Stream 流
初识Stream流
简单认识一下Stream:Stream类中的官方介绍:
/**
* A sequence of elements supporting sequential and parallel aggregate
* operations. The following example illustrates an aggregate operation using
* {@link Stream} and {@link IntStream}:
*
* {@code
* int sum = widgets.stream()
* .filter(w -> w.getColor() == RED)
* .mapToInt(w -> w.getWeight())
* .sum();
* }
* In this example, {@code widgets} is a {@code Collection}. We create
* a stream of {@code Widget} objects via {@link Collection#stream Collection.stream()},
* filter it to produce a stream containing only the red widgets, and then
* transform it into a stream of {@code int} values representing the weight of
* each red widget. Then this stream is summed to produce a total weight.
*
*/
看这么一个案例,类似于js中的链式操作。就明白了大概流是什么样子的。类似于 Linux的 pipeline
流包含三部分组成:
- 源
- 零个或多个中间操作
- 终止操作
流操作的分类:
- 惰性求值
- 及早求值
stream.xxx().yyy().zzz().count();中间操作:惰性求值。只有在count()被调用的时候,中间的操作才会进行求值。
及早求值,count()方法调用的时候立刻求值,这就叫做及早求值。
流中的及早求值只会有一个。
生成流的三种方式
public class StreamTest {
public static void main(String[] args) {
//本章才正式的开始对流进行讲解。
//第一种方式,通过of方法
Stream stream1 = Stream.of("hello","world");
//第二种方式,通过数组方式
String[] strings = new String[]{"hello","world"};
Stream stream2 = Arrays.stream(strings);
Stream stream3 = Stream.of(strings); //of的底层就是 通过Arrays.stream()来实现的.
//第三种方式,通过集合.stream
List list = Arrays.asList("hello", "world");
list.stream();
}
} 流怎么用(入门使用)
用法一:
public class streamTest2 {
public static void main(String[] args) {
//Intstream 怎么用
IntStream.of(5, 6, 7).forEach(System.out::println);
System.out.println("----");
IntStream.range(3, 8).forEach(System.out::println);
System.out.println("----");
IntStream.rangeClosed(3, 8).forEach(System.out::println);
System.out.println("----");
}
}public class streamTest3 {
public static void main(String[] args) {
//List类型,int的值, 对每一个元素*2,然后加起来,得到结果
List list = Arrays.asList(1, 2, 3, 4, 5, 6);
//以前的写法
// int i=0;
// for (Integer i : list) {
// sum += 2;
// }
// sum...
//stream的写法,一行
System.out.println(list.stream().map(integer -> integer*2).reduce(0,Integer::sum));
//reduce方法,map()方法的调用会在下面进行详解.
//实现简单,语义更明确
}
} reduce(),终止操作,及早求值.
深入stream流
函数式编程,最根本的一点:方法传递的是行为.以前传递的都是数据.
- Collection提供了新的stream()方法
- **流不存储值,通过管道的方式获取值
- 本质是函数式的,对流的操作会生成一个结果,不过并不会修改底层的数据源,集合可以作为流的底层数据源
- 延迟查找,很多流操作(过滤,映射,排序等)都可以延迟实现(lazy)
看这个Example:
public class streamTest4 {
public static void main(String[] args) {
Stream stream = Stream.of("hello", "world", "hello world");
//lambda写法
//stream.toArray(length -> new String[length]);
//方法引用的写法 (构造方法引用)
String[] stringArray = stream.toArray(String[]::new);
Arrays.asList(stringArray).forEach(System.out::println);
}
} 已知流,转List
//已知流,转List
Stream stream = Stream.of("hello", "world", "hello world");
List collect = stream.collect(Collectors.toList());
collect.forEach(System.out::println); collect()方法详解 - Collectors里面也是通过collect(三个参数)这个方法来实现的
/**
* 第一个参数介绍
* Performs a mutable
* reduction operation on the elements of this stream. A mutable
* reduction is one in which the reduced value is a mutable result container,
* such as an {@code ArrayList}, and elements are incorporated by updating
* the state of the result rather than by replacing the result. This
* produces a result equivalent to: 第二个参数的介绍
* {@code
* R result = supplier.get();
* for (T element : this stream)
* accumulator.accept(result, element);
* return result;
* }
* 被并行化. 流带来的好处.
