前言
关于C10K的问题就不多说了,应该是一个说烂的话题。网上也有很多C1000k,甚至C10M(也就是1kw并发)的文章,后面会给出我所阅读和学习的很多参考,这里也不多说了,这里我只给出在我深入研究了这些资料和总结之后的思路。
总的来说,要完成这个目标,首先要考虑的就是系统能分配的资源是否满足100w并发的需求,然后逐步分解,比如内存够不够,文件描述符够不够,然后再往下看应该怎么满足,调整参数等。下面是我给予自己的理解绘制的一张思维导图,应该说还是十分简明清晰的。

如果只是要简单的达成100w的并发,其实真的蛮简单的,只要把我这张图的第一部分的参数调整好基本上,内存稍大一点的台式机或笔记本都能很容易实现,欢迎各位看官看完之后自己去测试。
下面,就先给予这张图的步骤逐步展开讲解下。
如何达成100w连接
▶ 单个连接内存占用计算
⊙ 内核中单个socket占用的内存
使用命令查找内核中每个网络连接的内存配置参数:sysctl -A | grep net | grep mem
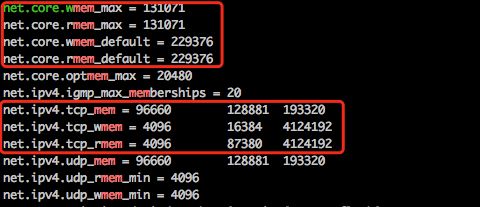
上面第一组勾红的地方就是内核中任意一个网络连接(包括TCP、UDP等各种网络连接)能使用的最大和默认内存大小,单位是字节。
上面第二组勾红的地方,后面两个就是内核中单个TCP连接能使用的最小、默认和最大内存大小。其中net.ipv4.tcp_wmem和tcp_rmem的单位是字节。第二组第一个net.ipv4.tcp_mem参数是tcp协议可用的内存上限,的单位是页(一般一个页的大小为4k,可以通过 `getconf PAGESIZE` 查看)。
从这里看出,这里允许分配给tcp的最大内存是193320*4k≈755M。需要注意的是,要支持100w以上的链接,分配给tcp_mem的这点内存显然是严重不够的,后面也是需要调整的。
需要注意的地方是:
net.ipv4.tcp_wmem和net.ipv4.tcp_rmem的默认值分别会覆盖net.core.wmem_default和net.core.rmem_default,但是net.ipv4.tcp_wmem和net.ipv4.tcp_rmem的最大值不会覆盖net.core.wmem_max和net.core.rmem_max!
官方文档上并没有直接说net.ipv4.tcp_wmem的最大值和net.core.wmem_max这两者的优先级,但是从逻辑上推断,既然net.ipv4.tcp_wmem的最大值不能覆盖net.core.wmem_max,那么应该是二者取其小,也就是说一个tcp连接能使用的写缓存不会大于两者中最小的那个值。
一般情况下,linux内核每次创建一个网络连接时,都为为它分配一个发送缓冲区和一个接收缓冲区。这个发送缓冲区的大小就是net.core.wmem,对于tcp连接,则会使用覆盖的net.ipv4.tcp_wmem,接收缓冲区大小则是net.core.rmem,对于tcp连接,则会使用覆盖的net.ipv4.tcp_rmem,从上面的结果来看,发送缓冲区默认是16384字节,接收缓冲区默认是87380字节。对于tcp连接而言,随着连接数的上升,这些缓冲区大小会逐渐减少,最后接近或等于net.ipv4.tcp_wmem/net.ipv4.tcp_rmem的最小值。同理,连接数减少时,缓存区大小会逐渐增大,最后接近或等于net.ipv4.tcp_wmem/net.ipv4.tcp_rmem的最大值。
每一个tcp连接占用的内存计算可以简化为:tcp写(发送)缓存+tcp读(接收)缓存。
因此,一个tcp连接在内核中需要占用的最小内存是:net.ipv4.tcp_wmem的最小值 + net.ipv4.tcp_rmem的最小值,根据默认配置,这个值就是 4096+4096,也就是8k。因此,我们可以说默认情况一个tcp连接占用的内存应该是8k!
