本文首发于微信公众号:程序员乔戈里







public class testT {
public static void main(String [] args){
String A = "hi你是乔戈里";
System.out.println(A.length());
}
}以上结果输出为7。

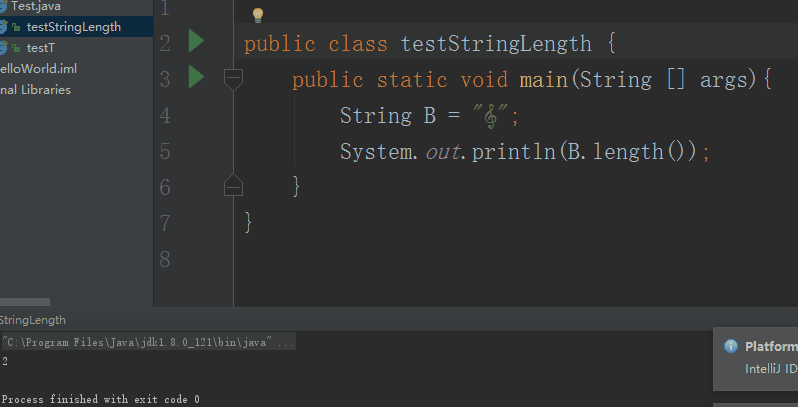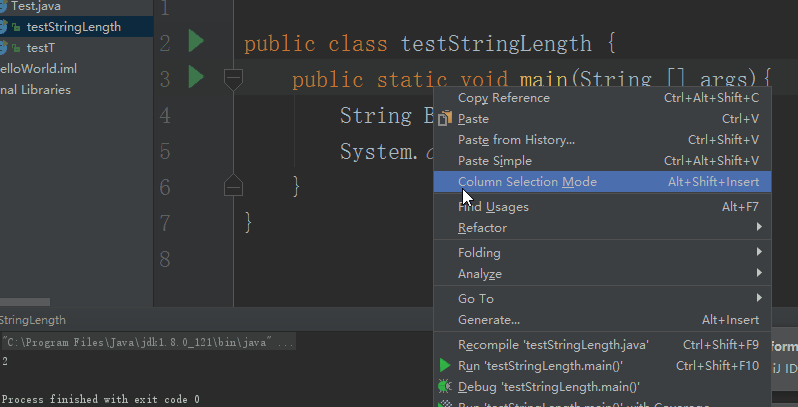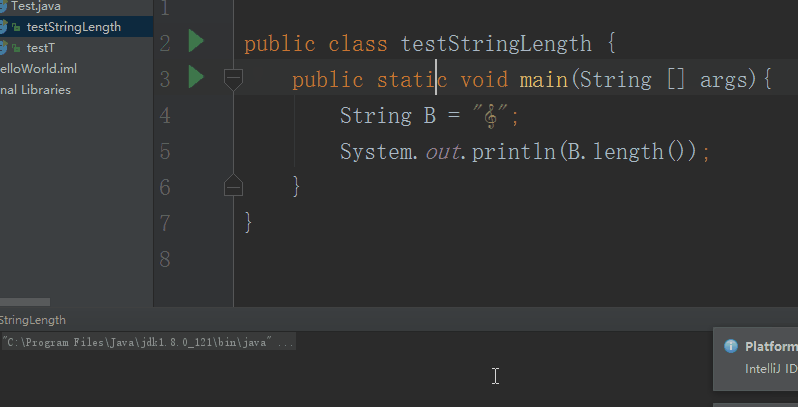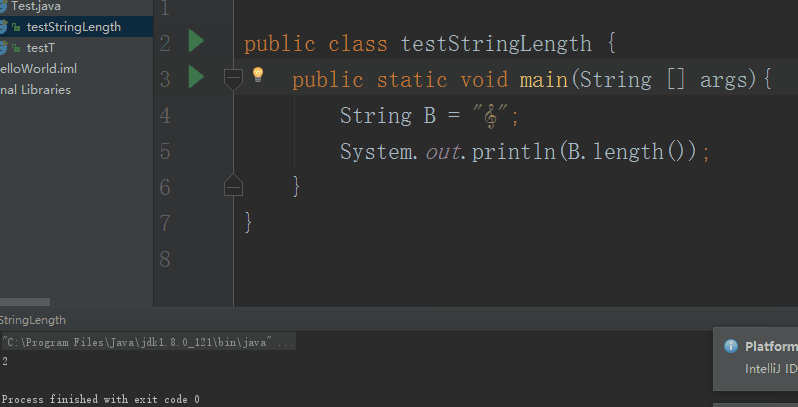



