题目链接:https://vjudge.net/problem/UVA-10391
这个题再一次刷新了我的世界观......原来爆搜真的可以出奇迹.....
一开始看到这12000的数据量直觉就是直接暴力枚举子串会超时,于是乎开了个二维string的向量,准备一维以首字母为检索,二维以字符串长度为检索,想着这样可以大幅度提高效率。

且听我真诚的分析:......你看,要得到组合单词,假设 a + b -> c, 那么 c 的首字母一定是和 a 的首字母一样对不对?那么我们只需要在 所有以 这个首字母的字符串中检索a 、 c就好了,对吧~
然后,将所有相同的首字母的单词按长度排个序,c 的长度一定大于a ,所以我们又可以减少一部分时间,对吧~
然后,当我们枚举一对 a 、 c 的时候,b的首字母和长度实际上已经确定了,对吧~
那么就可以直接在对应的二维数组中查找啦~

.......残酷的现实
我们分析一下超时原因:
一方面,12000个单词,它们的长度很可能是有很多相同的,用sort来排效率很低
另一方面,在找子串的过程中,我们把每个串的size算了超多遍。。我都数不清算了多少遍了,这就很浪费时间。
最后还有一个就是关于查找方式,我这个是顺序查找,如果用set可以二分查找,效率要快(这个应该也有很大影响)
其实我觉得主要是这三个问题。虽然这串代码的for循环嵌套了4层,但实际上很多都执行不了几次(因为分类分的很细,在每一个for循环里的元素数量不多),for循环应该不是最主要的。
然后,我心态很崩,我发誓一定要把这个题心态搞崩//
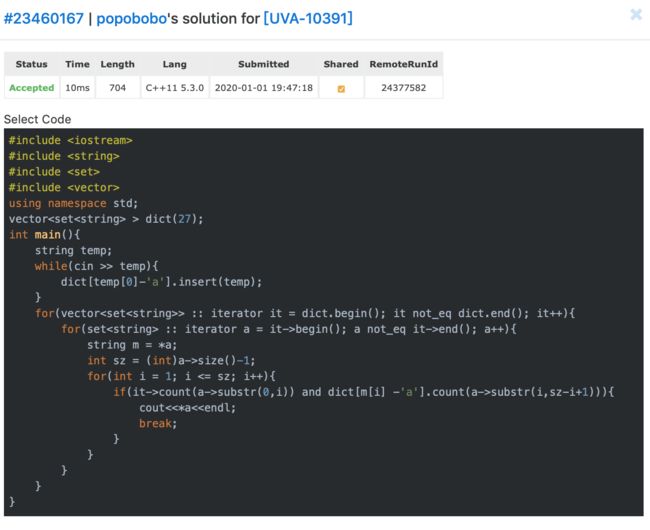
下面有我的两个AC代码:效率不同,第二个效率是第一个的4倍,还是按照首字母排了个序。
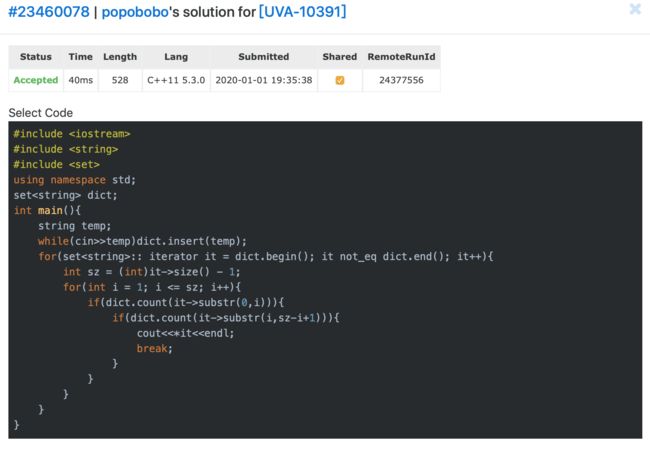
第二个,根据首字母将单词存在不同的集合中