UserDfinedFunction, 即Hive的自定义函数, 是一个合格数据分析师/工程师用好Hadoop Hive必备的工具之一, 否则就无法按照各种各样的业务需求去查取数据.
本文介绍了如何开发, 使用Hive UDF的过程, 希望对大家有帮助!
一. Java开发
1. 导入必要的jar包
hadoop-common-2.4.0.jar
hive-exec-0.13.1.jar
commons-math3-3.4.1.jar
2.需求
这里, 我想做一个依据字符串数组的第一个数字来排序的程序.
程序取"|"前的数字作key来排序(ASC)
样例输入:
"1|其他内容页,2|其他内容页,4|其他内容页,3|浪首"
样例输出:
"1|其他内容页,2|其他内容页,3|浪首,4|其他内容页"
3. package结构
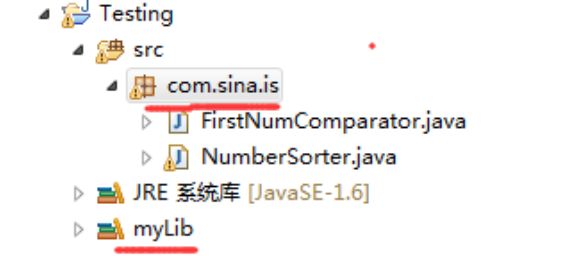
4. UDF的evaluate方法的两个坑点
a. 需要自己写evaluate方法
eclipse中如果选择override methods是看不到evaluate方法的, 因此这里必须手动地写evaluate
b. evaluate方法不可以接受字符串数组(String[] strarr)这样的参数
evaluate可以接受String类型参数, 因此一般使用evaluate(String str)
5. 实现UDF的代码
- NumberSorter.java
这个类中允许放一个main方法来做本机测试, 对放到hive上使用没有影响.
package com.sina.is;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* @author sina
* 取出list的每一个元素, 按照"|"分割, 分割后的part[0]作为排序的key, 来对整个list进行排序
* Xiaolong Chen
*/
public class NumberSorter extends UDF {
public List evaluate(String str) {
String[] strArr = str.split(",");
List list = new ArrayList();
for(int i =0;i - FirstNumComparator.java
这个类是用来提供compare比较函数给sort方法的.
package com.sina.is;
import java.util.Comparator;
public class FirstNumComparator implements Comparator {
@Override
//1, str1>str2;
//-1, str1key2) {
return 1;
} else {
return 0;
}
}
}
二. 打jar包
eclipse中,
右键'导出' -> java/Jar文件 -> 选择好要导出的package, class -> 选择导出目标(JAR文件)中写path, 比如"C:\Users\sina\Desktop\myCollection\NumberSorter.jar"
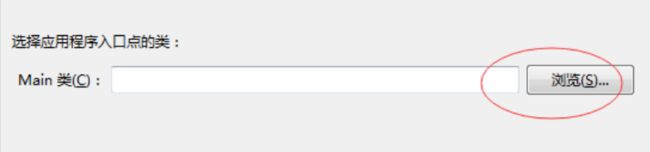
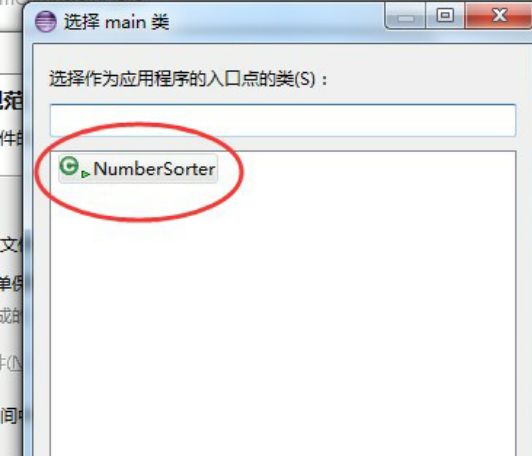
-> 一直点下一步, 直到看到选择应用程序入口点的类, 这里一定要点浏览, 然后选择NumberSorter -> 点击完成, jar包就导出到了指定目标文件夹中.
三. 线上导入和运行
借助secureCRT登陆服务器后, 随后执行如下三步
1. 上传和添加jar包到Hive
在shell中输入rz, 然后上传NumberSorter.jar
上传完后可以ls -l, 看一下到底上传成功没.
然后, 输入hive进入hive系统, 输入add jar /usr/home/lixuan5/NumberSorter.jar;, 记得别忘了结尾的分号.
2. 建立临时函数
输入create temporary function numbersorter as 'com.sina.is.NumberSorter';
其中, numbersorter代表之后在hive中要调用的函数名. (Hive不区分大小写, 因此函数名全小写即可)
这步做完后, 可以在hive中输入show functions;来检查自己的函数是否在hive的函数列表中.
3. 调用自定义函数
执行如下SQL语句
select numbersorter('1|其他内容页,2|其他内容页,4|其他内容页,3|浪首') from dual;
其中, dual是一个伪表, 并没有实际数据, 只是放在这里占位置来满足语法的.
真正的输入是函数括号中的String: '1|其他内容页,2|其他内容页,4|其他内容页,3|浪首',
输出是: ["1|其他内容页","2|其他内容页","3|浪首","4|其他内容页"] , 如图

END.