目录
- Kubernetes弹性伸缩简介
- HPA简介
- Metrics Server
- 1. 生成metrics-server证书
- 2. 修改kubernetes master 配置文件
- 3. 安装metrics-server
- HPA配置示例
Kubernetes弹性伸缩简介
通过手工执行kubectl scale命令或者通过修改deployment的replicas数量,可以实现Pod扩缩容。我们还可以通过定时任务的方式在一些可预见的业务高峰场景实现Pod的定时伸缩。然而在更多的应用场景当中,业务的请求量峰值其实是不可控的。这就需要我们借助一些自动伸缩的手段,例如通过监控Pod的资源使用率、访问的QPS等指标来实现自动的弹性伸缩。
Kubernetes从两个维度上支持自动的弹性伸缩:
- Cluster AutoScaler:处理kubernetes集群node节点的伸缩,其严重依赖IaaS厂商提供的云主机服务和资源监控服务
- HPA(Horizontal Pod Autoscaler):处理Pod副本集的自动弹性伸缩,其依赖监控服务采集到的资源监控指标数据
HPA简介
HPA本质上也是Kubernetes的一种资源对象。通过周期性检查Deployment控制的目标Pod 的相关监控指标的变化情况,来确定是否需要针对性地调整目标Pod的副本数。
通常应用的扩缩容都是由cpu或内存的使用率实现的。事实上在早期的kubernetes版本当中,hpa只支持基于cpu使用的率的扩缩容,而hpa获取到的cpu使用率指标则来源于kubernetes自带的监控系统heapster。
而从kubernetes 1.8版本开始,资源的使用指标改为通过metrics api获取。而heapster当前已经废弃。
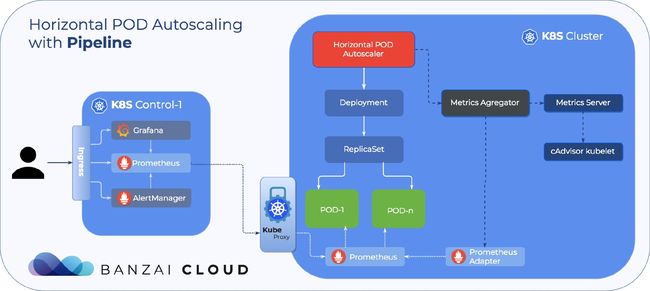
Kubernetes将资源指标分为了两种:
- core metrics(核心指标): 采集每个节点上的kubelet公开的summary api中的指标信息,通常只包含cpu、内存使用率信息
- custom metrics(自定义指标):允许用户从外部的监控系统当中采集自定义指标,如应用的qps等
在autoscaling/v1版本中只支持CPUUtilizationPercentage一种指标,在autoscaling/v2beta1中增加支持custom metrics
下面以cpu使用率指标来说明hpa是如何来根据指标使用伸缩的:
CPUUtilizationPercentage即cpu使用率的百分比。hpa判断的标准是目标Pod所有副本自身的CPU利用率的平均值。一个Pod自身的CPU利用率是该Pod当前的CPU的使用量除以它的CPU Request的值。
比如定义一个Pod的CPU Request为0.4,而当前的Pod的CPU使用量为0.2,则它的CPU使用率为 50%,这样计算一个Deployment的所有Pod的cpu使用率的平均值。如果某一刻该值超过80%,则意味着当前的Pod 副本数很可能不足以支撑接来下更多的请求,需要进行动态扩容,而当前请求高峰时段过去后,Pod的 CPU 利用率又会降下来,此时对应的Pod副本数应该自动减少到一个合理的水平。
CPUUtilizationPercentage计算过程中使用到的Pod的CPU使用量通常是1min内的平均值。
Metrics Server
前面我们说到,核心指标的采集是通过metrics api获取,而Metrics Server实现了Resurce Metrics API。Metrics Server 是集群范围资源使用数据的聚合器。由Metrics Server从每个节点上的Kubelet公开的Summary API 中采集指标信息。也就是说,如果需要使用kubernetes的HPA功能,需要先安装Metrics Server。
1. 生成metrics-server证书
创建metrics-server-csr.json文件,内容如下:
{
"CN": "aggregator",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "Hubei",
"L": "Wuhan",
"O": "k8s",
"OU": "System"
}
]
}生成metrics-server证书和密钥
cfssl gencert --ca ca.pem --ca-key ca-key.pem --config ca-config.json --profile kubernetes metrics-server-csr.json | cfssljson --bare metrics-server
关于生成证书指令中,使用的ca.pem ca-key.pem以及ca-config.json,可参考《手动部署一个单节点kubernetes》
2. 修改kubernetes master 配置文件
在kube-apiserver的启动指令中添加如下参数:
kube-apiserver
...