⊙ 应用层面单个socket占用的内存
这个要视具体语言平台对socket的封装对象对内存的占用,比如,这里就不多讲述了,根据自己具体业务实际消耗来计算就对了。
▶ 100w连接需要的资源分配和参数调整
⊙ 系统内存
根据上面的计算,对于100w连接,单在内核内存上的占用就需要消耗: 1000000 x 8k ≈ 7.63G 的内存。因此,建议为机器配置16G内存来进行测试。
⊙ Socket内存上限调整
根据前面的分析,系统内核参数中的net.ipv4.tcp_mem,根据内核参数文档说明(传送门),tcp_mem就是系统能够分配给tcp协议的内存限制(注意,这是整个TCP协议栈能使用的最大内存,包括所有进程),因此根据上面的计算,1个tcp连接占用8k内存,也就是2页,所以tcp_mem应该设置超过2*100w=200w页。
`# echo "net.ipv4.tcp_mem = 786432 2097152 3145728">> /etc/sysctl.conf`
以上的值分别是3G、6G、16G。这个值设置过小的话,如果系统资源不足以分配多余的socket,会拒绝分配socket,报“TCP: socket out of memory”的错误。
⊙文件描述符上限调整
在linux系统中,每一个socket都要占用一个文件描述符。每一个文件描述符都需要占用一定的系统资源,鉴于内存资源有限,linux系统分别从三个层面上对能打开的文件描述符设了上限。
1、系统级。linux系统规定了整个系统文件描述符上限,也就是所有进程加起来能使用的文件描述符的上限。这个值可以通过 `cat /proc/sys/fs/file-max` 命令获取。这个值通常是由系统根据实际资源情况计算出的一个相对合理的建议值,但如果在/etc/sysctl.conf中配置过fs.file-max,则将显示配置的值。
2、shell级。表示将当前shell的当前用户所有进程能打开的最大文件数量。这个值可以通过 `ulimit -n` 命令获取,默认值一般是1024。(注意,如果当前不是root用户,修改超过1024,会报权限错误“bash: ulimit: open files: cannot modify limit: Operation not permitted”)
3、用户级。ulimit -n是设置当前shell的当前用户所有进程能打开的最大文件数量,但是一个用户可能会同时通过多个shell连接到系统,所以还有一个针对用户的限制,这个值可以通过文件/etc/security/limits.conf查看,例如,我的机器是:
*表示所有用户,上面两行语句表示,所有用户的软限制为65535,硬限制为65535,即表示所有用户能打开的最大文件数量为65535,不管它开启多少个shell。如果是具体哪个用户,可以单独修改,比如 root soft nofile 10000,意思就是设定root的软上限为10000。软限制和硬限制的区别就是软限制可以在程序的进程中自行改变(突破限制),而硬限制则不行(除非程序进程有root权限),因此soft限制值必须<=hard限制值!
由此可知,要支持100w的连接,以上三个级别的参数值全部需要修改!修改方法如下:
▶ 系统级调整。这个值可以通过修改系统内核参数fs.file-max来完成,方法如下:
临时修改。`# echo 1100000 > /proc/sys/fs/file-max`,或`# sysctl -w fs.file-max=65536`。
永久修改。`# echo "fs.file-max=1100000" >> /etc/sysctl.conf`, 执行`sysctl -p`可立即生效
注意:此外,这里还有一个非常重要的参数需要介绍,就是fs.nr_open,根据内核文档(传送门)说明,nr_open就是linux系统一个进程能够打开的最大文件描述符数量。
Linux 内核源码中有一个常量(NR_OPEN in /usr/include/linux/fs.h), 从系统源码层面限制了最大打开文件数, 多数linux默认设置nr_open是 1024k,也就是1048576,最大不能超过4096k,所以, 想要支持超过100k,还需要在/etc/sysctl.conf中重新上配置fs.nr_open的值,要想支持 C4000K, 你可能还需要重新编译内核。当然,因为默认nr_open是1024k,基本上能满足绝大多数应用场景,很多人在介绍高并发的时候,也可能没有注意到这个参数的存在。
所以,为了支持超过1024k的链接,同样需要把fs.nr_open设置超过1024k,方法同fs.file-max的修改:
`# echo "fs.nr_open=1100000" >> /etc/sysctl.conf`, 执行`sysctl -p`可立即生效
下图是linux内核源码文件的截图

▶ shell级调整。
shell级可以通过`# ulimit -n 1100000`来设置,但是该值将受限于limits.conf的值,重新登录就会失效,重置为limits.conf里面的值。所以,一般设置好下面用户级的,重新登陆下shell就好了。
▶ 用户级。用户级限制可以通过修改/etc/security/limits.conf文件完成。就像前面描述的一样,修改方式参考:
root soft nofile 1100000
root hard nofile 1100000
也可以简写为
root - nofile 1100000
如果是全部用户,还可以简写为
* - nofile 1100000
⊙网络及路由器
百万连接的吞吐量是否超过了网络限制?
