kaggle自行车租赁预测
1.数据
为自行车租赁系统提供的数据,提供数据为2年内华盛顿按小时记录的自行车租赁数据。数据来源:
Kaggle自行车租赁预测比赛数据
字段介绍:
datetime 日期(年月日时分秒)
season 季节。1为春季,2为夏季,3为秋季,4为冬季
hodliday 是否为假期。1代表是,0代表不是
workingday 是否为工作日。1代表是,0代表不是。
weather 天气。1天气晴朗或多云,2有雾和云/峰等,3小雪/小雨,闪电及多云。4大雨/冰雹/闪电和大雾/大雪。
temp 摄氏温度
atemp 人们感觉的温度
humidity 湿度
windspeed 风速
casual 没有注册的预定自行车的人数
registered 注册了的预定自行车的人数
count 总租车人数
#最后三个字段3个不属于特征2.数据预处理
通过pandas导入数据
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline #pandas数据读入 df_train = pd.read_csv("kaggle_bike_competition_train.csv",header=0)瞅一眼看看数据格式,这里打印前5行:
df_train.head(5)
查看一下数据有没有缺省值
print(df_train.shape) # 看看有没有缺省值 print(df_train.count()) """ (10886, 12) datetime 10886 season 10886 holiday 10886 workingday 10886 weather 10886 temp 10886 atemp 10886 humidity 10886 windspeed 10886 casual 10886 registered 10886 count 10886 dtype: int64 """把月,日和小时单独拎出来放到df_train中:
df_train['month'] = pd.DatetimeIndex(df_train.datetime).month df_train['day'] = pd.DatetimeIndex(df_train.datetime).dayofweek df_train['hour'] = pd.DatetimeIndex(df_train.datetime).hour将不属于特征的字段去掉,这里是datetime,casual,registered
#datetime 通过上一步拆分月,日,时更加形象 #casual,registered为目标预测数据 df_train = df_train.drop(['datetime','casual','registered'],axis=1)再查看数据
df_train.head(5)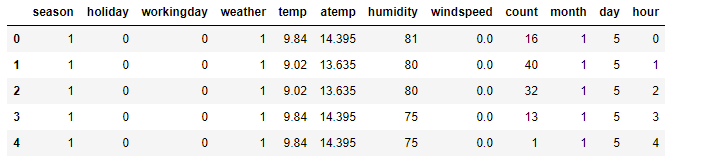
- 将数据分为2个部分:
- 1.df_train_target:目标,也就是count字段
- 2.df_train_data:用于产生特征的数据
3.特征工程
下面的过程会让你看到,其实应用机器学习算法的过程,多半是在调参,各种不同的参数会带来不同的结果(比如正则化系数,比如决策树类的算法的树深和颗树,比如距离判定准则等等等)
我们使用交叉验证的方式(交叉验证集约占全部数据的20%)来看看模型效果,使用以上三个模型,都跑3趟,看看它们平均值评分结果:
- 向量回归Suport Vector Regression
- 岭回归Ridge Regression
- 随机森林回归Random Forest Regressor
from sklearn import linear_model#岭回归 from sklearn import model_selection from sklearn import svm#向量回归 from sklearn.ensemble import RandomForestRegressor#随机森林回归包 from sklearn.model_selection import learning_curve from sklearn.model_selection import GridSearchCV from sklearn.metrics import explained_variance_score # 切分数据(训练集和测试集) cv = model_selection.ShuffleSplit(n_splits=3,test_size=0.2,random_state=0) cv_split = cv.split(df_train_data) print("岭回归") for train,test in cv_split: svc = linear_model.Ridge().fit(df_train_data[train], df_train_target[train]) print("train score: {0:.3f}, test score: {1:.3f}\n".format( svc.score(df_train_data[train], df_train_target[train]), svc.score(df_train_data[test], df_train_target[test]))) print("支持向量回归/SVR(kernel='rbf',C=10,gamma=.001)") for train,test in cv.split(df_train_data): svc = svm.SVR(kernel ='rbf', C = 10, gamma = .001).fit(df_train_data[train], df_train_target[train]) print("train score: {0:.3f}, test score: {1:.3f}\n".format( svc.score(df_train_data[train], df_train_target[train]), svc.score(df_train_data[test], df_train_target[test]))) print("随机森林回归/Random Forest(n_estimators = 100)") for train, test in cv.split(df_train_data): svc = RandomForestRegressor(n_estimators = 100).fit(df_train_data[train], df_train_target[train]) print("train score: {0:.3f}, test score: {1:.3f}\n".format( svc.score(df_train_data[train], df_train_target[train]), svc.score(df_train_data[test], df_train_target[test])))- 结果展示:
岭回归 train score: 0.339, test score: 0.332 train score: 0.330, test score: 0.370 train score: 0.342, test score: 0.320 支持向量回归/SVR(kernel='rbf',C=10,gamma=.001) train score: 0.417, test score: 0.408 train score: 0.406, test score: 0.452 train score: 0.419, test score: 0.390 随机森林回归/Random Forest(n_estimators = 100) train score: 0.982, test score: 0.864 train score: 0.982, test score: 0.880 train score: 0.981, test score: 0.869
4.模型参数调整
不用自己折腾,通过GridSearch,帮我们调节最佳参数
X = df_train_data y = df_train_target X_train, X_test, y_train, y_test = model_selection.train_test_split( X, y, test_size=0.2, random_state=0) tuned_parameters = [{'n_estimators':[10,100,500]}] scores = ['r2'] for score in scores: print(score) clf = GridSearchCV(RandomForestRegressor(), tuned_parameters, cv=5, scoring=score) clf.fit(X_train, y_train) #best_estimator_ returns the best estimator chosen by the search print(clf.best_estimator_) print("得分分别是:") #grid_scores_的返回值: # * a dict of parameter settings # * the mean score over the cross-validation folds # * the list of scores for each fold for mean_score in clf.cv_results_["mean_test_score"]: print("%0.3f" % (mean_score,)) #得到结果需要花费些时间- 结果展示
r2 RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=500, n_jobs=None, oob_score=False, random_state=None, verbose=0, warm_start=False) 得分分别是: 0.846 0.861 0.863可视化展示,看看模型学习曲线是否过拟合或欠拟合
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)): plt.figure() plt.title(title) if ylim is not None: plt.ylim(*ylim) plt.xlabel("Training examples") plt.ylabel("Score") train_sizes, train_scores, test_scores = learning_curve( estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes) train_scores_mean = np.mean(train_scores, axis=1) train_scores_std = np.std(train_scores, axis=1) test_scores_mean = np.mean(test_scores, axis=1) test_scores_std = np.std(test_scores, axis=1) plt.grid() plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r") plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g") plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score") plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score") plt.legend(loc="best") return