到旧版本之外,并且系统能够判断哪个版本是权威版本。然而,版本分叉是可能出现的,当遇到故障或者并发更新时,就可能导致对象的多个冲突版本。这种情况下,系统无法解决同一对象的多个版本冲突,必须由客户端来解决这些冲突,将多个版本重新合并回一个版本。使用这种机制,"添加到购物车"操作永远不会丢失,但是删除的商品可能会再次出现。
一些故障情形可能会导致系统中一个数据出现多于两个的不同版本,理解这一点非常重要。在节点故障,网络断开时进行更新,可能会导致一个对象出现多个版本,系统需要在后续解决这些冲突。这导致我们需要设计应用程序的时候,必须让它能够应对一份数据可能出现多个版本的情况(从而不会丢失任何更新)。
Dynamo使用矢量钟(vector clocks)[23]来确定同一数据的多个版本之间的因果关系。矢量钟是一个(节点,计数器)的列表。一个矢量钟和任意对象的每个版本关联着。通过检查矢量钟,可以决定一个对象的两个版本是并行关系还是有一个先后顺序。如果第一个对象矢量钟上的计数器值小于等于第二个对象矢量钟上的所有计数器,那么第一个对象就是第二个对象的祖先,可以被丢掉。否则的话,这两个对象版本就被认为是冲突的,需求协调解决。
在Dynamo中,如果客户端想要更新一个对象,它必须指定它要更新的版本。通过传递上下文来指定,上下文是在之前的读操作中获取的,其中包括了一个矢量钟。在处理读请求时,如果出现一个对象有多个版本,而Dynamo无法决定哪个版本有效时,它会将对象所有版本连同上下文信息都返回给调用方。如果更新请求中带有上下文,说明客户端刚刚解决了冲突,对象所有的版本分支将会合并为一个。

为了说明矢量种的机制,考虑图3中的例子。客户端写入一个新的对象,节点Sx处理这个写请求,并用自增序列号来构建这个对象的矢量钟。现在系统中有一个对象D1,它的矢量钟是[(Sx,1)]。接着客户端更新了这个对象,假设仍然是节点Sx处理这个请求。现在系统中有了对象D2以及它的矢量钟[(Sx,2)]。D2来自D1,因此它覆盖了D1,然而可能有一些D1的副本还没有看到D2(译注:这句话本身没有错,但是对比图3,会造成一些混淆)。假设此时客户端又发起一次更新请求,另一个节点Sy处理了这个请求。此时系统中有了数据D3,它的矢量钟是[(Sx,2), (Sy,1)]。
接下来,假设客户端读取到了D2然后要更新它,另一个节点Sz处理了这个写请求。此时系统中有了D4,它的版本矢量钟是[(Sx,2), (Sz,1)]。如果一个节点能够知道D1和D2,那么如果他收到了D4以及它的矢量钟,那么这个节点可以决定D1和D2都会被新的数据覆盖,因此可以回收了。如果一个节点知道D3,然后又收到了D4,那么这个节点将无法判断这两个数据的关系。换句话说,D3和D4中包含了对方不了解的更新。这两个版本的数据都必须保留下来,并在处理读请求时返回给客户端,由客户端来解决冲突。
现在假设某个客户端读到了D3和D4(上下文会反映出两个值都被读到了)。读到的上下文是D3和D4的矢量钟的结合,也就是[(Sx,2), (Sy,1), (Sz,1)]。如果客户端处理了冲突,节点Sx处理了写操作,Sx会更新它的矢量钟的序号。新的数据D5的矢量钟如下:[(Sx,3), (Sy,1), (Sz,1)]。
矢量钟可能出现的一个问题是,如果很多个服务器处理了对同一个对象的更新操作,那么矢量钟的长度可能会持续增大。在实际中,这个问题不太可能出现,因为写操作基本都是被首选列表的前N个节点处理了。在网络断开和多个服务器故障的情况下,写操作可能不会被首选列表中的节点处理,这会导致矢量钟的长度增大。为了应对这个问题,Dynamo使用了如下的矢量钟截断方案:对每个(节点,计数)对,Dynamo同时存储了一个时间戳,记录了最近一次当前节点更新数据的时间。当矢量钟的(节点,计数)根数到达阈值(比如10个)的时候,最旧的数据将会被删除。很明显这种截断方式会导致解决冲突时效率低下,因为无法得到准确的后续信息。然而在生产环境中没有出现过问题,因此这个问题还没有彻底研究。
4.5 get()和put()的执行
Dynamo中的任意节点都可以接收客户对任意key的get和put操作请求。为了简洁起见,本节将会描述在没有故障的环境中这些操作时如何处理的,后续章节我们会讲解在故障的时候读写操作是如何执行的。
读写请求都是通过HTTP协议,使用Amazon特定基础设施的请求处理框架来调用的。客户端有两个选择节点的策略可选:(1)使用另一个通用的负责均衡器来路由请求,这将根据负载信息选择一个节点,(2)使用一个了解分片信息的客户端程序库,这将直接将请求路由到合适的协调节点。第一个策略的好处是客户端不需要链接任何Dynamo特定的代码到应用程序中,第二个策略的好处是可以跳过一次潜在的转发,从而延迟更低。
处理读写操作的节点叫做协调者(coordinator)。典型的,这个节点是首选列表前N个中的第一个。如果请求是通过一个负载均衡器发送的,那么请求可能会落到哈希环的一个随机节点上。这种情形下,如果这个节点不是首选列表前N个中的一个,它不会处理这个请求,而是把请求转发给首选列表前N个中的第一个节点。
读写操作只会涉及到首选列表中前N个健康的节点,会跳过那些故障或者无法访问的节点。如果所有的节点都是健康的,key所对应的首选列表中前N个节点都会被访问到。如果有节点故障或者网络断开问题,首选列表中靠后的节点也会被访问到。