* Like {@link #reduce(Object, BinaryOperator)}, {@code collect} operations
* can be parallelized without requiring additional synchronization.
* 这是一个终止操作.
*
This is a terminal
* operation.
* 方法签名是非常适合于使用方法引用的方式.就是最下面举例的Example
* @apiNote There are many existing classes in the JDK whose signatures are
* well-suited for use with method references as arguments to {@code collect()}.
* For example, the following will accumulate strings into an {@code ArrayList}:
*
{@code
* List asList = stringStream.collect(ArrayList::new, ArrayList::add,
* ArrayList::addAll);
* }
* 扩展功能:字符串实现拼接的操作
* The following will take a stream of strings and concatenates them into a
* single string:
*
{@code
* String concat = stringStream.collect(StringBuilder::new, StringBuilder::append,
* StringBuilder::append)
* .toString();
* }
*
* @param type of the result
第一个参数:结果容器,如LinkList
* @param supplier a function that creates a new result container. For a
* parallel execution, this function may be called
* multiple times and must return a fresh value each time.
第二个参数:关联性的,不冲突的,无状态的,用于合并. item->list
* @param accumulator an associative,
* non-interfering,
* stateless
* function for incorporating an additional element into a result
第三个参数:用于融合,将上次遍历得到的集合融合到最终的结果集中.
* @param combiner an associative,
* non-interfering,
* stateless
* function for combining two values, which must be
* compatible with the accumulator function
* @return the result of the reduction
*/
R collect(Supplier supplier,
BiConsumer accumulator,
BiConsumer combiner); 通过源码解释:我们得知实现流转List的底层就是通过这个三参数的collect方法来实现的,我们逐一来对这三个参数进行了解.
1.参数1:supplier,类型Supplier的函数式接口. 功能:用来提供一个初步的List容器
2.参数2: accumulator,类型BiConsumer的函数式接口. 功能:累加器,将流中的一个个元素累加进集合中.
3.参数3:combiner,类型为BiConsumer的函数式接口. 功能:组合器,将上一次遍历得到一个的集合进行融合到最终的List中.
自行阅读上面的Collector的文档.我说的这些内容都在里面有所体现.
通过上述的了解,我们可以通过三参数的collect()方法,来自己实现一个底层stream转换List的实现,如下:
//功能描述:已知流,转List
Stream stream = Stream.of("hello", "world", "hello world");
List collect = stream.collect(Collectors.toList());
collect.forEach(System.out::println);
//使用collect(三个参数)的底层方法来实现这个操作. 因为这个三参的collect()方法就是这个操作的底层.
List list = stream.collect(() -> new ArrayList(),(theList,item)->theList.add(item),(theList1,theList2)->theList1.addAll(theList2));
//通过方法引用优化后的代码如下:
//优化后的代码:
List list1 = stream.collect(LinkedList::new,LinkedList::add,LinkedList::addAll); 上述源码注释中还提供了 字符串拼接的操作
* 扩展功能:字符串实现拼接的操作
* The following will take a stream of strings and concatenates them into a
* single string:
*
{@code
* String concat = stringStream.collect(StringBuilder::new, StringBuilder::append,
* StringBuilder::append)
* .toString();
* }
*流的其他使用
//使用 Collectors.toCollection()方法来实现 流转List
Stream stream = Stream.of("hello", "world", "hello world");
// ArrayList list = stream.collect(Collectors.toCollection(ArrayList::new));
// list.forEach(System.out::println);
//使用 Collectors.toCollection()方法来实现 流转Set
Set list = stream.collect(Collectors.toCollection(TreeSet::new));
list.forEach(System.out::println);
//使用 方法来实现,流转String字符串
stream.collect(Collectors.joining()); 以后开发的时候,要多考虑,List,Set,这些转换是否可以使用JAVA8提供的这些stream来实现.用到实际开发中.
