续前文http://www.jianshu.com/p/b27545f6d730,基于搭建好的Hadoop集群来部署Spark
1、安装 Scala
官网下载Scala,我这里下载的是最新的2.12.1
解压并设置环境变量
export SCALA_HOME=/home/spark/scala-2.12.1
export PATH=$SCALA_HOME/bin:$PATH
[root@master jre]# source ~/.bashrc
安装配置Spark
下载预编译对应hadoop版本的Spark,基于已安装好的hadoop版本,我这里下载的是spark-2.1.0-bin-hadoop2.7
配置Spark
配置spark-env.sh
cd /home/spark/spark-2.1.0-bin-hadoop2.7/conf #进入spark配置目录
cp spark-env.sh.template spark-env.sh #从配置模板复制
vi spark-env.sh #添加配置内容
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64/jre
export HADOOP_HOME=/usr/local/hadoop-2.7.3
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.3/etc/hadoop
SPARK_MASTER_HOST=master
SPARK_LOCAL_DIRS=/home/spark/spark-2.1.0-bin-hadoop2.7
SPARK_DRIVER_MEMORY=1G
注:在设置Worker进程的CPU个数和内存大小,要注意机器的实际硬件条件,如果配置的超过当前Worker节点的硬件条件,Worker进程会启动失败。
[root@master conf]# vim slaves
master
slave
将配置好的Spark文件夹分发给所有slave,我这里只有一个slave
scp -r /home/spark/spark-2.1.0-bin-hadoop2.7 root@slave:/home/spark
启动Spark
[root@master spark-2.1.0-bin-hadoop2.7]# sbin/start-all.sh
检查Spark相关进程是否成功启动
Master上:
[root@master spark-2.1.0-bin-hadoop2.7]# jps
13312 ResourceManager
3716 Master
13158 SecondaryNameNode
12857 NameNode
8697 Jps
13451 NodeManager
12989 DataNode
3807 Worker
Slave上:
[root@localhost spark-2.1.0-bin-hadoop2.7]# jps
9300 NodeManager
15604 Jps
1480 Worker
9179 DataNode
进入Spark的Web管理页面: http://192.168.1.240:8080
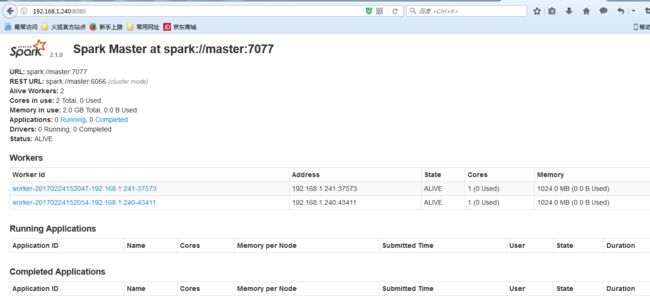
Paste_Image.png
运行示例
示例代码如下:
该示例为分别计算README.md文件中含有字母'a'和'b'的行数统计
from pyspark import SparkContext
logFile = "/user/test1/README.md" # Should be some file on your hdfs system
sc = SparkContext("local", "Simple App")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
sc.stop()
示例执行如下:
[root@master spark-2.1.0-bin-hadoop2.7]# /home/spark/spark-2.1.0-bin-hadoop2.7/bin/spark-submit --master spark:192.168.1.240:7077 --deploy-mode client /home/code/spark_test/test1.py
Lines with a: 62, lines with b: 30