为了维持副本之间的一致性,Dynamo使用了一个类似于仲裁系统的一致性协议。这个协议有两个关键配置值:R和W。R是指一次成功的读操作中参与节点的最少个数。W是指一次成功的写操作中参与节点的最少个数。设置R和W以满足R + W > n,就产生了一个仲裁系统。在这个模型中,一次读写操作的延迟取决于R(W)中最慢的那个副本。由于这个原因,R和W一般被配置为小于N,以提供更好的延迟。
当收到对一个key的put操作时,协调节点产生新版本数据的矢量钟并在本地记录这个版本。然后协调节点将新版本信息(以及最新的矢量钟)发送给前N个可以连接到的节点。如果有W-1或更多个节点响应了,那么这个写操作就被认为是成功的。
类似的,对于get请求,协调者会请求首选列表中的前N个节点以获取这个key的所有版本,然后等待R个节点响应,之后才能返回结果给客户端。如果协调者最后聚集了数据的多个版本,它会返回它认为没有因果关系的多个版本。这些不同的版本会被客户端协调解决冲突,然后协调后的版本会代替当前版本,并写回到节点中。
4.6 处理故障: 暗示移交((Hinted Handoff)
如果Dynamo使用传统的仲裁方案,那么当出现服务器故障或网络断开的情况时,它就是不可用的 ,并且在最简单的故障情形下也会降低持久性。为了补救这一点,Dynamo没有使用严格的仲裁协议,而是使用了"马虎仲裁(sloppy quorum)"。所有的读写操作都在首选列表的前N个健康节点上进行,有可能不是在哈希环上顺时针遍历时遇到的前N个节点。
考虑图2中的例子,Dynamo被配置为N=3。这个例子中,如果在写操作的处理中,节点A暂时的故障或无法访问了,那么本来应该在节点A上的数据副本会被发送到节点D上。这样做是为了满足可用性和持久性的保证。发送到节点D上的数据副本的元信息中会有一个暗示(hint),说明这个数据副本本来应该是在那个节点上(此处是节点A)。收到暗示副本的节点会把它们存储在一个隔离的本地数据库中,并且周期性的扫描,当检测到节点A恢复了,节点D就会尝试把这个数据副本发送给节点A。一旦发送成功了,节点D就会从本地存储中删除这个副本,同时并不会减少系统中副本的数量。
使用暗示移交,Dynamo可以保证读写操作都不会因为暂时的故障或网络问题而失败。对可用性要求比较高的应用可以将W设置为1,这样可以保证,在处理写请求时只要系统中有一个节点将数据写入到本地存储,写请求就能成功返回。因此,只有在系统中所有节点都不可用时,写请求才会被拒绝。然而在实际中,大部分Amzon应用在生产环境中会设置一个较高的W,为了达到需要的持久性。第6章会更详细地讨论N,R和W的设置。
一个高可用存储系统具有应对整个数据中心故障的能力是非常重要的。由于断电,冷却系统故障,网络错误以及自然灾害,数据中心可能出现故障。Dynamo被配置为每个对象都在多个数据中心存储副本。本质上说,一个key的首选列表被设计为,其中的存储节点分布在不同的数据中心。这些数据中心通过高速网络进行连接。这种在多数据中心分布副本的方案使得我们能够应对单个数据中的故障,保证数据服务持续运行。
4.7 处理永久故障:副本同步
在系统成员变化很少,节点只会短租故障的情况下,暗示移交能够工作的很好。但是也会有这样的场景,暗示副本在它们写回到原来的节点之前就不可用了。为了处理这种情况以及其他对持久性的威胁,Dynamo实现了一个逆熵(anti-entropy,副本同步)协议来保持副本之间的同步。
为了快速检测出副本间的不一致,同时最小化传输的数据量,Dynamo使用Merkle树[24]。Merkle树是一个哈希树,它的叶子节点是一些单独的key的哈希值,父节点是它自己子节点的哈希值。Merkle树的一个主要好处是,树中的每一条分支都可以单独的检测,而不需要把整棵树的所有数据都下载下来。此外,在检测到副本之间不一致时,减少需要传输的数据量这一点上,Merkle树也有帮助。比如,如果两个Merkle树的根节点值是一样的,那么所有的叶子节点的值也是相同的。如果不是,那就说明有些副本的值不一样。这种情况下,节点之间可以交换根节点的子节点的哈希值进行比较,如此执行直到叶子节点,此时会发现某两个key是"不同步"的。Merkle树最小化了为同步而需要传输的数据量,同时减少了在整个逆熵过程中读取磁盘的次数。
Dynamo按照如下方式在逆熵中使用Merkle树:每个节点维护一个单独的Merkle树,这棵树中包括了当前节点处理的key范围中所有的key。这可以让节点间进行比较从而了解范围内的key是否是最新的。这种方案中,两个节点根据他们共同处理的key范围来交换相应的Merkle树根节点。接着使用上面描述的遍历树的方案来决定它们是否有不同的地方,然后进行相应的同步处理。这个方案的劣势在于,在节点进入和离开系统时,很多key范围会变化,因此Merkle树需要重新计算。第6.2节中描述了一种更精巧的分片方案,解决了这个问题。
4.8 成员关系和故障检测
4.8.1 环成员关系
在Amazon的环境中,节点停服往往都是暂时的,但是可能会持续一小会。一个节点的停服很少意味着永久退出系统,因此不会导致重新分布数据或者修复不可访问的副本。类似的,人为失误可能导致非预期的加入新节点到系统中。由于这些原因,使用一种显式的机制来初始化新节点和删除节点被认为是合适的。管理员使用一个命令行工具或者浏览器来连接到Dynamo并发起一个成员关系的变更,从哈希环中删除或者添加一个节点。处理变更请求的节点将成员关系的变更以及发生的时间写入到持久化存储中。成员关系的变更形成了一个历史记录,因为节点可以多次的删除和添加到系统中。一个基于gossip的协议在节点之间传播变更信息,维持成员关系的最终一致性。