再思考
public class StreamTest5 {
public static void main(String[] args) {
//集合,全部转换大写,然后输出.
List list = Arrays.asList("hello", "world", "hello world");
//要考虑能不能用函数式接口,lambda表达式的技能?显然是可以呢
//这是不是映射? 先要要用map. 给定一个参数,返回一个结果.
//java8提供这些接口,就是为了方便开发者.合理的应用.
list.stream().map(String::toUpperCase).collect(Collectors.toList()).forEach(System.out::println);
//求出每个数字的平方,然后打印出来
List list1 = Arrays.asList(1, 2, 3, 4, 5);
list1.stream().map(item -> item * item).collect(Collectors.toList()).forEach(System.out::println);
}
} //要考虑能不能用函数式接口,lambda表达式的技能?显然是可以呢
//这是不是映射? 先要要用map. 给定一个参数,返回一个结果.
//java8提供这些接口,就是为了方便开发者.合理的应用.flatMap()方法:扁平化映射
/**
* Returns a stream consisting of the results of replacing each element of
* this stream with the contents of a mapped stream produced by applying
* the provided mapping function to each element. Each mapped stream is
* {@link java.util.stream.BaseStream#close() closed} after its contents
* have been placed into this stream. (If a mapped stream is {@code null}
* an empty stream is used, instead.)
*
* This is an intermediate
* operation.
*
* @apiNote
* The {@code flatMap()} operation has the effect of applying a one-to-many
* transformation to the elements of the stream, and then flattening the
* resulting elements into a new stream.
*
*
Examples.
*
*
If {@code orders} is a stream of purchase orders, and each purchase
* order contains a collection of line items, then the following produces a
* stream containing all the line items in all the orders:
*
{@code
* orders.flatMap(order -> order.getLineItems().stream())...
* }
*
* If {@code path} is the path to a file, then the following produces a
* stream of the {@code words} contained in that file:
*
{@code
* Stream lines = Files.lines(path, StandardCharsets.UTF_8);
* Stream words = lines.flatMap(line -> Stream.of(line.split(" +")));
* }
* The {@code mapper} function passed to {@code flatMap} splits a line,
* using a simple regular expression, into an array of words, and then
* creates a stream of words from that array.
*
* @param The element type of the new stream
* @param mapper a non-interfering,
* stateless
* function to apply to each element which produces a stream
* of new values
* @return the new stream
*/
Stream flatMap(Function> mapper);
和map很像,但是完全不同.否则就不会存在这个方法了.
扁平化的map;
1.map中映射的时候, 一个集合有三个List,每个List又有不同的值.映射完之后,模块还在
2.flatMap中映射的时候,一个集合有三个List, 打平的去给融合的到一个list中.
实例Example:
//每一个元素都乘方,然后将数据作为一个整体,输出. 当做一个集合. 就要用flatmap()
Stream> listStream = Stream.of(Arrays.asList(1), Arrays.asList(2, 3), Arrays.asList(4, 5, 6));
listStream.flatMap(theList->theList.stream()).map(integer -> integer*integer).forEach(System.out::println); Stream类中的其他方法介绍
- generate()
/**
* Returns an infinite sequential unordered stream where each element is
* generated by the provided {@code Supplier}. This is suitable for
* generating constant streams, streams of random elements, etc.
*
* @param the type of stream elements
* @param s the {@code Supplier} of generated elements
* @return a new infinite sequential unordered {@code Stream}
*/
public static Stream generate(Supplier s) {
Objects.requireNonNull(s);
return StreamSupport.stream(
new StreamSpliterators.InfiniteSupplyingSpliterator.OfRef<>(Long.MAX_VALUE, s), false);
} 如何使用?如下Example:
public class StreamTest6 {
public static void main(String[] args) {
Stream generate = Stream.generate(UUID.randomUUID()::toString);
System.out.println(generate.findFirst());
}
} Optional findFirst(); 为什么这个findFirst()方法会返回一个Optional?