--requestheader-client-ca-file=/etc/kubernetes/ssl/ca.pem \
--requestheader-allowed-names=aggregator \
--requestheader-extra-headers-prefix=X-Remote-Extra- \
--requestheader-group-headers=X-Remote-Group \
--requestheader-username-headers=X-Remote-User \
--proxy-client-cert-file=/etc/kubernetes/ssl/metrics-server.pem \
--proxy-client-key-file=/etc/kubernetes/ssl/metrics-server-key.pem \在kube-controller-manager的启动指令中添加如下参数:
kube-controller-manager
...
--horizontal-pod-autoscaler-use-rest-clients=true \
--horizontal-pod-autoscaler-downscale-delay=5m0s \
--horizontal-pod-autoscaler-upscale-delay=1m0s \
--horizontal-pod-autoscaler-sync-period=20s \
...配置项说明:
- horizontal-pod-autoscaler-use-rest-clients: 开启基于rest-clients的自动伸缩
- horizontal-pod-autoscaler-sync-period:自动伸缩的检测周期为20s,默认为30s
- horizontal-pod-autoscaler-upscale-delay:当检测到满足扩容条件时,延迟多久开始缩容,即该满足的条件持续多久开始扩容,默认为3分钟
- horizontal-pod-autoscaler-downscale-delay:当检测到满足缩容条件时,延迟多久开始缩容,即该满足条件持续多久开始缩容,默认为5分钟
3. 安装metrics-server
metrics-server代码仓库地址: https://github.com/kubernetes-incubator/metrics-server
当前最新的release版本为v0.3.6,下载最新版本。然后执行如下操作:
cd deploy/1.8+/
# 修改镜像地址
sed -i '[email protected]/metrics-server-amd64:[email protected]/google_containers/metrics-server-amd64:v0.3.6@g' metrics-server-deployment.yaml
# 配置command
编辑metrics-server-deployment.yaml,配置如下内容:
...
containers:
- name: metrics-server
image: hub.dz11.com/library/metrics-server-amd64:v0.3.6
command:
- /metrics-server
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
imagePullPolicy: Always
...
kubectl apply -f ./以上操作会在kube-system命名空间启动一个名称前缀为metrics-server的pods以提供实时的数据采集。
在metrics-server-deployment.yaml中添加了一个command,加了两个kubelet的配置项,如果不添加此项,metrics-server无法采集数据指标,会抛出异常:
x509: certificate signed by unknown authority, unable to fully scrape metrics from source kubelet_summary
验证安装:
# 在apiservice中可以看到多了一个接口
kubectl get apiservice
...
v1beta1.metrics.k8s.io 2019-10-17T03:14:46Z
...
# 通过访问metrics.k8s.io接口,如能正常访问代表安装成功
kubectl get --raw "/apis/metrics.k8s.io/v1beta1" | jq .