每个节点每秒钟和另外一个随机选择的节点进行通信,两个节点交换他们的成员关系变更历史。
一个节点初次启动时,它会选择虚拟节点并将虚拟节点映射到哈希环上各自相应的范围。这个映射关系会持久化到硬盘上,并且一开始的时候只包括当前节点的映射信息。系统中其他节点的映射信息在后续的同步变更历史时会逐步完善。因此,分片和位置信息也是通过基于gossip的协议进行传播,系统中每个存储节点都知道其他所有节点的虚拟节点映射关系。这就使得每个节点都可以将一个key的读写请求直接转发到正确的节点上。
4.8.2 外部发现
上述机制可能导致短暂的逻辑上的哈希环分裂。比如,管理员将节点A加入到哈希环中,然后又将节点B加入到哈希环中。此时,节点A和节点B都认为自己是在系统中的,但是它们都不能立即知道彼此的存在。为了防止这个问题,一部分Dynamo节点会扮演种子的角色。种子节点通过外部机制发现,并且所有节点都知道它们。因为所有的节点最终都会和种子节点交换成员关系变更历史,逻辑分裂不太可能发生。可以通过配置文件或者配置服务来设置种子。典型的,种子节点是哈希环中的全功能节点。
4.8.3 故障检测
Dynamo的故障检测是为了避免尝试和不可访问的节点通信,在读写操作,传输分片,暗示副本的过程中。一个纯粹的本例故障检测概念就完全足够了:节点A可能认为节点B是故障的,在节点B没有响应节点A的消息的情况下(即使节点B响应了节点C的消息)。在客户端请求以一个稳定的速率发送到Dynamo的情况下,Dynamo内部节点会持续的互相通信,如果节点B没有响应节点A的消息,A会认为B已经故障;节点A就会使用一个替代的节点来处理本应该由节点B处理的请求;同时节点A会周期性的尝试与B通信,检测它是否已经恢复。如果没有客户端请求来产生节点间内部通信,那么节点也就不需要了解哪个节点是否可以访问了。
去中心化的故障检测协议使用一个简单的gossip风格协议来使系统中的节点了解其他节点的进入和退出。关于去中心化故障检测的更多细节,以及参数如何影响它的准确性,可以参考[25]。早期Dynamo的设计使用去中心化的故障检测器来维护一个故障状态的全局视图。后来发现使用显示的节点进入和退出方法可以不需要使用全局故障视图,因为通过显式调用方法的节点的进入和退出,其他节点会被通知。而暂时的节点故障也会在它们不再和其他节点通信时被检测到。
4.9 添加/删除 存储节点
当一个新节点(假设叫X)添加到系统中,它会被分配一些位置,这些位置随机的分布在哈希环上。对每个分配给X节点的key范围,有一些其他节点(小于等于N个)负责这些范围里面的key。由于这些key范围被分配给了节点X,其他节点不用再存储这些key,它们将把这些key传输给节点X。我们考虑一个简单的初始化场景,如图2所示,假设节点X被添加到节点A和节点B之间。当节点X添加后,它将负责(F,G], (G,A] (A,X]范围内的有序key序列。作为一个后果,节点B,节点C和节点D不在存储这些key范围。因此,节点B,C和D会将这些数据传输给节点X并确认传输成功。当一个节点从系统中退出时,相应的key会按照相反的过程进行重新分配。
操作经验显示这种方案会使得key在存储节点上分布不均匀,这对保证低延迟以及快速启动是非常重要的一个方面。最终,通过在源和目的节点之间增加一个确认过程,保证了目的节点不会收到一个key范围内的重复传输数据。
5. 实现
Dynamo中每个存储节点都有三个主要的组件:请求协调,成员关系和故障检测,以及本地持久化存储引擎。所有这些组件都是用Java实现。
Dynamo的本地存储组件可以使用不同的存储引擎插件。使用的存储引擎包括Berkeley数据库(BDB)事务数据存储,BDB Java版本,MySQL,以及一个带有持久化备份存储的内存缓存。设计一个可插件化存储组件的主要目的是让应用程序可以根据各自的访问模型来选取最合适的存储引擎。比如,BDB可以处理典型的几十K大小的对象,而MySQL则可以处理更大的对象。应用程序根据他们的对象大小来选取Dynamo的本地存储引擎。大部分生产环境的Dynamo实例都使用BDB事务数据存储。
请求协调组件构建在一个事件驱动的模型之上,和SEDA架构相似,其中消息处理过程被拆分为多个阶段。所有的通信都使用Java NIO管道来实现。协调者作为客户端的代表执行读和写请求,从一个或多个节点收集数据或者将数据写入到一个或多个节点。每个客户端请求都会导致接收请求节点创建一个状态机。状态机包括了如下过程的所有逻辑:确认负责这个key的节点,发送请求,等待回复,可能的重试,处理返回,打包结果返给客户端。每个状态机实例处理一个客户请求。举例来说,一个读操作实现了如下状态机:(i)发送请求给相应节点, (ii)等待需要的最小数量的响应, (iii)如果在指定时间内只有很少响应,请求记为失败, (iv)否则收集所有的数据版本并决定哪些需要返回的数据以及(v)如果开启了版本功能,进行冲突协调并生产一个写操作的上下文,其中包括了涵盖所有版本的矢量钟。为保持简洁性,略去了故障处理以及重试状态。