因为Optional,就是为了规避NPE的问题.
所以此处需要使用Optional.ifPresent(),这才是Optional类的正确使用方法.应该修改为:
public class StreamTest6 {
public static void main(String[] args) {
Stream generate = Stream.generate(UUID.randomUUID()::toString);
generate.findFirst().ifPresent(System.out::println);
}
} - iterate()
public static Stream iterate(final T seed, final UnaryOperator f) {
Objects.requireNonNull(f);
final Iterator iterator = new Iterator() {
@SuppressWarnings("unchecked")
T t = (T) Streams.NONE;
@Override
public boolean hasNext() {
return true;
}
@Override
public T next() {
return t = (t == Streams.NONE) ? seed : f.apply(t);
}
};
return StreamSupport.stream(Spliterators.spliteratorUnknownSize(
iterator,
Spliterator.ORDERED | Spliterator.IMMUTABLE), false);
} 如何使用?
package com.dawa.jdk8.stream;
import java.util.UUID;
import java.util.stream.Stream;
public class StreamTest6 {
public static void main(String[] args) {
Stream generate = Stream.generate(UUID.randomUUID()::toString);
generate.findFirst().ifPresent(System.out::println);
//如果不加限制,iterate 会变成一个无限流.
//Stream.iterate(1, integer -> integer + 2).forEach(System.out::println);
//所以在使用的时候一定不要单独使用.
//要搭配limit()方法,一个中间操作,使用.
Stream.iterate(1, integer -> integer + 2).limit(6).forEach(System.out::println);
}
}
注意: //如果不加限制,iterate 会变成一个无限流.
//所以在使用的时候一定不要单独使用.
//要搭配limit()方法,一个中间操作,使用.
找出(1,3,5,7,9)流中大于2的元素,然后将每个元素乘以2,然后忽略流中的前两个元素,然后再取出流的前两个元素,最后求出流中元素的总和.
//找出(1,3,5,7,9)流中大于2的元素,然后将每个元素乘以2,然后忽略流中的前两个元素,然后再取出流的前两个元素,最后求出流中元素的总和.
// Stream stream = Stream.of(1, 3, 5, 7, 9);
Stream stream = Stream.iterate(1, integer -> integer + 2).limit(6);//通过iterate方法来获取值
System.out.println(stream.filter(integer -> integer > 2).mapToInt(integer -> integer * 2).skip(2).limit(2).sum());
//用到的方法. map,mapToint,skip,limit. ...skip() 跳过
...limit() 截取
...map().mapToInt(),mapToDouble().... 映射
mapToInt... 避免自动装箱和自动拆箱.(避免性能损耗).
...sum(),min(),max(). 最大,最小,求和等等
sum()返回值类型是int.
min().max(),返回值类型是:OptionalInt.
为什么呢?Optional类,因为使用与否,本质是取决于,这个值可不可能为空.
summaryStatistics():小结,总结.流中的数据的简单统计.
如:一个小结对象:IntSummaryStatistics{count=2, sum=32, min=14, average=16.000000, max=18}
这个类提供了各样的方法.
getCount getSum getMin getMax getAverage toString
上面的案例里面,已经使用了Stream类中的大量的方法.如有需要,自行查询官方源码.
注意:在对流进行中间操作的时候,会返回一个全新的流.直到进行一个终止操作的时候,才会得到最终的结果.
关于流被关闭的问题.
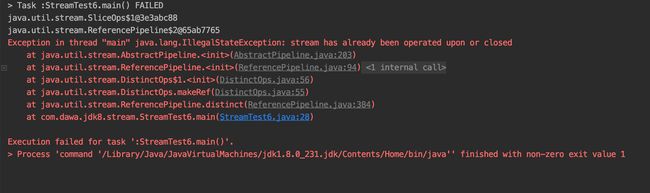
刚才无意之间,在操作的时候,抛出来一个这样的异常,提示流已经被关闭.
