
1. Abstract
目前神经网络大部分都是运行在具有强大的浮点运算能力的服务器上面。如此庞大的网络是无法在普通PC上面运行,更不可能在移动端上面运行。但是由于业务需要和程序设计需要,我们可能想把CNN网络到移动端上面运行。面对庞大的网络和浮点运算能力比较弱的移动端,一些公司为此想降低CNN的复杂度同时保留大部分的精度。所以这里我想为大家介绍了一下我了解过的一些efficient and state-of-the-art CNN。
2. MobileNet V1
在传统的CNN,当中一层CNN的FLOPs计算:w * h * d_k * d_k * c_1 * c_2,虽然w和h都在降低维度,但是channel却一直以指数形式增加,那么每一层FLOPs都是越来越大的。MobileNet v1想把这个卷积操作的FLOPs降低,于是就利用到了depthwise convolution和pointwise convolution。如下图所示:
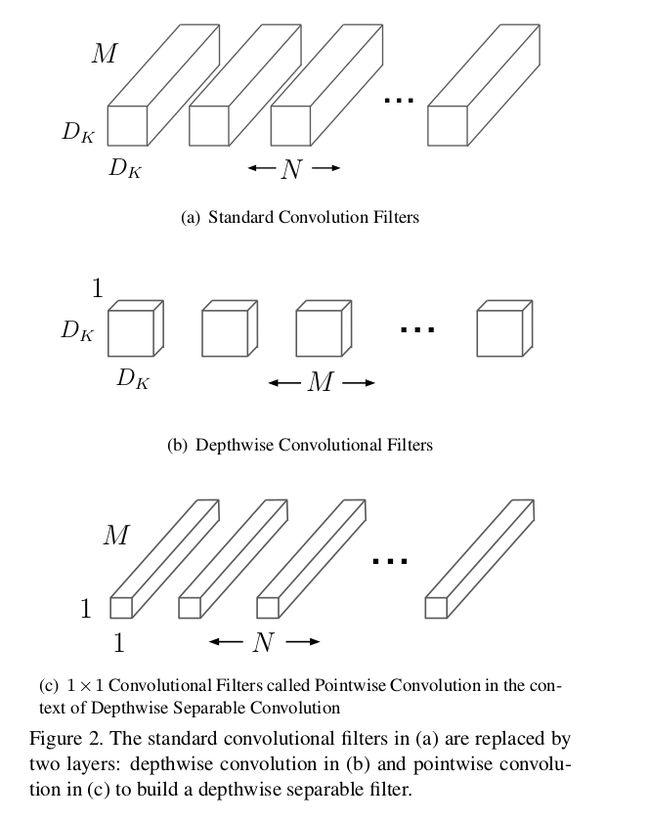
- depthwise convolution filter一共有m个d_k * d_k大小的filter,其中m是input features map的channels数量。每个d_k * d_k的convolution filter对应每个input features map的channel做convolution。我们可以这样看,每个filter都仅仅foucs当前channel与其他的channel没有信息流通。
-
pointwise convolution filter就是1 * 1 convolution filters,大小为1 * 1 * c_1 * c_2,其中c_1为输入的channel数量,c_2为输出的channel数量。这个操作已经是经常常见了,我就不再多讲。pointwise convolution就是仅仅foucs on relationship of channels与同一层channel上的所有feature没有信息流通。
我们将两者结合起来,就近似表达成为一个d_k * d_k * c_1 * c_2的convolution filters:
 Convolution Block
Convolution Block
我们可以算一下这种操作的FLOPs:w * h * 9 * c_1 + w * h * c_1 * c_2。这种压缩可以大量的浮点运算量,但也有良好的准确率。这种方法当然还是具有大量的浮点数运算,对于一些算力很弱的移动设备,我们还需要压缩模型。那么MobileNet V1为了我们提供了收缩因子:用于控制模型当中channel的个数。
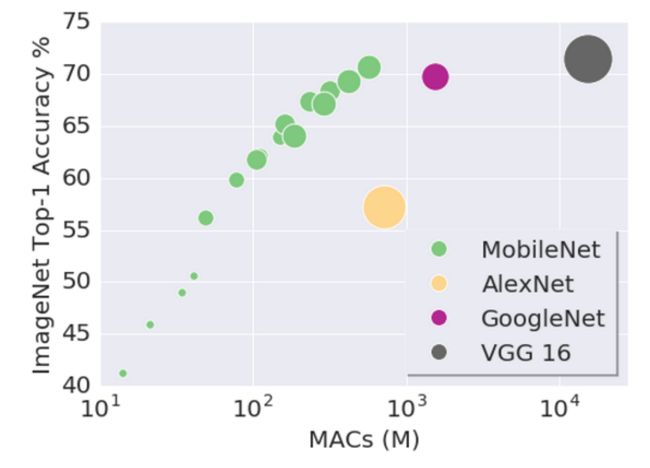
用不同大小的MobileNet,在ImageNet Top-1 的准确率比较:
3. ShuffleNet V1
ShuffleNet v1与MobileNet v1一样使用了depthwise和pointwise的convolution操作来降低运算量。但是ShuffleNet v1发现其实这种操作大多的FLOPS(浮点运算)都是集中在pointwise convolution。我们这里计算一下pointwise convolution的FLOPS:w * h * c_{input} * c_{output},相对于depthwise的FLOPS:w * h * 3 * 3 * c_{input}(depthwise的kernel size 为3)。pointwise convolution的浮点运算量是depthwise的c_{output} / 9倍。在CNN当中,output channels都是不断增加的,所以FLOPS就越来越大。考虑这一点,ShuffleNet v1采用AlexNet的group convolution方式来降低pointwise的FLOPS。