在读请求的响应返回给客户端后,状态机会等待一小段时间,用来接收未完成的响应。如果此时收到了旧版本数据的响应,协调者会将这些节点的数据更新为最新版本。这个过程被称为读修复,因为它在一个机会时间内修复了错过最近更新的副本,同时也减低了逆熵协议的处理压力。
如之前提到的,写请求由首选列表前N个节点中的某个节点来协调。虽然很想总是使用前N个节点的第一个节点来协调写请求从而将所有写请求在同一位置序列化,但是这种方案会导致数据分布的不均匀,从而导致达不到SLA要求。因为请求压力没有均匀分布到所有的节点上。为了解决这个问题,首选列表的前N个节点中任意一个都可以协调写请求。具体来说,由于写请求往往紧跟在一个读请求之后,写请求的协调者可以选为之前响应读请求最快的节点,这个请求记录在写请求的上下文信息中。这个优化使我们能够选择之前处理读请求的节点,从而增加了"读取你所写"一致性的机会。它同时也降低了请求处理性能的波动,从而增加了99.9%水平的性能表现。
6. 经验 & 教训
多个服务使用Dynamo,并使用不同的配置。这些实例在版本协调逻辑,读写仲裁特性方面有所不同。以下是Dynamo使用的主要模式:
- 业务逻辑指定冲突协调方案:这是Dyanmo较受欢迎的一种用法。每个数据对象都在多个节点上存储有副本。当遇到不同版本的情形,客户端应用程序进行他们自己的冲突协调逻辑。前面讨论的购物车服务是一个这种类型的一个例子。它的业务逻辑通过合并购物车的不同版本来解决冲突。
- 基于时间戳的冲突协调方案:这个机制和上一个相比,只在协调机制上有所不同。当遇到不同版本时,Dynamo进行简单的基于时间戳的协调,即"最后一个写有效";比如,带有最大物理时间戳的对象被选择为正确的版本。维护用户会话信息的服务是使用这种机制的一个好例子。
- 高性能读引擎:Dynamo旨在构建一个"总是可写"的数据存储,然而一小部分服务通过调整它的仲裁特性,使它成为一个高性能读引擎。典型的,这些服务有很高的读请求速率,同时只有很少的更新请求。在这个配置下,R一般被设置为1,W设置为N。对于这些服务,Dynamo提供了分布数据的能力,以及增量扩容的能力。这些实例中的一部分被当作一致性cache来使用,其中数据存储在更加重型的后端存储中。维护商品类目以及促销商品的服务很合适这种机制。
Dynamo的最大优势在于,它的客户应用程序可以通过调整N,R,W的值来到他们所需要的性能,可用性,持久性水平。例如,N的值决定了每个对象的持久性。Dynamo用户使用的N值典型为3。
W和R的值影响着对象的可用性,持久性以及一致性。例如,如果W设置为1,那么只要有一个节点成功处理了写操作,那么系统就不会拒绝写请求。然而,W和R设置的比较低,会增加不一致的风险,因为即使写请求没有被大部分副本处理,也会认为是成功并返回给客户。这种设置也给持久性带来了风险窗口,因为一个写请求在只有小部分节点完成持久化的情况下就返回成功给客户端了。
传统的观点认为持久性和可用性要同时存在。然而,这并不是必需的。例如,可以通过增加W的值来降低持久化的风险。这可能会增加拒绝请求的概率,因为需要更多在线的存储节点来处理写请求。
一些服务使用的最通用的(N,R,W)配置是(3,2,2)。选择这几个值是为了达到需要的性能,持久性,一致性水平,以及可用性SLA。
本章所描述的测量都是在一个使用(3,2,2)配置的系统中进行的,包括几百个相同硬件配置的节点。如前面所提到的,Dynamo的每个实例都包含分布在不同数据中心的节点。这些数据中心都通过高速网络连接。为了产出一个成功的读请求的响应,R个节点需要返回响应给协调者。很明显的,数据中心之间的网络延迟会影响到响应时间,因此需要刻意选择节点以及他们在哪个数据中心,来达到应用程序的目标SLA。
6.1 平衡性能和持久性
虽然Dynamo的首要设计目标是建一个高可用的数据存储系统,性能也是Amazon平台一个同样重要的标准。如前面提到的,为了达到一致的用户体验,Amazon的服务将性能水平设置为比较高的百分比(比如99.9%或者99.99%)。一个典型的使用Dynamo的服务的SLA为99.9%的读写请求在300ms以内完成。
由于Dynamo是运行在普通的廉价硬件上,I/O能力相比高端企业服务器要弱很多,因此,要提供读写请求的高性能是一个非凡的任务。在读写请求中多个节点的参与更使得这个任务具有挑战性,因为这些操作的性能被R或W个副本里面最慢的一个的性能所限制。图4展示了Dynamo在30天内读写请求的平均延迟以及99.9%分位的延迟。可以看到,延迟的分布表现出明显的昼夜周期性,由于请求速率的昼夜模式(在白天和夜晚请求量有明显不同)。此外,写请求的延迟明显的比读请求高,因为写请求总是要访问磁盘。99.9%分位的延迟都在200ms左右,并且比平均水平要高一点。这是因为99.9%分位水平延迟收到一些诸如请求压力变化,对象大小,以及本地模式的影响。
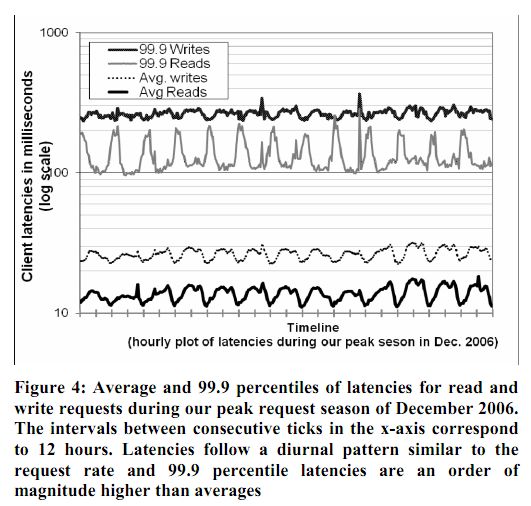
对于大多数服务来说,这个水平的性能是可以接收的,然而有一小部分面向客户的服务需要更高水平的性能。对这些服务,Dynamo提供了在牺牲持久性保证以换取性能的能力。作为优化,每个存储节点都在内存中维护一个对象的缓存。写操作也写入到缓存中然后由一个写线程周期性的写入到磁盘中。在这种方案中,读操作首选检查请求的key是否在缓存中,如果在,那么就直接从缓存中读取而不是从存储引擎中读取。