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "metrics.k8s.io/v1beta1",
"resources": [
{
"name": "nodes",
"singularName": "",
"namespaced": false,
"kind": "NodeMetrics",
"verbs": [
"get",
"list"
]
},
{
"name": "pods",
"singularName": "",
"namespaced": true,
"kind": "PodMetrics",
"verbs": [
"get",
"list"
]
}
]
}还可以通过如下接口获取相应的监控指标:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
...
{
"metadata": {
"name": "cn-beijing.i-2zeacc5qws1k6yr96yf6",
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes/cn-beijing.i-2zeacc5qws1k6yr96yf6",
"creationTimestamp": "2019-10-21T07:46:44Z"
},
"timestamp": "2019-10-21T07:46:00Z",
"window": "1m0s",
"usage": {
"cpu": "3254m",
"memory": "47416324Ki"
}
}
...
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .
...
{
"metadata": {
"name": "arrow-feature-userprofile-975-6cb874c85f-h2gfx",
"namespace": "bigdata",
"selfLink": "/apis/metrics.k8s.io/v1beta1/namespaces/bigdata/pods/arrow-feature-userprofile-975-6cb874c85f-h2gfx",
"creationTimestamp": "2019-10-21T07:48:25Z"
},
"timestamp": "2019-10-21T07:48:00Z",
"window": "1m0s",
"containers": [
{
"name": "arrow-feature-userprofile",
"usage": {
"cpu": "125m",
"memory": "2560436Ki"
}
}
]
}
...
确保这里可以正常获取指标,否则检查metrics-server日志,看是否抛出了相关异常
HPA配置示例
在github上有一个开源项目,叫作k8s-prom-hpa,项目地址为:https://github.com/stefanprodan/k8s-prom-hpa。
在下一节《kubernetes HPA使用自定义指标》中,我们会说到这个项目。现在在这个项目中,有一个目录名为podinfo。这是一个golang小程序示例。
我们获取这个demo,并部署:
# 修改podinfo的版本为2.0.0版本
sed -i 's/0.0.1/2.0.0' podinfo/pidinfo-dep.yaml
# 修改podinfo-dep.yaml文件,去掉如下command部分:
...
#command:
# - ./podinfo
# - -port=9898
# - -logtostderr=true
# - -v=2
...
kubectl apply -f podinfo/podinfo-dep.yaml,podinfo/podinfo-svc.yaml,podinfo/podinfo-ingress.yaml通过其ingress配置文件,可以看到其对外暴露host名称为podinfo.weavedx.com,我们可以通过绑定主机名的方式来访问该应用。
在我的测试环境中,因为使用的ingress是traefik,而不是官方的nginx,所以我还需要修改kubernetes.io/ingress.class这个annotations为traefik
接下来,为该demo应用添加一个hpa,内容如下:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: podinfo
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: podinfo
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 80
- type: Resource
resource:
name: memory
targetAverageValue: 200Mi当podinfo的所有副本的cpu使用率的值超过request限制的80%或者memory的使用率超过200Mi时会触发自动动态扩容行为,扩容或缩容时必须满足一个约束条件是Pod的副本数要介于2与10之间。
执行压力测试:
# install hey
go get -u github.com/rakyll/hey
./go/bin/hey -n 10000 -q 10 -c 5 http://podinfo.weavedx.com查看hpa相关事件确认扩缩容:
kubectl describe hpa podinfo
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 2m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 16s horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
kubectl get pods |grep podinfo
#输出:
podinfo-7b46d7c547-284x8 1/1 Running 0 31s
podinfo-7b46d7c547-4gkcr 1/1 Running 0 23m
podinfo-7b46d7c547-6jnqk 1/1 Running 0 31s
podinfo-7b46d7c547-8xt7p 1/1 Running 0 31s
podinfo-7b46d7c547-d6fp7 1/1 Running 0 2m
podinfo-7b46d7c547-nwwrj 1/1 Running 0 31s
podinfo-7b46d7c547-pj5cs 1/1 Running 0 23m
podinfo-7b46d7c547-s5vzn 1/1 Running 0 2m
```