原文链接:https://www.askmaclean.com/archives/new-compression-options-mongodb-30.html
MongoDB3.0对WiredTiger存储引擎引入了压缩功能。在本文中,我们将观察不同选项,并举例说明这个功能如何运行。由于情况因人而异,所以我们鼓励你测试自己的数据和应用程序。
为什么需要压缩?
每个人都知道存储很便宜对吧?

但是,有可能你添加数据的速度比存储价格下降的速度来得更快,你花费在存储上的净支出实际上正在上升。你的内部成本也可能需要包括管理等因素,因此它们的价格可能会比商品市场价格高出很多。换句话说,你仍然需要寻求新的方式以减少您对存储的需求。
磁盘存储的大小是一个需要考虑的因素,当然还有其他需要考虑的。磁盘I/ O延迟是由在旋转存储上寻道时间为主导。通过降低数据的大小,用更少的磁盘寻道检索一定量的数据是必要的,这样磁盘I / O吞吐量将得到改善。对于RAM而言,一些压缩格式可以不用解压在内存中的数据。在这样的情况下,更多的数据可以放在RAM中,从而提高了性能。
MongoDB的存储性能
还有两个关于存储的重要特性,影响空间在MongoDB中的使用:BSON和动态模式。
MongoDB存储数据在BSON,一种类似JSON文件的二进制编码(BSON支持其他数据类型,如日期,不同的数字类型,二进制类型)。 BSON能有效编码和解码,并且易于遍历。然而,BSON不压缩数据,所以有可能它的数据表示大于同等的JSON。
用户喜欢MongoDB的文档数据模型的一点是其动态schema。在大多数数据库中,模式(Schema)是在一个分类或系统表中集中进行描述和维护的。列名对所有行仅保存一次。这种方法对于空间是有效的,但它需要所有数据根据模式被构造。 MongoDB中目前还没有核心分类:每个文件是自述的。新字段可以被添加到一个文档,而不会影响其他文件,并且不用在核心分类中进行字段登记。
更大灵活性的代价是更大的应用空间。字段名在每个文档中被定义,在允许的情况下就使用较短的字段名。但是同样要注意不要太短 – 单字母字段名称或代码会使得字段名称很难理解和阅读,其数据也变得更难使用。
好在传统的模式不是有效利用空间的唯一方式。对于处理重复值比如字段名称,以及在文件中存储的大量数据,压缩也是很有效的方式。
没有万能的压缩方法
压缩很常见:图像(JPEG,GIF),音频(MP3),视频(MPEG),以及大多数Web服务器在使用gzip发送到浏览器之前,也会压缩网页。压缩算法已经存在了几十年,也有一些奖励创新的比赛。
压缩库依靠CPU和RAM来压缩和解压缩数据,而且每个都在压缩率,速度和资源利用率方面有不同的权衡。例如,一个当今最好的压缩库在文本方面可以压缩1GB的维基百科数据到124MB,相对于gzip的323MB,但它需要大约近3000倍的时间和30000倍的内存来这样做。根据您的数据和应用程序,某个库的使用可能会对于你的需求比别人更有效。
MongoDB3.0引入WiredTiger,支持压缩一个新的存储引擎。 WiredTiger使用页面管理磁盘I / O。每个页面都包含很多BSON文件。页面被写入磁盘时就被默认压缩,当在磁盘中被读入高速缓存时它们就被解压。
压缩的基本概念之一是重复值 – 确切的值以及形式 – 可以一次以压缩的格式被存储,减少了空间的总量。较大的数据单元倾向于更有效地压缩,因为有更多重复值。通过在页面级别压缩 – 通常称为数据块压缩 – WiredTiger可以更有效地压缩数据。
WiredTiger支持多种压缩库。你可以决定哪个选项是最适合你的集合水平。这是一个重要的选择,你的访问模式和数据可能在集合间大不相同。例如,如果你使用GridFS的存储较大的文件,如图片和视频,MongoDB自动把大文件分成许多较小的“块”,当需要的时候再重新组合。 GridFS的实施维护两个集合:fs.files,包含大文件的元数据和其相关的块;以及fs.chunks,包含大数据分成的255KB的块。对于图像和视频,压缩可能会有益于fs.files集合,但在fs.chunks的数据可能已经被压缩,因此它对于这个集合可能需要禁用压缩。
MongoDB3.0中的压缩选项
在MongoDB 3.0中,WiredTiger为集合提供三个压缩选项:
- 无压缩
- Snappy(默认启用) – 很不错的压缩,有效利用资源
- zlib(类似gzip) – 出色的压缩,但需要占用更多资源
有索引的两个压缩选项:
- 无压缩