plt title = "Learning Curves (Random Forest, n_estimators = 100)" cv = model_selection.ShuffleSplit(n_splits=3,test_size=0.2,random_state=0) cv_split = cv.split(df_train_data) estimator = RandomForestRegressor(n_estimators = 100) plot_learning_curve(estimator, title, X, y, (0.0, 1.01), cv=cv_split, n_jobs=4) plt.show()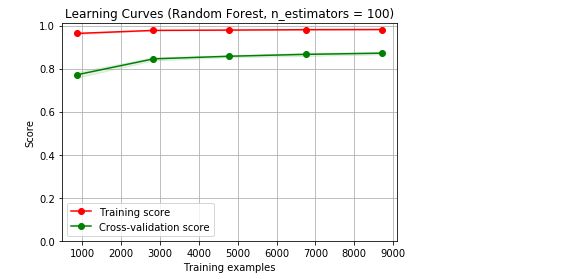
随机森林算法学习能力比较强,由图可以发现,训练集和测试机分差较大,过拟合很明显,尝试缓解过拟合(未必成功):
print("随机森林回归/Random Forest(n_estimators=200, max_features=0.6, max_depth=15)") cv = model_selection.ShuffleSplit(n_splits=6,test_size=0.2,random_state=0) for train, test in cv.split(df_train_data): svc = RandomForestRegressor(n_estimators = 200, max_features=0.6, max_depth=15).fit(df_train_data[train], df_train_target[train]) print("train score: {0:.3f}, test score: {1:.3f}\n".format( svc.score(df_train_data[train], df_train_target[train]), svc.score(df_train_data[test], df_train_target[test])))- 显示结果
随机森林回归/Random Forest(n_estimators=200, max_features=0.6, max_depth=15) train score: 0.965, test score: 0.868 train score: 0.966, test score: 0.885 train score: 0.966, test score: 0.873 train score: 0.965, test score: 0.876 train score: 0.966, test score: 0.869 train score: 0.966, test score: 0.872
5.特征项分析:
1.温度对租车影响:
df_train_origin.groupby('temp').mean().plot(y='count', marker='o')
plt.show()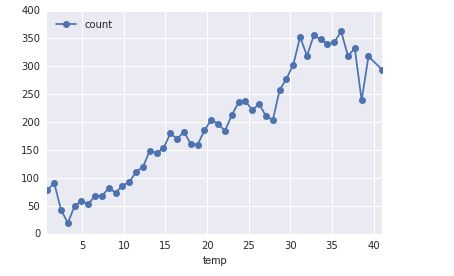
2.风速对租车影响:
df_train_origin.groupby('windspeed').mean().plot(y='count', marker='o')
plt.show()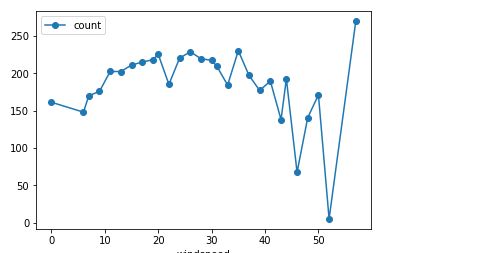
3.湿度对租车影响
# 湿度
df_train_origin.groupby('humidity').mean().plot(y='count', marker='o')
plt.show()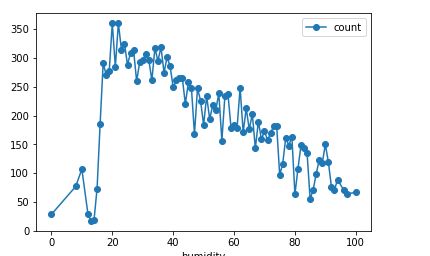
4.温度与湿度变化
df_train_origin.plot(x='temp', y='humidity', kind='scatter')
plt.show()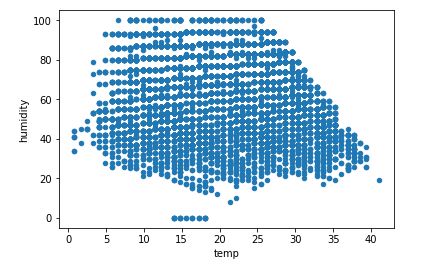
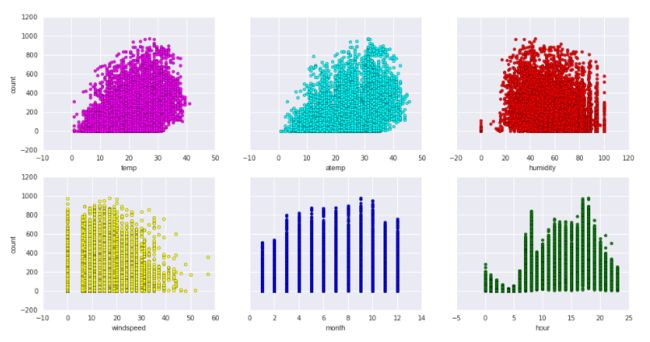
# scatter一下各个维度
fig, axs = plt.subplots(2, 3, sharey=True)
df_train_origin.plot(kind='scatter', x='temp', y='count', ax=axs[0, 0], figsize=(16, 8), color='magenta')
df_train_origin.plot(kind='scatter', x='atemp', y='count', ax=axs[0, 1], color='cyan')
df_train_origin.plot(kind='scatter', x='humidity', y='count', ax=axs[0, 2], color='red')
df_train_origin.plot(kind='scatter', x='windspeed', y='count', ax=axs[1, 0], color='yellow')
df_train_origin.plot(kind='scatter', x='month', y='count', ax=axs[1, 1], color='blue')
df_train_origin.plot(kind='scatter', x='hour', y='count', ax=axs[1, 2], color='green')