假设百万连接中有 20% 是活跃的, 每个连接每秒传输 1KB 的数据, 那么需要的网络带宽是 0.2M x 1KB/s x 8 = 1.6Gbps, 要求服务器至少是万兆网卡(10Gbps)。
如何测试100w连接
▶ 高并发客户端模拟
为了测试100w连接的有效性和稳定性,我们同样需要模拟发起100w的客户端连接来进行测试,那怎么做大的?
客户端跟服务端不同的地方在于,客户端每向服务器发起一个连接就要占用一个端口,而大家都知道,一个端口是用一个short int来表示的,这就意味着端口最多只有65535个!使用时还要去除一些保留端口和被占用的端口,能实际使用的端口大约为6w个左右。那如何产生100w的连接呢?
所以这里就到了考验网络基础知识是否扎实的时候了。其实端口的概念是在IP之上的,TCP或UDP才有端口的概念,IP层是没有的!换句话上,每一个IP上都可以对应一组端口,也就是说理论上每个IP都可以对应65535个端口。而一台机器其实是可以拥有多个ip的!
拥有多个ip的方式有两种,一种就是安装多块网卡,每一块网卡拥有一个ip,但网卡却不必都是真实的,可以通过虚拟网卡(桥接就可以)的方式实现。因此,我们其实只需要一个真实网卡,再桥接多个虚拟网卡即可。其实还有另一种更简单的方法,就是一块网卡其实可以同时设置多个IP,也称为“ip别名”。这里测试方法使用的即是ip别名,强烈推荐使用这种方法。
客户端IP实际配置:
sudo ifconfig ens33:1 192.168.10.131 netmask 255.255.255.0 up
假定每个IP发起6.4个连接,也就是使用6.4w个端口,通过16个IP,就可以产生10240000个连接。因此,我们用1台机器,1块物理网卡+15块虚拟网卡桥接,就可以模拟产生100w的客户端连接请求(同样的方法,使用156个ip可以同时发起1000w个连接请求,但对网络及路由器的要求就会非常高了)。
此外,客户端跟服务器一样,默认每个tcp连接在内核中至少需要占用8k的内存,因此100w的tcp连接,同样需要消耗服务器至少7.63G的内存。因此,同样建议客户端机器配置16G内存进行测试!
实测
我在实际测试的时候,受限于当前服务器资源,真实的测试全部是在一台使用vsphere虚拟化的16G的台式机上完成的。
我在上面运行了两台ubuntu的虚拟机,一台分配了12G的内存,作为服务器,另一台分配了4G的内存,作为客户端。
▶服务端
实际测试显示,一个socket连接在node中实际需要占用大约2.5k内存,因此100w连接node至少需要2.5G的内存,而node默认能为堆分配的最大内存在64位系统下仅为1.4G(这个在deps/v8/src/heap/heap.cc文件中可以看到,值是max_old_generation_size_),这显然是不够的,因此需要使用--max-old-space-size选项启动,开启更高的使用内存。这里设置为8G,如下:
`node --max-old-space-size=8000 server.js`
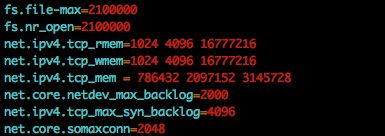
我的服务端最终参数调整如下:
▶ 客户端
因为内存有限,按照上面的计算,客户端的内存显然是无法支撑起这个并发数的,因此,我把net.ipv4.tcp_rmem和net.ipv4.tcp_wmem的最小值全部调整成了1024字节,因此,一个socket,其实内核只需要消耗2k的内存即可,100w的连接,只需要不到2G的内存。
原本测试客户端也是用node编写,但测试时发现每一个连接在node中也需要占用大约2.5k的内存,因此每个连接整体占用至少需要4.5k,客户端的4G内存显然不足以支持这个并发数,因此就修改了一下网上的c版本的测试客户端来进行,c版本的客户端,因为没有运行任何业务,也没有对socket的高层封装,在应用层几乎不占用任何内存。
我的客户端最终参数调整如下:

为客户端分配ip的方法参考:
sudo ifconfig ens33:1 192.168.10.131 netmask 255.255.255.0 up
sudo ifconfig ens33:2 192.168.10.132 netmask 255.255.255.0 up
sudo ifconfig ens33:3 192.168.10.133 netmask 255.255.255.0 up
sudo ifconfig ens33:4 192.168.10.134 netmask 255.255.255.0 up
sudo ifconfig ens33:5 192.168.10.135 netmask 255.255.255.0 up
...