复盘一下代码:
Stream stream = Stream.iterate(1, integer -> integer + 2).limit(6);
System.out.println(stream);
System.out.println(stream.filter(integer -> integer > 2));
System.out.println(stream.distinct()); 流的特点
- 一旦被操作了.就会自动关闭流.
- 同一个流不能被重复操作.
- 流关闭了就不能继续操作了.
- 每一次中间操作都会返回一个新的操作流对象.
如何规避?
先生成一个流,操作完之后,再生成一个流.
紧接着去操作新生成的流.
Streamstream = Stream.iterate(1, integer -> integer + 2).limit(6);//通过iterate方法来获取值 System.out.println(stream); Stream stream1 = stream.filter(integer -> integer > 2); System.out.println(stream1); Stream stream2 = stream1.distinct(); System.out.println(stream2);
关于中间操作和终止操作之间的本质区别
Example:
public class StreamTest7 {
public static void main(String[] args) {
List list = Arrays.asList("hello", "world", "hello world");
//首字母大写,其他的小写,然后打印输出.
list.stream().map(item -> item.substring(0, 1).toUpperCase() + item.substring(1)).forEach(System.out::println);
//另外的操作
list.stream().map(item -> {
String result = item.substring(0, 1).toUpperCase() + item.substring(1);
System.out.println("test");
return result;
});//运行之后没有值
//另外的操作
list.stream().map(item -> {
String result = item.substring(0, 1).toUpperCase() + item.substring(1);
System.out.println("test");
return result;
}).forEach(System.out::println);//运行之后能够执行.
//原因:中间操作,如果没有终止操作,是不会自己执行的,是lazy类型的.是惰性求值的.
}
} 原因:中间操作,如果没有终止操作,是不会自己执行的,是lazy类型的.是惰性求值的.
再考虑一下效率问题.
也许可能会认为,多次中间操作,会多次循环,会降低效率.
其实只执行了一次.并不会影响效率.
会有一个容器,把所有的中间操作放在一起.一次执行.并不会有冗余操作.
如何区分中间操作和终止操作
中间操作都会返回一个Stream对象,比如说返回Stream ,...等
再看另外一个操作:关于中间操作和终止操作的影响
public class StreamTest8 {
public static void main(String[] args) {
IntStream.iterate(0, i -> (i + 1) % 2).distinct().limit(6).forEach(System.out::println);
}
}上述代码跑起来之后是不会自动终止的.
应该修改为:
public class StreamTest8 {
public static void main(String[] args) {
IntStream.iterate(0, i -> (i + 1) % 2).limit(6).distinct().forEach(System.out::println);
}
}这个原因就是因为中间操作和终止操作的影响.
如果先执行limit,就是一个终止操作.然后再消除重复一次,程序就会终止.
如果先执行消除重复操作,就是第一种情况,返回一个流,再截取6个,流并没有关闭.
Stream底层深入
- 和迭代器又不同的是,Stream可以并行化操作,迭代器只能命令式地,串行化操作
- 当使用串行方式去遍历时,每个item读完后再读下一个item.
- 使用并行去遍历时,数据会被分成多个段,其中每个都在不同的线程中去处理,然后将结果一起输出
- Stream流的并行操作依赖于JAVA7中引入的Fork/Join框架.
流的本质三个主要操作:源->中间操作->中间操作->...->终止操作
这里我们借助一个SQL来进行参照学习
select name from student where age>20 and address='beijing' order by age desc;描述性的语言
通过stream把这个SQL描述出来
student.stream()
.filter(student->student.getAge>20)
.filter(student->student.getAddress()
.equals("beijing")
.sorted(...)
.forEach(student->System.out.println(student.getName()));
//这个描述和上面的SQL其实是等价的.你只是给DB发送了一个指令,而没有所怎么去找.你只是给出了一个描述,然后根据降序之类的规则去进行筛选.对于整个过程,你完全没有告诉底层去怎么实现.