- 前缀(默认启用) – 良好的压缩,资源的有效利用
你也许会好奇,为什么对索引压缩选项与集合的不同。前缀压缩是相当简单的 – 值的“前缀”是将数据集中重复数据删除。这对于某些数据集特别有效,如那些低基数的(例如,国家),或那些具有重复值的,如电话号码,社会安全码和地理坐标。它对复合索引特别有效,如第一列与第二列的所有唯一值重复。前缀索引还提供了一个非常重要的优势优于Snappy或zlib – 可以直接使用压缩索引进行查询操作。
当从磁盘中访问被压缩的集合数据,数据在高速缓存中被解压。通过前缀压缩,索引可以在RAM中保持被压缩的形式。我们往往看到使用前缀压缩得到的非常好的带索引的压缩,这意味着在大多数情况下,你可以容纳更多的索引在内存中而不牺牲读取的性能,并且对写的影响很小。压缩率会有因您的数据的基数以及是否使用复合索引而有显著的不同。
请记住哪些适用于MongoDB的3.0所有压缩选项:
- 随机数据不能压缩
- 二进制数据不能压缩(它可能已经被压缩)
- 文本压缩效果特别好
- 对于文件中的字段名压缩效果特别好(尤其对短字段名来说)
默认情况下,对WiredTiger存储引擎存储的集合和索引启用压缩。 为了在启动时明确设置副本的压缩,需要在YAML配置文件中的进行相应设置。使用命令行选项 –wiredTigerCollectionBlockCompressor。由于WiredTiger不是在MongoDB中3.0的默认存储引擎,你还需要指定 –storageEngine选择使用WiredTiger再利用这些压缩功能。
要指定压缩特定的集合,你需要使用db.createCollection() 命令中的并传入相应参数项来覆盖默认值。例如,使用zlib压缩库创建一个名为email的集合:
db.createCollection( "email", { storageEngine: {
wiredTiger: { configString: 'block_compressor=zlib' }}})
如何测量压缩
测量压缩的最好方法是使用和不使用启用压缩来分别装载数据,然后比较两个大小。db.stats()命令返回许多不同的存储数据,但两个与比较有关的测量点是存储大小和索引大小。值以字节为单位返回,但你可以通过传入1024*1024参数转换成MB:
> db.stats(1024*1024).dataSize + db.stats(1024*1024).indexSize 1406.9201011657715
这是我们在使用下面压缩方法时进行的测量方法。
在不同的数据集上测试压缩
让我们来看一些不同的数据集,看看一些压缩选项的执行。我们有四个数据库:
Enron
这是臭名昭著的Enron email corpus。它包括约50万的电子邮件。在邮件正文字段有大量的文本,一些元数据的基数很低,这意味着他们都可能会被压缩得很好。下面是一个例子(这里截断了电子邮件正文):
{
"_id" : ObjectId("4f16fc97d1e2d32371003e27"),
"body" : "",
"subFolder" : "notes_inbox",
"mailbox" : "bass-e",
"filename" : "450.",
"headers" : {
"X-cc" : "",
"From" : "[email protected]",
"Subject" : "Re: Plays and other information",
"X-Folder" : "\Eric_Bass_Dec2000\Notes Folders\Notes inbox",
"Content-Transfer-Encoding" : "7bit",
"X-bcc" : "",
"To" : "[email protected]",
"X-Origin" : "Bass-E",
"X-FileName" : "ebass.nsf",
"X-From" : "Michael Simmons",
"Date" : "Tue, 14 Nov 2000 08:22:00 -0800 (PST)",
"X-To" : "Eric Bass",
"Message-ID" : "<6884142.1075854677416.JavaMail.evans@thyme>",
"Content-Type" : "text/plain; charset=us-ascii",
"Mime-Version" : "1.0"
}
}
不同选项在Enron数据库的运行状态:

Flights
美国联邦航空管理局(FAA)提供了关于按时的航空公司服务的数据。每个航班被表示为一个文件。许多字段有低基数,所以我们觉得这个数据集会得到很好的压缩:
{
"_id" : ObjectId("53d81b734aaa3856391da1fb"),
"origin" : {
"airport_seq_id" : 1247802,
"name" : "JFK",
"wac" : 22,
"state_fips" : 36,
"airport_id" : 12478,
"state_abr" : "NY",
"city_name" : "New York, NY",
"city_market_id" : 31703,
"state_nm" : "New York"
},
"arr" : {
"delay_group" : 0,
"time" : ISODate("2014-01-01T12:38:00Z"),
"del15" : 0,
"delay" : 13,
"delay_new" : 13,
"time_blk" : "1200-1259"
},
"crs_arr_time" : ISODate("2014-01-01T12:25:00Z"),
"delays" : {
"dep" : 14,
"arr" : 13
},
"taxi_in" : 5,
"distance_group" : 10,
"fl_date" : ISODate("2014-01-01T00:00:00Z"),
"actual_elapsed_time" : 384,
"wheels_off" : ISODate("2014-01-01T09:34:00Z"),
"fl_num" : 1,
"div_airport_landings" : 0,
"diverted" : 0,
"wheels_on" : ISODate("2014-01-01T12:33:00Z"),
"crs_elapsed_time" : 385,
"dest" : {
"airport_seq_id" : 1289203,
"state_nm" : "California",
"wac" : 91,
"state_fips" : 6,
"airport_id" : 12892,
"state_abr" : "CA",
"city_name" : "Los Angeles, CA",
"city_market_id" : 32575
},
"crs_dep_time" : ISODate("2014-01-01T09:00:00Z"),
"cancelled" : 0,
"unique_carrier" : "AA",
"taxi_out" : 20,
"tail_num" : "N338AA",
"air_time" : 359,
"carrier" : "AA",
"airline_id" : 19805,
"dep" : {
"delay_group" : 0,
"time" : ISODate("2014-01-01T09:14:00Z"),
"del15" : 0,
"delay" : 14,
"delay_new" : 14,
"time_blk" : "0900-0959"
},
"distance" : 2475
}
不同选项在Flights数据库的运行状态:

MongoDB的配置数据库
这是MongoDB存储在配置数据库进行分片集群的元数据。该手册描述了该数据库的各种集合。下面是来自块集合的一个例子,它把每个块的文件存储于集群中:
{
"_id" : "mydb.foo-a_\"cat\"",
"lastmod" : Timestamp(1000, 3),
"lastmodEpoch" : ObjectId("5078407bd58b175c5c225fdc"),
"ns" : "mydb.foo",
"min" : {
"animal" : "cat"
},
"max" : {
"animal" : "dog"
},
"shard" : "shard0004"
}
不同选项在配置数据库的运行状态:

TPC-H
TPC-H是一款经典的用于测试关系分析的数据库管理系统的标杆。该模式已被修正为使用MongoDB的文档模型。下面是订单表中的例子,只有很多行项目的第一个在此订单显示:
{
"_id" : 1,
"cname" : "Customer#000036901",
"status" : "O",
"totalprice" : 173665.47,
"orderdate" : ISODate("1996-01-02T00:00:00Z"),
"comment" : "instructions sleep furiously among ",
"lineitems" : [
{
"lineitem" : 1,
"mfgr" : "Manufacturer#4",
"brand" : "Brand#44",
"type" : "PROMO BRUSHED NICKEL",
"container" : "JUMBO JAR",
"quantity" : 17,
"returnflag" : "N",
"linestatus" : "O",
"extprice" : 21168.23,
"discount" : 0.04,
"shipinstr" : "DELIVER IN PERSON",
"realPrice" : 20321.5008,
"shipmode" : "TRUCK",
"commitDate" : ISODate("1996-02-12T00:00:00Z"),
"shipDate" : ISODate("1996-03-13T00:00:00Z"),
"receiptDate" : ISODate("1996-03-22T00:00:00Z"),
"tax" : 0.02,
"size" : 9,
"nation" : "UNITED KINGDOM",
"region" : "EUROPE"
}
]
}
不同选项在TPC-H数据库的运行状态:

这是200K的数据库。这里有一个模拟使用了Java3.0驱动的Tweets:
{
"coordinates": null,
"created_at": "Fri April 25 16:02:46 +0000 2010",
"favorited": false,
"truncated": false,
"id_str": "",
"entities": {
"urls": [
{
"expanded_url": null,
"url": "http://mongodb.com",
"indices": [
69,
100
]
}
],
"hashtags": [ ],
"user_mentions": [
{
"name": "MongoDB",
"id_str": "",
"id": null,
"indices": [
25,
30
],
"screen_name": "MongoDB"
}
]
},
"in_reply_to_user_id_str": null,
"text": "Introducing the #Java 3.0 driver for #MongoDB http://buff.ly/1DmMTKu",
"contributors": null,
"id": null,
"retweet_count": 12,
"in_reply_to_status_id_str": null,
"geo": null,
"retweeted": true,
"in_reply_to_user_id": null,
"user": {
"profile_sidebar_border_color": "C0DEED",
"name": "MongoDB",
"profile_sidebar_fill_color": "DDEEF6",
"profile_background_tile": false,
"profile_image_url": "",
"location": "New York, NY",
"created_at": "Fri April 25 23:22:09 +0000 2008",
"id_str": "",
"follow_request_sent": false,
"profile_link_color": "",
"favourites_count": 1,
"url": "http://mongodb.com",
"contributors_enabled": false,
"utc_offset": -25200,
"id": null,
"profile_use_background_image": true,
"listed_count": null,
"protected": false,
"lang": "en",
"profile_text_color": "",
"followers_count": 159678,
"time_zone": "Eastern Time (US & Canada)",
"verified": false,
"geo_enabled": true,
"profile_background_color": "",
"notifications": false,
"description": "Community conversation around the MongoDB software. For official company news, follow @mongodbinc.",
"friends_count": ,
"profile_background_image_url": "",
"statuses_count": 7311,
"screen_name": "MongoDB",
"following": false,
"show_all_inline_media": false
},
"in_reply_to_screen_name": null,
"source": "web",
"place": null,
"in_reply_to_status_id": null
}
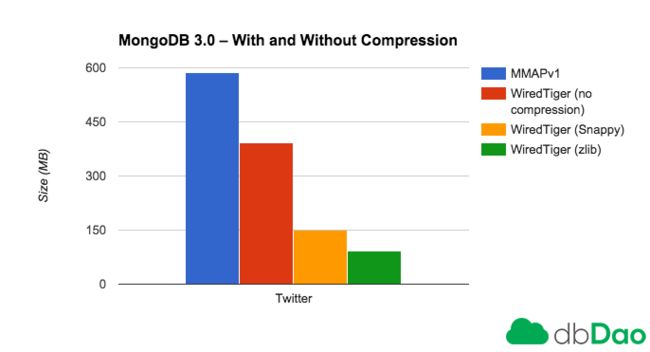
不同选项在Twitter数据库的运行状态:
比较压缩率
这些数据库大小不等, 这使得他们难以进行比较绝对的大小比较。我们可以通过比较每个选项所节省的存储空间来看他们的好处。要做到这一点,我们通过使用Sanppy和zlib在WiredTiger中的未压缩大小来比较每个数据库的大小。如上所述,我们增加storageSize和indexSize的值。

另一种描述压缩的好处的方式是未压缩尺寸与压缩后的大小的比例计算。这里是Snappy和zlib在五个databases.v的执行。

如何测试自己的数据
有两种简单的方法可用于测试你在MongoDB 3.0中的数据的压缩。
如果你已经升级到MongoDB 3.0,你可以简单地用在副本中增加一个新成员并在启动时指定使用WiredTiger存储引擎。当你在运行时,通过设置为0 votes来隐藏这个副本,这样就不会影响到你的部署。 这个副本集新成员将和已存的成员进行初始同步。初始同步完成后,你可以从你的副本集中删除这个WiredTiger副本,然后连接到之前单独副本来比较你的数据库大小。对于你要测试的每个压缩选项,您可以重复这一过程。
另一种选择是使用mongodump导出你的数据并用它将其还原到一个独立的MongoDB 3.0实例。默认情况下您的集合将使用Snappy的压缩选项,但你在运行mongorestore之前,先创建具有相应设置的集合来指定不同选项,或者用不同的压缩选项启动mongod。这种方法能够导出/恢复特定的数据库,集合,或集合的子集来执行测试。
对于语法设置压缩选项的例子,请参见“如何使用压缩”部分。
固定集合(capped collection)须知
固定集合在MMAP存储引擎的实现与WiredTiger(和RocksDB)非常不同。在MMAP,空间在创建时被分配用于固定集合,而对于WiredTiger和RocksDB,只有当数据被添加到固定集合时,空间才被分配。如果你有很多空的或大部分空的固定集合,在不同的存储引擎之间的比较可能会因为这个原因出现误导。
Comment