▶ 测试过程
1、服务器启动初始状态。
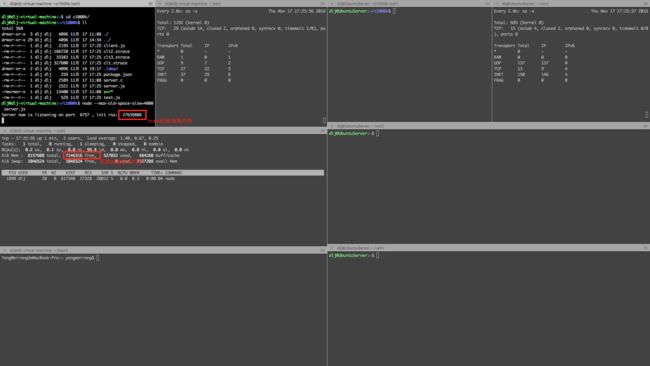
可以看到,服务端初始系统剩余内存 7146316K,Node初始占用内存 27639808b,此时连接数为0。
2、连接数到达100w

每个连接消耗的平均内存:7146316 - 1387364 / 1000000 = 5.76k
每个连接node消耗的平均内存:2.27k(参见终端)
由此计算,每个连接系统内核消耗的平均内存:5.76 - 2.27 = 3.49k
达成100W连接及相关优化
最后给出一张带个人思考的包含部分类型服务器优化思路的思维导图,仅供参考。

关于linux内核参数的说明:
第一次打开/etc/sysctl.conf文件,会看到里面其实是空的,但是运行`cat /proc/sys/net/ipv4/tcp_mem`又能看到参数。这其实是因为系统内核参数的默认参数有两种形态,一种是固定的,这种不区分机器和配置,值都是统一的,比如net.core.somaxconn,默认都是128;一种是系统估算的优化值,这个通常是根据系统当前的硬件环境自动估算的一个建议值,比如net.tcp_mem,会在系统启动时,根据系统可用内存设定一个建议值。这些参数最终都可以被/etc/sysctl.conf文件中配置的值覆盖。
这里对前面用到的几个内核参数再详细说明一下:
net.ipv4.tcp_mem:需要注意的是,这是tcp协议能使用的总内存大小(是总内存,包括所有进程创建的所有套接字)。所以,这个要根据自己的业务情况实际设置,小了的话,内核汇报socket out of memory异常,大了浪费内存。
net.ipv4.tcp_rmem和net.ipv4_tcp_wmem:需要注意的是,这个是针对每个连接的,他们值的设置应该考虑实际情况。值设小了,会导致网络发包频繁,影响整体网络传输效率,设大了,连接数高时,系统内存负荷会很大。
还有一些跟高并发高负载服务器优化相关的参数,这里也一并给出解释和使用说明:
net.core.somaxconn:listen侦听队列的长度(包括syn_revd和established状态,共两个队列的长度),默认128。服务器业务负荷过大,来不及处理握手或就绪状态的连接时,多余的握手请求会被扔掉,可能导致客户端产生connection timeout的异常,这个时候应该把这个值调大。
net.ipv4.tcp_max_syn_backlog:文档上的说法是还没有收到对方ACK的连接请求队列长度,我的理解就是syn_revd状态的队列长度。低内存的机器上默认128,配置高的时候会自动设置的高一点。同somaxconn一样,多余的握手请求会被扔掉,可能导致客户端产生connection timeout的异常,服务器负载高的时候,应该把这个值调大。
net.ipv4.tcp_max_orphans:系统所能处理不属于任何进程的TCP sockets最大数量,也就数无主socket,或称为孤儿socket。假如超过这个数量﹐那么不属于任何进程的连接会被立即reset,并同时显示警告信息。之所以要设定这个限制﹐纯粹为了抵御那些简单的 DoS 攻击﹐千万不要依赖这个或是人为的降低这个限制(这个值Ubuntu版本中设置为65536,但是很多防火墙修改的时候,建议该值修改为2000,我确实搞不懂文档中强调这个为啥不提倡降低,毕竟一个孤儿socket需要占用~64k内存啊!)