这个优化的结果是,高峰期时99.9%分位的延迟降低了5倍,即使只使用了一个用于几千个对象的很小的缓存(参见图5)。此外,如如图中所示,写缓存机制使高分位的延迟变得比较平滑。很明显的,这个方案牺牲了持久性来换取高性能。使用这个方案,服务的崩溃会导致在缓存中排队的写操作丢失。为了减少持久性风险,写操作重新优化为,协调者会选择N个节点中的一个来完成"持久化写"操作。由于协调者只需要等待W个响应,写操作的性能不会被单个副本的持久化写邪能所影响到。

6.2 确保压力均匀分布
Dynamo使用一致性hash来将key空间分布到副本上,保证压力均匀分布。假设key不是高度倾斜的,key均匀分布能够帮助我们达到压力均匀分布的目的。具体来说,Dynamo在设计时假设,即使访问请求分布有严重倾斜,也会有足够多的key在分布尾端,因此处理大多数key的压力能够通过分片均匀的传播到节点上(????)。本节讨论压力失调以及不同分片策略对压力分布的影响。
为了研究压力失调和请求压力的关系,测量了每个节点在24小时内收到的请求数据,分为30分钟一个周期。在给定的时间窗口内,如果一个节点的请求压力和平均水平相差在15%以内,那么认为这个节点此时"在平衡状态中",否则认为节点"不在平衡状态"。图6显示了这段时间内"不在平衡状态"的比例。作为参考,这段时间内整个系统收到的请求压力也绘制在图中。可以看到,失衡比例随着压力的增加而减小。比如,在低负载情况下失衡比例达到20%,而在高负载时失衡比例接近10%。可以很直观的解释这个现象,在高负载情况下,有大量的对多数key的请求,由于key的均匀分布,压力也被均匀的分布了。然而在低负载时(请求压力是高峰期的1/8),更少的多数key被访问,导致了高比例的失衡状态。

本节讨论Dynamo的分片方案是如何随着时间以及对压力分布的影响演进的。
策略1`: 每个节点T个随机的token以及按token值来分片:这是最早在生产环境中使用的分片策略(4.2节中有描述)。在这个方案中,每个节点被分配T个token(从hash空间中均匀的随机选取)。所有节点的token根据他们在hash环中的值排好序。每两个连续的token定义了一个范围,最后一个token和第一个token组成了一个包括hash空间内最大值到最小值的范围。因为token是随机选择的,得到的范围大小都是各不相同的。随着节点的加入和退出,token都在变化,因而范围也都在变化。需要注意到,在每个节点上维护成员关系所需的存储空间是随机节点的个数而线性增加的。
使用这种方案时,遇到了以下问题。首选,当一个新节点加入到系统中,它需要从其他节点中"偷取"key范围。然而,那些把key范围转交给新节点的节点必须要扫描本地持久化存储以找到相应的数据。注意到在生产节点上进行这样的扫描操作是非常trick的,因为扫描是资源密集型操作,并且需要在后台完成,以及不影响用户体验。这导致运行初始化的任务只有很低的优先级,然而,这个机制导致了初始化进行的非常缓慢。在繁忙的购物季,节点在一天内处理上百万个请求,初始化几乎需要一整天的时间来完成。第二,当一个节点进入或退出系统,许多节点的key范围都发生变化,Merkle树需要重新计算,这在生产环境中是一个比较麻烦的操作。最后, 由于key访问的随机性,很难对整个key空间做一个快照,这导致归档很困难。这种方案中,归档整个key空间需要单独从每个节点中获取数据,是非常低效的方式。
这种策略的根本问题在于数据的分片和数据的分区布局交织在一起。比如,在某些情形下,期望通过增加节点来应对请求压力的增长。然而,这种场景下,不可能添加节点而又不影响数据分布。理想情况中,可以使用单独的方案来做分片和分区布局。为了解决这个问题,演化出了以下策略:
策略2: 每个节点T个随机token和相等大小的分区:这种策略中,hash空间被等分为Q个范围,每个节点被分配T个随机token。Q一般被设置为Q >> N and Q >> S*T,其中S是系统中节点个数。这种策略中,token只用于构建一个将hash空间中的值映射到节点上的有序list的map,而不用于决定分片。图7展示了N为3时这种策略的例子,其中,从包含k1的分片出发,会遇到节点A,B,C。这种策略的主要好处是: (i)解耦了分片和分区布局,(ii)使运行时更改分区布局变得可能。
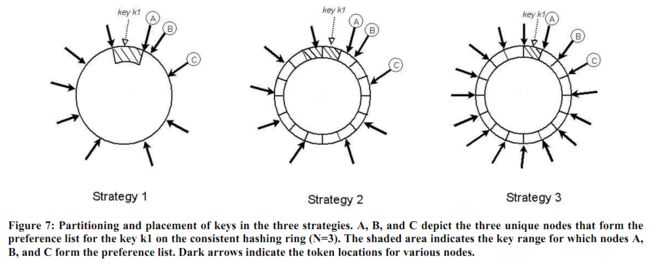
策略3: 每个节点Q/S个token, 相等大小的分区:和策略2相似,这种策略将hash空间氛围Q个大小相等的分区,分区的位置和分区方案是解耦的。此外,每个节点都被分配了Q/S个token,其中S是系统节点个数。当一个节点退出系统时,它所负责的token被随机的分配给剩余的节点,这样这些属性都得意保留。类似的,当一个节点加入到系统中时,它以一种保留这些属性的方式从其他节点"偷取"token。
在一个S=30和N=3的系统上评估了这三种策略的效率。然而,以一个公平的方式来评估这些不同的策略是比较困难的,因为他们各自使用不同的配置来调整效率。比如,策略1的压力分布属性取决于token的个数(即T),而策略3则取决于分片的个数(即Q)。一个公平的比较方法是评估在使用相同存储空间来维护成员关系时,系统压力的倾斜状况。比如,在策略1中每个节点需要维护哈希环中所有节点的token位置,在策略3中每个节点需求维护分配到每个节点的分区信息。
