本次利用pyquery和multiprocessing多进程爬取了瓜子二手车1万多条数据,存入MySQL数据库,并做简单的matplotlib绘图分析。
代码如下:
import requests
from pyquery import PyQuery as pq
from multiprocessing import Pool
import re
import pymysql
db = pymysql.connect('localhost', 'root', '8802667', 'guazi', 3306)
curser = db.cursor()
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36',
'Cookie': 'uuid=c6ae8249-8eda-4649-e64f-f203aa1a6002; ganji_uuid=8209532471253319517082; lg=1; antipas=9d40v4V7G57458195967v4968; clueSourceCode=%2A%2300; sessionid=4440bacc-c05b-4fa4-9108-d0dfa1334a48; cainfo=%7B%22ca_s%22%3A%22sem_baiduss%22%2C%22ca_n%22%3A%22bdpc_sye%22%2C%22ca_i%22%3A%22-%22%2C%22ca_medium%22%3A%22-%22%2C%22ca_term%22%3A%22%25E5%25A4%25A9%25E6%25B4%25A5%25E4%25BA%258C%25E6%2589%258B%25E8%25BD%25A6%22%2C%22ca_content%22%3A%22-%22%2C%22ca_campaign%22%3A%22-%22%2C%22ca_kw%22%3A%22%25e4%25ba%258c%25e6%2589%258b%25e8%25bd%25a6%22%2C%22keyword%22%3A%22-%22%2C%22ca_keywordid%22%3A%2277188931804%22%2C%22scode%22%3A%2210103188612%22%2C%22ca_transid%22%3Anull%2C%22platform%22%3A%221%22%2C%22version%22%3A1%2C%22ca_b%22%3A%22-%22%2C%22ca_a%22%3A%22-%22%2C%22display_finance_flag%22%3A%22-%22%2C%22client_ab%22%3A%22-%22%2C%22guid%22%3A%22c6ae8249-8eda-4649-e64f-f203aa1a6002%22%2C%22sessionid%22%3A%224440bacc-c05b-4fa4-9108-d0dfa1334a48%22%7D; close_finance_popup=2018-12-31; cityDomain=www; preTime=%7B%22last%22%3A1546220511%2C%22this%22%3A1545915036%2C%22pre%22%3A1545915036%7D'
}
base_url = 'https://www.guazi.com'
def get_url(url):
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
doc = pq(r.text)
items = doc('.carlist li').items()
for item in items:
href = item.find('a').attr('href')
href = base_url + href
get_detail(href)
def get_detail(href):
r = requests.get(href, headers=headers)
r.encoding = r.apparent_encoding
doc = pq(r.text)
title = doc('.titlebox').remove('span').text()
brand = title.split(' ')[0]
series = title.split(' ')[1]
match = re.search('[A-Za-z0-9]', brand)
if match:
match = match.group()
series = match + brand.split(match)[1]
brand = brand.split(match)[0]
types = title.split(' ')[-1]
car_license = doc('.one div').text()
mileage = doc('.two div').text().split('万')[0]
site = doc('.three div').text()
standard = doc('.four div').remove('em').text()
gearbox = doc('.five div').text()
cc = doc('.six div').text()
price = doc('.pricestype').remove('.f14').text().split('¥')[-1]
print(brand, series, types, car_license, mileage, site, standard, gearbox, cc, price)
sql = """
insert into ershouche(brand,series,types,car_license,mileage,site,standard,gearbox,cc,price)
values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
try:
curser.execute(sql, (brand, series, types, car_license, mileage, site, standard, gearbox, cc, price))
db.commit()
except:
db.rollback()
if __name__ == '__main__':
urls = ['https://www.guazi.com/www/buy/o{}c-1/#bread'.format(str(i)) for i in range(1, 11642)]
pool = Pool(processes=4)
pool.map(get_url, urls)
curser.close()
db.close()
需要补充的是,爬取瓜子网,必须要加cookies,否则会抓不到数据。
下面是简单的绘图分析:
1 手动自动变速箱占比

Figure_1.png
不知道大家买车时有没有朋友总是强烈推荐自动挡车型:‘市区开车不累’,‘简单容易上手’,‘手动挡快淘汰了’等等。从图中也可以看出,自动档变速箱占据绝对的数量优势,但是手动变速箱并没有我想象中的少,看来手动变速箱还是有一定的受众人群的。
2 各国标占比

Figure_2.png
可以看出,国四车型保有量最高,也算意料之中,国五车型现在基本上还算是新车,国三面临淘汰,国四自然是二手车市场的主力军了。
3 二手车保有量前十品牌
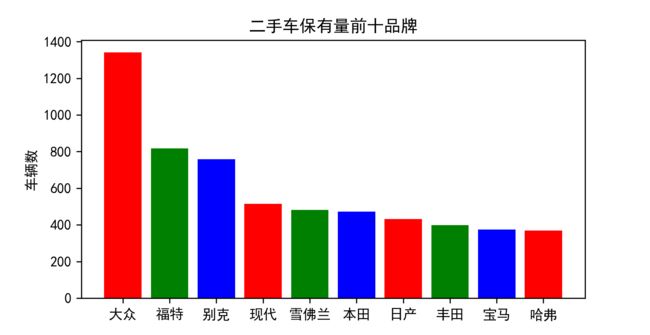
Figure_3.png
大众神车果然不负众望,以压倒性优势夺得第一。前十之中自主品牌只有哈弗一支独苗。
4 各价位二手车保有量
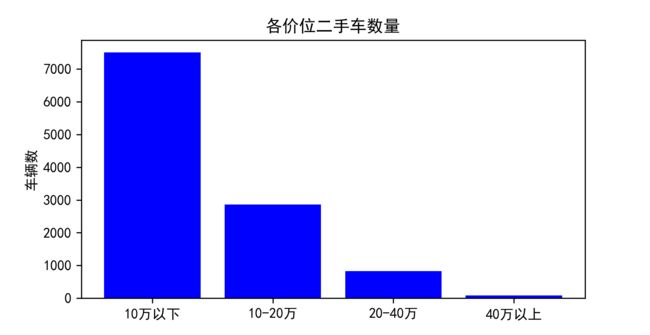
Figure_4.png
10万以下的二手车,数量异常庞大。同时,这也是大多数买二手车的人考虑最多的价格区间。毕竟,花个几十万买辆二手车的人还是稀有的吧。