net.core.netdev_max_backlog:网卡接收队列。这个跟somaxconn和tcp_max_syn_backlog参数类似,但是更底层,指的是网卡的接收队列。也就是当每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
net.ipv4.tcp_fin_timeout :对于本端断开的socket连接,TCP保持在FIN-WAIT-2状态的时间,默认为60s。对方可能会断开连接或一直不结束连接或不可预料的进程死亡。默认值为 60 秒。您可以设置该值﹐但需要注意﹐如果您的机器为负载很重的web服务器﹐您可能要冒内存被大量无效数据报填满的风险﹐FIN-WAIT-2 sockets 的危险性低于 FIN-WAIT-1 ﹐因为它们最多只吃 1.5K 的内存﹐但是它们存在时间更长。因为FIN-WAIT-2的下一个状态就是time-wait,减少处于FIN-WAIT-2连接状态的时间,使系统可以处理更多的连接(其实我也没搞懂把这个值调高的意义到底在哪里)。
net.ipv4.tcp_keepalive_time:减少TCP KeepAlive连接侦测的时间,可以使得服务器更快的侦测出异常退出的客户端连接。默认为7200s,我的建议完全可以设置为1800s。
net.ipv4.tcp_window_scaling:该文件表示设置tcp/ip会话的滑动窗口大小是否可变。参数值为布尔值,为1时表示可变,为0时表示不可变。tcp/ip通常使用的窗口最大可达到65535 字节,对于高速网络,该值可能太小,这时候如果启用了该功能,可以使tcp/ip滑动窗口大小增大数个数量级,从而提高数据传输的能力。我没在网上找到清楚的关于这个的介绍,但从推测上来说,既然是发送窗口,那应该使用的就是tcp的发送缓冲区,也就是说受限于net.ipv4.tcp_wmem的最大值。调大该值可以提高网络传输能力,因为这样对方可以发数据快一点,但会带来服务端更大的内存开销。所以跟net.ipv4.tcp_wmem的原则是一样的。
net.ipv4.tcp_sack:该文件表示是否启用有选择的应答(Selective Acknowledgment),这可以通过有选择地应答乱序接收到的报文来提高性能(这样可以让发送者只发送丢失的报文段);(对于广域网通信来说)这个选项应该启用,但是这会增加对 CPU 的占用。
爬虫类服务器(产生大量连接请求的)相关优化参数:
net.ipv4.tcp_tw_recycle:是否启用timewait状态快速回收。
net.ipv4.tcp_tw_reuse:开启开启立即重用。允许将time_wait状态的sockets重新用于新的TCP连接。
net.ipv4.ip_local_port_range:调大这个范围,可以让本地同时发起更多的连接。
结束语
作为真实的业务系统,零业务稳定达成100w并发连接并不困难,也只是开始的第一步。真正的挑战还在于高并发集群和后台复杂业务系统的实现。但是通过我这种形式的整理,可以作为思考的第一步,知晓在面对一个有挑战和复杂的问题时的思考切入点。
测试代码等优化的好看一点,稍后再推到Github上。
▶ 参考资料
网络相关内核参数官方文档:
通用部分(net.core.*):
https://www.kernel.org/doc/Documentation/sysctl/net.txt
ip(含tcp和udp,net.ipv4.*)部分:
https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
文件系统部分(fs.*):
https://www.kernel.org/doc/Documentation/sysctl/fs.txt
参考资料:
《Linux高性能服务器编程》:强烈推荐
TCP协议RFC文档:
https://tools.ietf.org/rfc/rfc793.txt
100万并发连接服务器笔记之1M并发连接目标达成:
http://www.blogjava.net/yongboy/archive/2013/04/11/397677.html
构建C1000K的服务器(1) – 基础:
http://www.ideawu.net/blog/archives/740.html
linux最大文件句柄数量之(file-max ulimit -n limit.conf):
http://wushank.blog.51cto.com/3489095/1617874
What's orphaned sockets and how can I prevent them?:
https://www.quora.com/Whats-orphaned-sockets-and-how-can-I-prevent-them
The Secret To 10 Million Concurrent Connections -The Kernel Is The Problem, Not The Solution:
http://highscalability.com/blog/2013/5/13/the-secret-to-10-million-concurrent-connections-the-kernel-i.html
使用四种框架分别实现百万websocket常连接的服务器:
http://colobu.com/2015/05/22/implement-C1000K-servers-by-spray-netty-undertow-and-node-js
解决恶心的 Nf_conntrack: Table Full 问题:
http://jerrypeng.me/2014/12/08/dreadful-nf-conntrack-table-full-issue/
C1000K-Servers:
https://github.com/smallnest/C1000K-Servers
node.js长连接高并发问题,很有挑战,大家来讨论下:
https://cnodejs.org/topic/50e5900da7e6c6171a0159d7
关于 Out of Socket memory 的解释:
http://jaseywang.me/2012/05/09/%E5%85%B3%E4%BA%8E-out-of-socket-memory-%E7%9A%84%E8%A7%A3%E9%87%8A-2/
Linux网络编程socket错误分析:
http://blog.csdn.net/uestc_huan/article/details/5863614
使用四种框架分别实现百万websocket常连接的服务器:
http://colobu.com/2015/05/22/implement-C1000K-servers-by-spray-netty-undertow-and-node-js/