在我们的下一个实验中,通过改变相关参数(T和Q)来评估了这些策略。在节点维护的成员信息大小不同的情况下,测量了每个策略的压力均衡效率,其中压力均衡效率被定义为每个节点处理请求的平均数和最忙节点的最高峰请求处理数的比例。

图8展示了实验结果。从图中可以看到,策略3的压力均衡效率是最好的,策略2的压力均衡效率是最差的。在很短一段时间内,策略2作为将Dynamo实例从策略1迁移到策略3的一个临时过渡策略来使用。相比于策略1,策略3达到了更好的效率,并且在每个节点需要维护成员关系信息大小上降低了3个数量级。虽然存储不是一个主要问题,但是节点间会周期性的交换成员关系信息,因此保持信息尽可能紧凑也是需要的。除此之外,策略3由于以下原因部署更加简单:(i)更快的初始化/恢复:由于分片范围是固定的,他们可以存储在单独的文件中,意味着一个分片可以作为一个单元通过简单的传输文件来进行重新定位(避免了定位指定数据导致的随机访问)。这简化了初始化和恢复的过程。(ii)归档简单:周期性的对数据进行归档是大多数Amazon存储服务的强制要求。在策略3下对Dynamo存储的数据进行归档更加简单,因为分片文件可以单独获取。作为对比,策略1中token是随机选取的,归档数据需要从单个节点中获取key,这是非常低效和慢速的。策略3的劣势在于改变节点成员关系需要重新协调以保留分配所需的属性(???)。
6.3 不同版本: 何时以及多少
如前面提到的,Dyanmo被设计为牺牲一致性来换取可用性。为了理解不同故障对一致性的影响,需要多个方面的详细数据:故障时长,故障类型,组件可靠性,工作压力等。详细展示这些数据不在本文讨论范围之内。然而,本节讨论了一种摘要式的指标:在生产环境中应用程序可以看到的不同版本的数目。
在两种场景下,数据的不同版本数会增加。第一种场景是当系统面临故障,如节点故障,数据中心故障,网络断开。第二种场景是系统处理大量对同一个对象的并发更新,多个不通过节点同时处理更新操作。从可用性以及效率角度看,期望能够保证不同版本数目尽可能少。如果不能通过基于矢量钟的语法分析来解决不同版本的冲突,那么就必须将不同版本传输给业务逻辑来通过语义分析协调冲突。语义分析协调给服务带来了额外的压力,因此应该尽量减少对它的需求。
在我们下一个实验中,分析了24小时内返回给购物车服务的版本数目。在这段时间内,99.94%的请求看到一个版本;0.00057%的请求看到了2个版本;0.00047%的请求看了的三个版本;0.00009%的请求看到了4个版本。这说明不同版本很少被创建。
经验显示不同版本的数目增加不是由故障造成的,而是由于并发写的量增加而导致的。并发写的量增加一般是由繁忙的机器人(自动客户程序)触发的,很少是认为产生。这个主题不会深入讨论,因为本文的敏感性。
6.4 客户驱动或服务驱动的协调
第5章提到过,Dynamo有一个请求协调组件,它使用一个状态机来处理收到的请求。客户请求通过一个负载均衡器均匀的分布到哈希环的节点上。任意Dynamo节点都可以作为协调者处理一个读请求。另一方面,写请求则会被key的首选列表中的一个节点协调处理。存在这个限制是因为这些首选节点有一个额外职责,它们负责创建新的版本戳,偶尔还要合并那些被写请求更新的版本。注意到Dynamo的版本机制使基于物理时间戳实现的,任意节点偶可以协调一个写请求。
一个协调请求的替代方案是将状态机转移到客户节点。这种方案中,客户应用程序使用一个代码库在本地进行请求协调。客户程序周期性的随机选择一个Dynamo节点,从中下载它的Dynamo成员关系状态视图。使用这个信息,客户程序可以知道任意key的首选列表节点。读请求可以在客户端进行协调,从而避免了一次网络跳转。写请求要么被转发给key的首选列表,或者在客户端本地进行协调(如果Dynamo使用基于时间戳的版本机制)。
客户驱动的协调方案的一个重要优势是,不再需要一个负载均衡器来将客户请求均匀分布到系统中。公平的负载分布由key在存储节点上的均匀分布来隐式保证。很明显的,这种方案的效率取决于客户端的成员关系信息是否足够新。当前客户端每10秒询问一次Dynamo节点,来更新成员关系信息。基于拉的方案替代了基于推的方案,因为前者可以很好的扩展以适应大量客户端,同时只需在服务端维护很少的状态信息。然而,在最坏的情况下,客户端有可能获取到落后10s的成员关系信息。在这种情况下,如果客户端检测到自己的成员关系是陈旧的(比如,有些成功访问不到),它会立即更新成员关系信息。

表2显示了在24小时观察周期内,使用客户驱动方案相比于服务端驱动方案,得到的99.9%分位延迟的改善情况。在表中可以看到,客户驱动的协调方案在99.9%分位延迟方面降低了30ms,在平均延迟上减低了3到4ms。延迟的改善是因为客户驱动方案消除了负载均衡器,以及额外的网络跳转。同样可以看到,平均延迟显著低于99.9%分位延迟,这是因为Dynamo存储引擎的缓存以及写缓存有较高的命中率。此外,由于负载均衡器以及网络引入的额外响应时间,99.9%分位的响应时间比平均水平要高。
6.5 平衡 后台vs前台任务
每个节点除了完成常规的前台读写操作之外,还要进行不同种类的后台任务,包括副本同步和数据转移(由于暗示或者增删节点)。在早期的生产环境中,这些后台任务导致了资源争夺以及影响了正常的读写操作的性能。因此,需要确保后台任务只能在不会显著影响常规的关键操作时进行。为此,后台任务被集成到一个入场控制机制中。每个后台任务是要这个控制器来预留一部分运行时资源(例如数据库),并在所有后台任务中共享。使用一个基于监控前台任务性能的反馈机制来调整用于后台任务的资源数量。