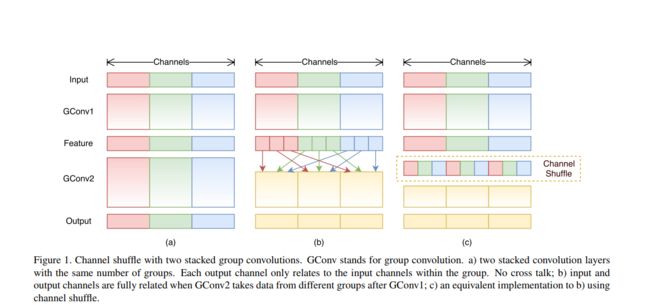
如上图所示,我们将channels分开若干个group,分别做pointwise convolution。我们算一下这个操作的FLOPS:h * w * (c_{input} / g) * (c_{output} / g) * g = hwc_{input}c_{output} / g。明显group convolution将原来的pointwise convolution降低了g倍(a图)。但进行了这种操作以后,不同group之间的channels的连接就基本上没有了。因此shuffleNet v1增加了channel shuffle的操作,增加了不同group之间的channels的信息连接多样性(b图,c图)。
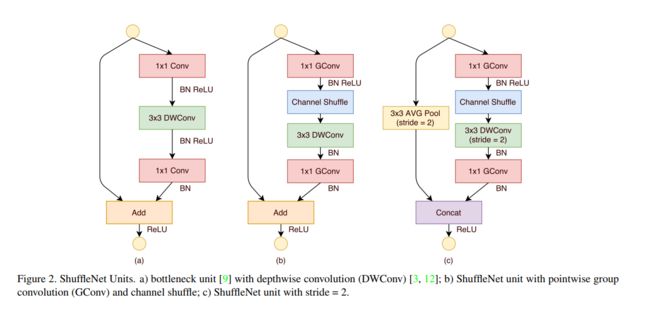
上图b,c为shuffleNet Units。a图是最原始的设计,后来用group convolution代替当中的pointwise。b图为convolution stride = 1的Unit,c图为convolution stride = 2的Unit。
那么group设置为多少好呢?论文中作了一些对比试验来看group设置多少好。
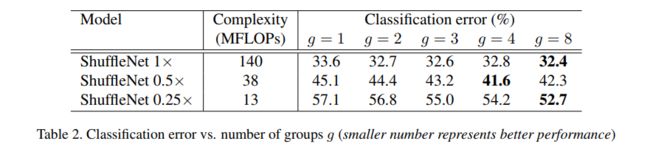
我们可以留意到在同样的FLOPS复杂度的情况下,scale越小的Networks使用越大的group越有利提高精度。在同一个FLOPS的复杂度下,group越大那么就允许越多的channels,越多的channels包含的信息量越多那么精度也能有所提高。此外,越小的网络从channels增加得到精度增益越大。那么我们是不是越设置越大的group越好呢?刚刚说的是同样的FLOPS复杂度上,但是越大group使得group convolution趋向于depthwise convolution,那么channels之间的连接几乎没有,这是不利于网络的。
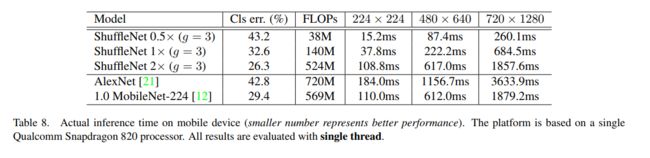
4. MoblieNet v2
MoblieNet v2论文题目就说明其两个重要的keypoint。一个Inverted Residual,另外一个是Linear Bottlenecks。这篇论文的理论看得十分费力,到现在还是看得一般般懂。所以我这里就说一下自己理解到的state of the art。
4.1 Inverted Residual
在moblieNet v1中,我们没有看到residual的存在,所以在v2当中我们加入了residual,但我们没有直接照搬其内容
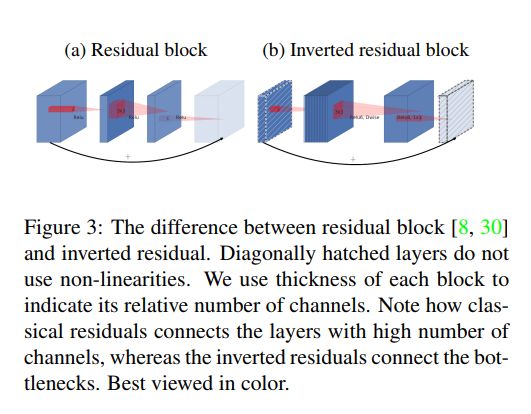
这里的是Inverted residual block。为啥我们这样操作呢?因为不同于residual block,depthwise convolution的计算量很低,所以我们可以适当增加depthwise(增加t倍)计算的channels数量来提高模型精度。其实,其认为residual block这样先降维(降低channels),使得下一层的信息有所一定的损失,再加上depthwise,损失更大。那么我们采用升维的操作来增加depthwise convolution的信息量,这样减少每层block当中信息损失。