SQL是这样,Stream也是这样.只是描述性的语言.
这种方式就叫做内部迭代.
内部迭代
外部迭代(之前的方式)
不是描述性的处理方式,完全基于老版本的实现方式.和描述性语言相比,这个可读性太差.
都是串行化的操作,不能并行化
for(int i=0;i20&&student.getAddress().equals("beijing")){
list.add(student);
}
}
//然后进行排序
Collection.sort(list,Comparator()...);
//然后再去寻找需要的东西
for(Student student:list){
System.out.println(student.getName);
} 内部迭代(描述性语言)
新人也是能看懂的吧.
student.stream()
.filter(student->student.getAge>20)
.filter(student->student.getAddress()
.equals("beijing")
.sorted(...)
.forEach(student->System.out.println(student.getName()));Stream的出现和集合是密不可分的.
- 可以执行并行化的操作.
- 底层执行的时候,不是一个条件一个条件的去循环遍历的
内部迭代和外部迭代最本质的区别
- 耦合度
- 底层处理方式
- 并行和串行化的不同
总结
- 集合关注的是数据与数据存储本身;
- 流关注的则是对数据的计算;
- 流与迭代器类似的一点是:流是无法重复使用和消费的;
- 底层使用:fork/join 方法,分解大任务为小任务去执行.
最需要注意的
流的执行原理一定不是一个方法一个方法的执行循环遍历的.
并行流的使用(parallelStream)
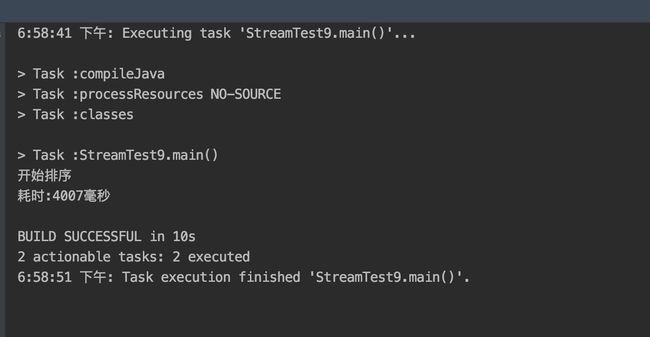
串行流(stream())和并行流(parallelStream())的执行效率判断.
- 串行流
package com.dawa.jdk8.stream;
import java.util.ArrayList;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
public class StreamTest9 {
public static void main(String[] args) {
ArrayList运行结果: 串行耗时:4.0秒
- 并行流
public class StreamTest9 {
public static void main(String[] args) {
ArrayList运行结果:并行耗时:1.1秒

并行和串行 - 时间成本相差:3-5倍.
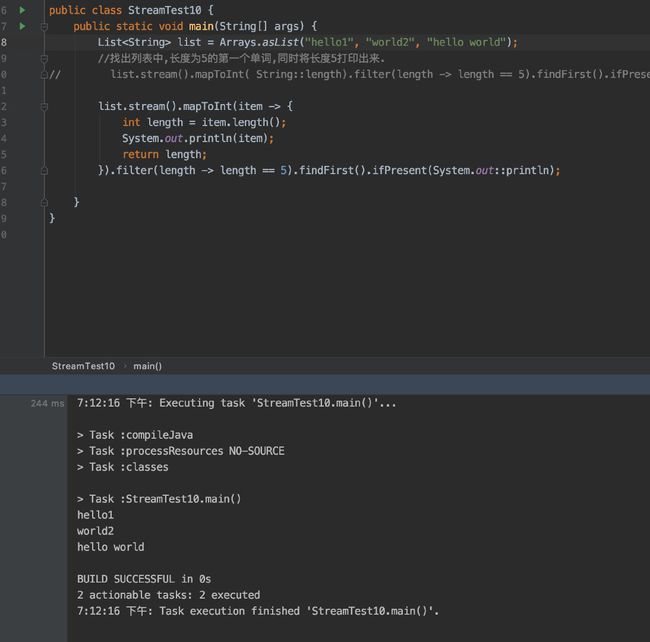
短路
public class StreamTest10 {
public static void main(String[] args) {
List list = Arrays.asList("hello", "world", "hello world");
//找出列表中,长度为5的第一个单词,同时将长度5打印出来.