入场控制器持续监控执行前台读写操作时资源使用状况。监视点包括磁盘操作延迟,事务超时以及锁导致的数据库访问失败,请求队列等待时间。这些信息用于检测延迟或者故障的百分比是否接近一个临界值。比如, 后台控制器会查看99.9%分位的数据库读延迟和预先设置的阈值(假设50ms)相差多远。控制器使用这些比较来评估前台任务的可用资源。接着,它会决定可用于后台任务的资源数量,从而使用这种反馈循环来现在后台活动的侵略性。注意到一个相似的后台任务管理问题在[26]中被研究过。
6.6 讨论
本章总结了从实现和维护Dynamo的过程中获取的经验。许多Amazon内部服务在过去两年使用了Dynamo,它给应用程序提供了显著的可用性水平。具体来说,应用程序99.9995%的请求都收到了成功的响应,并且目前还没有出现过数据丢失的情况。
此外,Dynamo的主要优势是提供了一个必要的手段,可以通过(N,R,W)参数来按照需求调整实例。和流行的商用存储系统不同,Dynamo将数据一致性和协调逻辑暴露给开发者。最开始的时候,很多人以为应用程序会因此变得复杂。然而,过去Amazon平台被设计为高可用,很多应用程序被设计为能处理不同故障情形以及不一致的情况。因此,将这样的应用程序移植到使用Dynamo是一个相对简单的任务。对于少数使用Dynamo的应用程序,需要在早期部署的时候选择一个合适的冲突解决机制来满足业务需求。最终Dynamo选择了一个全量成员关系模型,其中每个节点都了解所有其他节点所管理的数据。为了做到这一点,每个节点主动地和系统中其他节点交换全量路由表信息。在系统中只有几百个节点的时候,这个模型工作的很好。然而将这样的设计扩展到上万个节点是不容易的因为维护路由表的开销随着系统的规则增加而增大。通过引入分层扩展到Dynamo中可能能够克服这个限制。此外,注意到这个问题已经被O(1)的分布式哈希表系统(例如[27])解决了。
7. 总结
本文描述了Dynamo,一个高可用,可扩展的存储系统,被Amazon平台的一些核心服务用于存储状态。Dynamo提供了期望的可用性及性能水平,并且能够成功处理服务故障,数据中心故障和网络断开的情形。Dynamo是增量可扩展的,允许服务管理者根据当前请求压力来扩容或缩容。Dynamo允许服务管理者通过调整N,R,W参数来达到他们的性能,持久性以及一致性SLA要求。
过去几年Dynamo在生产环境中的使用说明了去中心化技术可以用于提供一个高可用的系统。它在最具挑战的应用环境中取得的成功显示了一个最终一致性存储系统可以构建高可用应用程序的一个部分。
鸣谢
作者在此要感谢PatHelland,他贡献了Dynamo的初步设计。我们还要感谢MarvinTheimer和RobertvanRenesse的评注。最后,我们要感谢我们的指路人,JeffMogul,在准备最终版本时,他详细的评注和输入,大大提高了本文的质量。
-
Karger,D.,Lehman, E.,Leighton, T.,Panigrahy,R., Levine,M., and Lewin,D. 1997. Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web. ↩
-
Lamport,L. Time, clocks, and the ordering of events in a distributed system. ACM Communications, 21(7), pp.558-565, 1978. ↩
-
Fox,A., Gribble, S.D., Chawathe, Y., Brewer, E. A., and Gauthier,P. 1997. Cluster-based scalable network services. In Proceedings of the Sixteenth ACM Symposium on Operating Systems Principles. ↩
-
Bernstein, P.A., and Goodman, N. An algorithm for concurrency control and recovery in replicated distributed databases. ACM Trans. on Database Sysytems. ↩
-
Gray,J.,Helland,P.,O'Neil,P., and Shasha, D. 1996. The dangers of replication and a solution. In Proceedings of the 1996 ACM SIGMOD international Conference on Management of Data. ↩
-
Terry,D.B., Theimer, M. M., Petersen, K., Demers, A.J. Managin update conflicts in Bayou, a weakly connected replicated storage system. In Proceedings of the Fifteenth ACM Symposium on Operating Systems Principles. ↩