小萌边说边在IDEA中的win环境下选中String.length()函数,使用ctrl+B快捷键进入到String.length()的定义。
/**
* Returns the length of this string.
* The length is equal to the number of Unicode
* code units in the string.
*
* @return the length of the sequence of characters represented by this
* object.
*/
public int length() {
return value.length;
}接着使用google翻译对这段英文进行了翻译,得到了大体意思:返回字符串的长度,这一长度等于字符串中的 Unicode 代码单元的数目。
小萌:乔戈里,那这又是啥意思呢?
乔哥:前几天我写的一篇文章:面试官问你编码相关的面试题,把这篇甩给他就完事!里面对于Java的字符使用的编码有介绍:
Java中 有内码和外码这一区分简单来说
- 内码:char或String在内存里使用的编码方式。
- 外码:除了内码都可以认为是“外码”。(包括class文件的编码)
而java内码:unicode(utf-16)中使用的是utf-16.
所以上面的那句话再进一步解释就是:返回字符串的长度,这一长度等于字符串中的UTF-16的代码单元的数目。


代码单元指一种转换格式(UTF)中最小的一个分隔,称为一个代码单元(Code Unit),因此,一种转换格式只会包含整数个单元。UTF-X 中的数字 X 就是各自代码单元的位数。
UTF-16 的 16 指的就是最小为 16 位一个单元,也即两字节为一个单元,UTF-16 可以包含一个单元和两个单元,对应即是两个字节和四个字节。我们操作 UTF-16 时就是以它的一个单元为基本单位的。
你还记得你前几天被面试官说菜的时候学到的Unicode知识吗,在面试官让我讲讲Unicode,我讲了3秒说没了,面试官说你可真菜这里面提到,UTF-16编码一个字符对于U+0000-U+FFFF范围内的字符采用2字节进行编码,而对于字符的码点大于U+FFFF的字符采用四字节进行编码,前者是两字节也就是一个代码单元,后者一个字符是四字节也就是两个代码单元!
而上面我的例子中的那个字符的Unicode值就是“U+1D11E”,这个Unicode的值明显大于U+FFFF,所以对于这个字符UTF-16需要使用四个字节进行编码,也就是使用两个代码单元!
所以你才看到我的上面那个示例结果表示一个字符的String.length()长度是2!




来看个例子!
public class testStringLength {
public static void main(String [] args){
String B = ""; // 这个就是那个音符字符,只不过由于当前的网页没支持这种编码,所以没显示。
String C = "\uD834\uDD1E";// 这个就是音符字符的UTF-16编码
System.out.println(C);
System.out.println(B.length());
System.out.println(B.codePointCount(0,B.length()));
// 想获取这个Java文件自己进行演示的,可以在我的公众号【程序员乔戈里】后台回复 6666 获取
}
}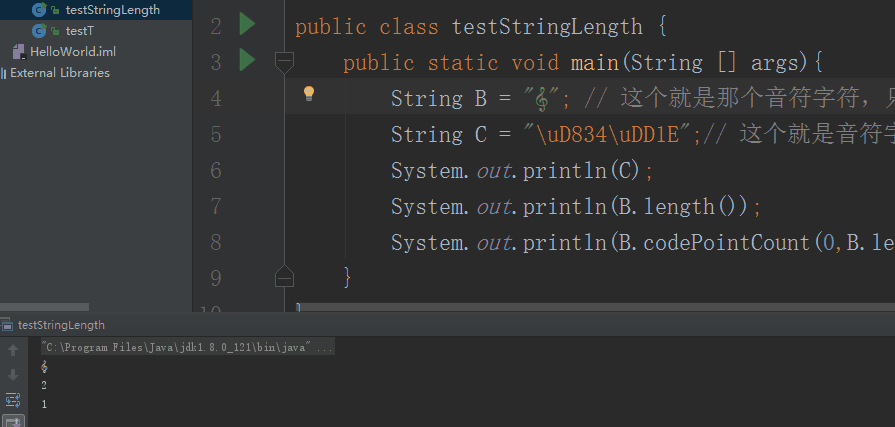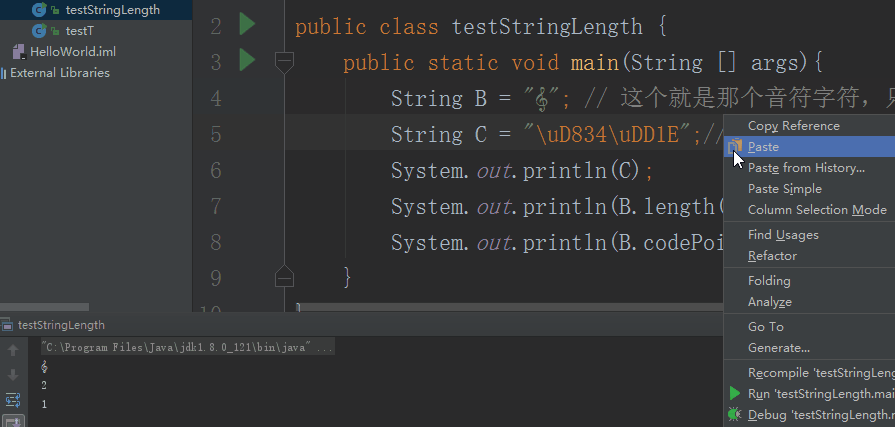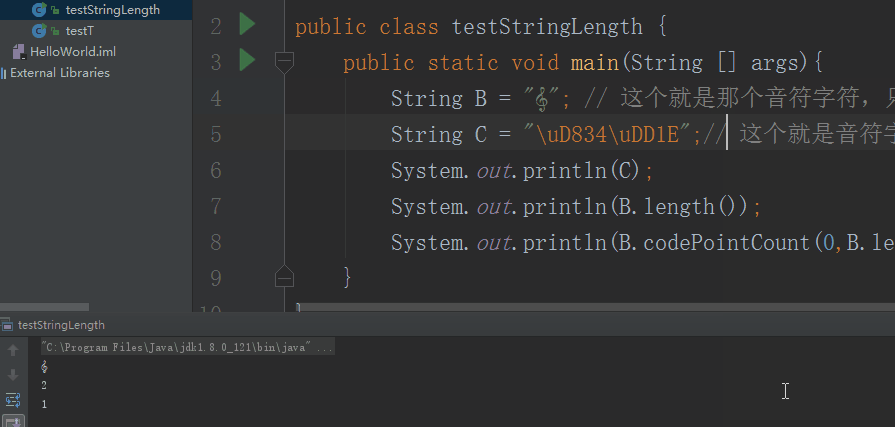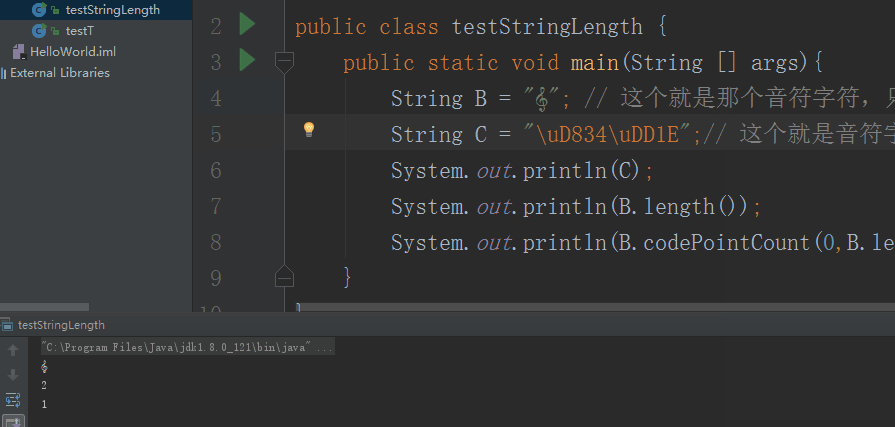
可以看到通过codePointCount()函数得知这个音乐字符是一个字符!