// list.stream().mapToInt( String::length).filter(length -> length == 5).findFirst().ifPresent(System.out::println);
list.stream().mapToInt(item -> {
int length = item.length();
System.out.println(item);
return length;
}).filter(length -> length == 5).findFirst().ifPresent(System.out::println);
}
} 结果集:

为什么打印的时候只打印了1个?
原因:容器里面存放的是对每一个容器的操作.
当对流进行迭代,处理的时候,会拿着容器的操作,会逐个的运用到值上.这
如果不满足过滤规则,则还会发生短路运算操作.这是原因之二.只要找到符合条件的,后面就都不会运行.
如:没有满足的规则,则会进行全部执行完.所以就会出现如下结果:
案例:找出集合中所有的单词,并去重.(flatMap方法的应用)
public class StreamTest11 {
public static void main(String[] args) {
//找出集合中所有的单词,并去重.
List list = Arrays.asList("hello world", "hello welcome", "hello", "hello world hello", "hello world welcome");
//要输出: hello world welcome.
// list.stream().map(item -> item.split(" ")).distinct().collect(Collectors.toList()); //不对
List collect = list.stream().map(item -> item.split(" ")).flatMap(Arrays::stream).distinct().collect(Collectors.toList());
collect.forEach(System.out::println);
}
} 案例:将两个集合组合起来, 打招呼-人名(flatMap的应用)
public class StreamTest12 {
public static void main(String[] args) {
//将两个集合组合起来, 打招呼-人名
List list1 = Arrays.asList("Hi", "Hello", "你好");
List list2 = Arrays.asList("zhangsan", "lisi", "wangwu", "zhaoliu");
// list1.stream().map(item->item.concat(list2.stream().map()))
List collect = list1.stream().flatMap(item -> list2.stream().map(item2 ->item+ " " + item2)).collect(Collectors.toList());
collect.forEach(System.out::println);
}
} 分组和分区
如SQL中的group by.
select * from studeny group by name;Result:Map
传统的实现思路:
- 循环列表
- 取出学生的名字
- 检查map中是否存在该名字,不存在则直接添加到该map;存在则将map中的List对象取出来,然后将该Student对象添加到List中.
- 返回Map对象
通过流的方式来实现分组(groupingby()方法)
public class StreamTest13 {
public static void main(String[] args) {
Student student1 = new Student("zhangsan", 100, 20);
Student student2 = new Student("lisi", 90, 20);
Student student3 = new Student("wangwu", 90, 30);
Student student4 = new Student("zhaoliu", 80, 40);
List students = Arrays.asList(student1, student2, student3, student4);
//Map> collect = students.stream().collect(Collectors.groupingBy(Student::getName));
// System.out.println(collect);
Map> collect = students.stream().collect(Collectors.groupingBy(Student::getScore));
System.out.println(collect);
}
}
这种SQL如何用流来实现?
select name,count(*) from student group by name; 很容易:
Map collect = students.stream().collect(Collectors.groupingBy(Student::getName, Collectors.counting()));
System.out.println(collect); 先实现名字的分组,然后再取组内的平均值如何用流实现?
Map collect = students.stream().collect(Collectors.groupingBy(Student::getName, Collectors.averagingDouble(Student::getScore)));
System.out.println(collect); 以上所写的都是关于分组的概念.
分组:group by
分区:partition by
分区
分区是分组的特例,比如Boolean,只有true和false. 上述案例,比如以90分为分界点,分区
Map> collect = students.stream().collect(Collectors.partitioningBy(student -> student.getScore() > 90));
System.out.println(collect); collect.get(true);//获取ture对应的值
collect.get(false);//获取false对应的值