-
http://freenetproject.org/, http://www.gnutella.org ↩
-
Rowsron,A., and Druschel, P. Pastry: Scalable, decentralized object location and routing for large-scale peer-to-peer systems. ↩
-
Stoica, I., Morris, R., Karger, D., Chord: A scalable peer-to-peer lookup service for internet applications. ↩
-
Kubiatowicz, J., Bindel, D., Chen, Y. OceanStore: an architecture for global-scale persistent storage. ↩
-
Rowstron, A., and Druschel, P.Storage management and caching in PAST, a large-scale, persistent peer-to-peer storage utility. ↩
-
Terry, D.B., THEIMER, M.M., Petersen, K. Managin update conflicts in Bayou, a weakly connected replicated storage system. ↩
-
Reiher, P., Heidemann, J., Ratner, D. Resolving file conficts in the Ficus file system. ↩
-
Satyanarayanan, M., Kistler, J.J., Siegel, E.H. Coda: A Resilient Distributed File System. ↩
-
Adya, A., Bolosky, W.J., Castro, M. Farsite: federated, available, and reliable storage for an incompletely trusted environment. ↩
-
T erry,D.B., Theimer, M. M., Petersen, K., Demers, A.J. Managin update conflicts in Bayou, a weakly connected replicated storage system. ↩
-
Saito, Y., Frolund, S., Veitch, A., Merchant, A. FAB: building distributed enterprise disk arrays from commodity components. ↩
-
Weatherspoon, H., Eaton, P., Chun, B. Antiquity: exploiting a secure log for wide-aera distributed storage. ↩
-
Bernstein, P.A., and Goodman, N. An algorithm for concurency control and recovery in relicated distributed databases. ↩
-
Gray, J., Helland, P., O'Neil, P. The dangers of replication and a solution. ↩
-
Karge, D., Lehman, E., Leighton, T., Panigraphy, R., Levine, M. Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web. ↩
-
Stoica, I., Morris, R., Karger, J.J., Siegel, E.H. Coda: A Resilient Distributed File System. ↩
-
Lamport, L. Time, clocks,and the ordering of events in a distributed system. ↩
-
Merkle, R. A digital signature based on a conventional encryption function. ↩
-
Gupta, I. Chandra, T. D. and Goldsmidt, G. S. On scalable and efficient distributed failure detectors. ↩
-
Douceur, J.R. and Bolosky, W.J. 2000. Process-based regulation of low-importance process. ↩
-
Ramasubramanian, v., AND Sirer, E.G. Beehive: O(1)
lookup performance for power-law query distribution in peer-to-peer oveylays. ↩