几个问题:
0.codePointCount是什么意思呢?
1.之前不是说音符字符是“U+1D11E”,为什么UTF-16是"\uD834\uDD1E",这俩之间如何转换?
2.前面说了UTF-16的代码单元,UTF-32和UTF-8的代码单元是多少呢?

一个一个解答:
第0个问题:
codePointCount其实就是代码点数的意思,也就是一个字符就对应一个代码点数。
比如刚才音符字符(没办法打出来),它的代码点是U+1D11E,但它的代理单元是U+D834和U+DD1E,如果令字符串str = "\u1D11E",机器识别的不是音符字符,而是一个代码点”/u1D11“和字符”E“,所以会得到它的代码点数是2,代码单元数也是2。
但如果令字符str = "\uD834\uDD1E",那么机器会识别它是2个代码单元代理,但是是1个代码点(那个音符字符),故而,length的结果是代码单元数量2,而codePointCount()的结果是代码点数量1.
第1个问题

上图是对应的转换规则:
- 首先 U+1D11E-U+10000 = U+0D11E
- 接着将U+0D11E转换为二进制:0000 1101 0001 0001 1110,前10位是0000 1101 00 后10位是01 0001 1110
- 接着套用模板:110110yyyyyyyyyy 110111xxxxxxxxxx
- U+0D11E的二进制依次从左到右填入进模板:110110 0000 1101 00 110111 01 0001 1110
- 然后将得到的二进制转换为16进制:d834dd1e,也就是你看到的utf-16编码了
第2个问题
- 同理,UTF-32 以 32 位一个单元,它只包含这一种单元就够了,它的一单元自然也就是四字节了。
- UTF-8 的 8 指的就是最小为 8 位一个单元,也即一字节为一个单元,UTF-8 可以包含一个单元,二个单元,三个单元及四个单元,对应即是一,二,三及四字节。

参考
- 表情包出自微博@黄小B
- https://blog.csdn.net/u012425381/article/details/38760179
- https://xiaogd.net/
- https://tool.oschina.net/hexconvert
- https://baike.baidu.com/item/Unicode/750500?fr=aladdin
本文首发于微信公众号:程序员乔戈里
如果是头条用户,可以在我的头条号程序员乔戈里后台回复 资源获取价值59998元的编程和考研资料
觉得文章不错的欢迎关注我的WX公众号:程序员乔戈里
我是BAT大厂后台开发工程师,,专注分享技术干货/编程资源/求职面试/成长感悟等,关注送5000G编程资源和自己整理的一份帮助不少人拿下java的offer的面经附答案,免费下载CSDN资源。
