欢迎阅读新一期的数据库内核杂谈!上一期内容(表的JOIN)中,我们挖了一个坑:在大部分情况下,HashJoin都是表现最优的,那为什么还需要去支持其他Join比如SortMergeJoin或者NestLoopJoin的算子实现呢?因为不同表的大小,是否有索引支持,以及查询语句是否对某些column需要排序都会对执行算子产生影响,从而进一步影响执行时间。就是只看HashJoin,hash表到底是对表A来建,还是对表B来建,也会造成非常大的差别(通常,我们选取数据量小的表来做Hash表,这能使得需要用到的内存更少,更小概率需要借助外部Hash表来进行分批次的join)。而拥有最终决定权的,就是我们今天要聊的主角:数据库优化器(Query Optimizer)。
首先来谈谈为什么叫优化器。它优化的又是什么呢?最常见的优化指标就是查询语句的运行时间,譬如上述例子中的HashJoin,优化器选择用数据量小的表来建Hash表,运行时间就比选择用大的表要快。那我们再问深一层,为什么对应一个查询语句,可以优化执行时间?归根到底是因为SQL是一种declarative language(声明式语言),它只是告知了数据库系统,它希望数据以什么形式返回,但并没有告诉系统,要怎么去一步一步执行算子来得到最终结果。这和我们通常使用的编程语言是有所不同的。比如用C语言写一个冒泡排序和快速排序,虽然最终排序结果一样,但是快速排序确实只用到了更少的比较和交换,所以性能比冒泡排序要快。因为算法交代了应该如何去排序(当然,编译器还是可以进一步地来优化代码,比如function-inline,dead code elimination等等)。这就给了优化器变魔术的空间。
除了时间,还有什么可以优化的维度呢?比如计算资源,一个查询语句,需要发生多少次IO,使用多少内存,总共运行多少个CPU cycle,耗费了多少电量,等等。虽然,绝大部分情况下,这些资源都是正比于运行时间。再如,对于一个高并发的数据库系统,单个语句的运行时间可能并不是最好的优化指标,优化整体的吞吐量才是王道:相较于让每个语句都能在5秒内完成,可能更希望每10秒能运行完100个语句。
今天的内容我们主要围绕如何优化运行时间,因为对于单个语句优化执行时间,就已经是NP-HARD复杂度的问题了。不知大家是否还有印象,在讨论数据库执行模式的那章,我们简单介绍了整个数据库内核的架构,其中就谈到了优化器:优化器的输入是数据库的元数据以及语义绑定的语法树,输出是最终的物理算子的执行计划。那它内部又是怎么得到最终的物理算子的执行计划的呢?我们一步一步来看。
Query Rewrite (语句重写)
优化器的第一个阶段叫做Query Rewrite(语句重写)。这个阶段,主要是对原来的语法树进行等价语义的重写,通常是根据预先定义好的规则来进行重写,优化掉一些无效或者无意义的操作。换句话说,有时候程序员写的SQL通常是结果导向的,并不专门针对执行去优化,而且,很多时候还会有意无意引入无意义的操作。你可能会纳闷,怎么会呢?一起来看一些简单的示例。
SELECT
class.name AS class_name,
student.name AS student_name,
student.id AS student_id
FROM
class, student
WHERE
class.id = student.class_id AND
student.name = 'ZhangSan';
上述语句返回这个学校所有叫ZhangSan的学生的姓名,学号,以及班级。那这样一个语句转换成语法树应该是下面这个形式:
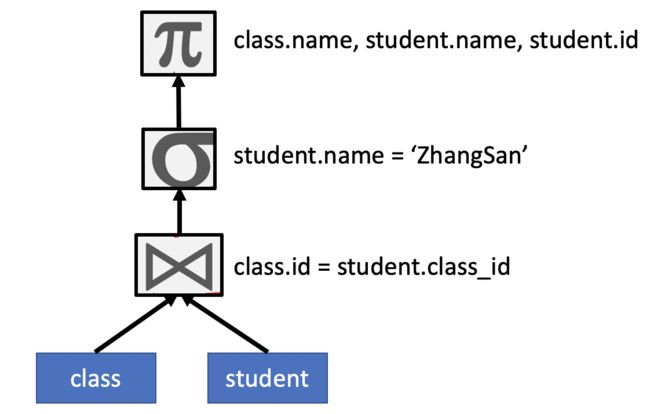
这里我用了简单的关系型代数模型符号来表达语法树的逻辑算子,只用到了最基本的projection,equality join,和filtering operator。看了这个语法树,你可能觉得,没毛病啊,语义正确。但是,如果直接把这个语法树转换成物理算子的执行计划,就会发现可以优化的地方了。我们自下而上地来看。首先执行计划要求扫描全表class和表student,然后对其进行Join,join条件是class.id = student.class_id。join完之后,对于tuple进行filter,filter条件是student.name = 'ZhangSan'。最后,对于filter后的tuple,进行projection,只有3个column作为输出class.name, student.name 和 student.id。
可能看完了这个执行计划的流程,读者依然会说,没毛病啊。其实不然。比如,对于class表,总共只用到了两个column:id 和 name,因此我们可以在读取表的时候直接进行projection。一是,相对于把整个表全部读取放进内存中,只读取2个column所需的内存要少很多。另外,如果考虑到使用列存形式存储数据,只读两个column和读取全部的column速度上也快很多。这里,我们引出了第一个语句重写的规则:Projections push down。通过把用到的哪些column往下推送直到叶节点的table scan,可以减少扫描后数据的大小,同时也可以提升扫描速度。同样的,我们也可以对学生表的读取进行优化,学生表只用到了id, class_id, 和name column。更进一步的是,对于学生表,除了projections push down,我们还能把filter predicates也往下推送。因为最终的结果里面只需要姓名为'ZhangSan'的学生,与其把所有的学生信息都读取进来和class表进行join,我们可以先filter掉其他的学生,使得join的数据大大减少(假设叫'ZhangSan'的同学应该不会很多)。这便是我们提到的第二个重写规则:Predicates push down。通过把filter predicates往下推送,以减少后续操作的数据量。经过这两步的改写,新的语法树变成了如下这个形式:

通过上述两个重写规则,我们使得自下而上读取的数据量减小到最少,继而减少后续处理的数据量,以此来优化执行时间。并且,这些重写规则,属于有百利而无一弊,只要规则允许,就应该进行重写。有读者可能有疑问了,这些语句重写能带来多少运行速度的提高呢?这完全取决于表的大小,数据分布和查询语句。试想,如果把student表换做是一个有万亿数据的超级大表,通过Predicates push down,可能最后只保留了几行数据。并且,由于Predicates push down,优化器可能会选择使用IndexScan而非全表扫描(如果对应的Predicate column有建立相应的index),这进一步极大提高了表读取速度,此为后话,暂且不表。
这些重写规则都是提前实现好了,在对语法树进行分析的时候,如果满足了某类触发条件,就会加载相应的重写规则。下面,我们再来看一些常见的重写规则。查询语句如下图所示:
SELECT * FROM super_large_table WHERE 1 = 0;
对SQL比较熟悉的读者可能一眼就看出来了,由于where condition的predicate始终为false,所以无论这个表有多大,最终结果都为空集。通过引入重写规则 Impossible/Unnecessary Predicates: 计算出Predicates的值,如果值衡为false,直接返回空集;如果值衡为true,直接去掉predicates。相对应的语法树发生如下变化:

重写后变为

这类规则有点类似传统编译器里的constant folding/propagation和dead code elimination的优化策略:试图在编译阶段就确定predicates的值,以此来简化expression。虽然上述的例子很简单,但有些查询语句的predicates会很复杂,优化器是否足够"聪明"作出优化,是考验优化器的一个标准。 笔者曾经对不同的数据库进行过比较,每一款优化器支持的语句重写规则都不同,正所谓没有比较就没有伤害!有时候会觉得,某某优化器怎么那么“笨”,连这个都看不出来。曾有个前辈这样说过,那些商用数据库之所以贵,就贵在优化器的聪明上。最后,我们一起来看几个并不是非常显而易见的重写规则。
示例查询语句1:
SELECT * FROM table1
WHERE
val BETWEEN 1 AND 50
OR val BETWEEN 45 AND 100;
通过Merge predicates重写规则,可以改写成如下(介于查询语句也能很好地体现重写后的效果,直接上SQL):
SELECT * FROM table1
WHERE val BETWEEN 1 AND 100;
优化器把多个predicates合并到了一起。
示例查询语句2:
SELECT * FROM table1 AS t1
WHERE EXISTS (
SELECT * FROM table1 AS t2
WHERE t1.id = t2.id
);
这个就有点复杂啦,如果优化器能察觉到EXISTS中的查询条件其实是table1的self join,这样condition就总是为true,所以可以被重写为:
SELECT * FROM table1;
再来看一个类似的示例语句3:
SELECT t1.*
FROM
table1 AS t1
JOIN
table1 AS t2
ON t1.id = t2.id;
因为依然是table1的self join,所以通过join elimination重写规则,可以直接改写为如下:
SELECT * FROM table1;
最后,来看一个不一样地去掉无意义语句的重写。示例语句如下:
SELECT
id, name, class_id
FROM (
SELECT * FROM students
ORDER BY id
) t
ORDER BY class_id;
不知道读者是否看出了这句语句中的无效操作,即inner语句中的ORDER BY id。因为在outter语句中已经申明了以class_id排序的要求,内部的排序即可视为无效语句。聪明的优化器可以直接将其改写成:
SELECT
id, name, class_id
FROM
students
ORDER BY
class_id;
类似的语句重写规则还有很多很多,优化器也会根据查询语句的侧重点,来实现特定的语句重写。留个问题给大家,还能想到哪些显而易见的语句重写规则吗?
总结
总结一下,优化器引入了事先编写好的语句重写规则,在编译语法树的过程中,通过触发规则来加载语句重写规则,从而简化语句,去掉无意义的语句,以及通过Predicates push down, Projectsions push down来优化数据读取。这些规则虽然有时候能大大简化语句,提升执行速度,但对于复杂的多表查询语句,显然是不够的。 比如下面这个示例语句:
SELECT
t1.a,
t2.b,
t3.c,
...
tn.x
FROM
table1 AS t1,
table2 AS t2,
table3 AS t3,
...
tablen AS tn
WHERE
t1.a = t2.aa AND
t2.b = t3.cc OR
...;
上述这句语句的复杂度在于,有n个表同时join在一起。对于表和表的Join relation,是可传递且可交换的。即:
table1 JOIN table2 = table2 JOIN table1
(table1 JOIN table2) JOIN table3 = table1 JOIN (table2 JOIN table3)
那上述n个表的join,表达成两两join的关系后,一共有多少种可能性呢? 我这里直接给出结果,大致会有4^n(4的n次方)种可能。要在那么多种可能中找到最优的join ordering,已经是NP-HARD的问题。那优化器又是如何在巨大的搜索空间中,找出最优解呢?下一期,接着聊优化器。