4.2 Linear Bottlenecks
这个Linear的操作是在Inverted Residual block的最后。我们想一下之前的Inverted Residual block,头尾的维度(channels数量)显然比中间要低,
我们可以理解成为y = B^{-1} * Relu(A * x)。x为输入,y为输出,A为中间的升维操作,B的逆矩阵为降维操作。而输入和输出的维度是近似相同的,那么其实我们用linear操作更为适合。若使用Relu的话最后输出可能出现0。这样输出是不可逆的,信息也会损失。所以我们最后一层使用Linear来保留大量有用的信息。再者我们也可以这样理解,最后一层输出的降维操作,那么假如用Relu会加剧信息流失。而论文最后的Appendix,作者认为其实目标(图像)是可以用一个低维子空间表示,通过降低激活空间的维度最终希望让感兴趣信息充满整个字空间。
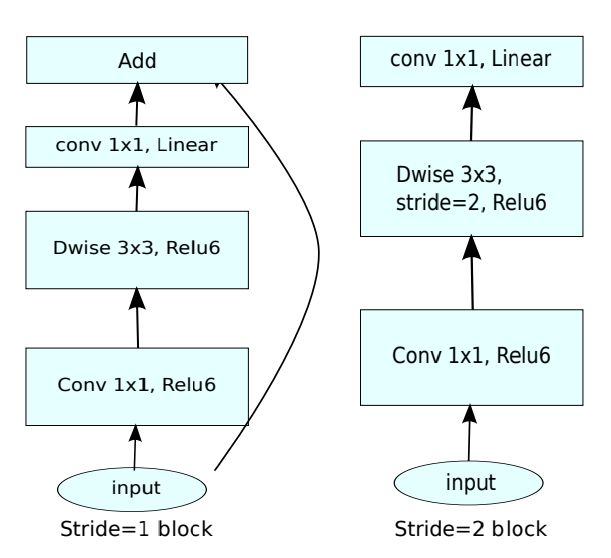
那有人会问我:既然参数是变多了,那么MoblieNet v2还是速度不是应该更慢吗?其实在头尾的channels数量是很少,从而减少了Inverted Residual block中间升维的影响。
5. ShuffleNet V2
ShuffleNet v2论文题目是说Guidelines for Efficient CNN Architecture Design。一般衡量CNN网络的理论运算时间,我们都是用FLOPS(浮点运算次数)来表示。但其实这个有不太符合实际情况的。首先在不同硬件平台上,convolution运算可能是存在优化的。例如一个做3 * 3的convolution操作运算时间不一定是1 *1的convolution操作的9倍。因为在CUDNN下是有CNN并行优化的,所以不能单单用FLOPS来衡量一个CNN的运算时间。此外FLOPS只是考虑到浮点的运算次数,但是还有其他因素影响CNN的实际运算时间,例如memory access cost —— MAC(内存访问损失),ShuffleNet v2就是将其作为指标设计出来的模型并得到4条Guidelines。
5.1 相同的通道宽度可最小化内存访问成本(MAC)
对于1 * 1的卷积,我们考虑以下其MAC:hwc_{1}(读取输入的feature map的MAC) + hwc_{2}(写入输出的feature map的MAC) + c_{1} c_{2}(读取1 * 1的卷积大小)。那么总的MAC为:h * w * (c_{1} + c_{2}) + c_{1} * c_{2}。那么1 * 1的卷积FLOPS为:B = h * w * c_{1} * c_{2}。通过三角不等式我们可以得到以下的不等式:
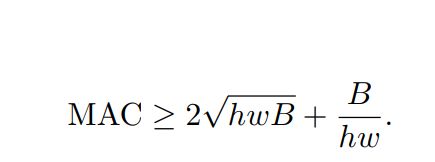
根据三角不等式,我们可以知道仅且尽当c_1 = c_2时候,等号成立且MAC最小。所以我们希望convolution操作的输入输出channel一致。
5.2 过度的组卷积会增加 MAC
再考虑有g个group convolution的时候,MAC值应该是:h * w * (c_{1} + c_{2}) + c_{1} * c_{2} / g,FLOPS值应该是:B = h * w * c_{1} * c_{2} / g。在一般的情况下,input features的大小是固定的,其次我们要讨论的是group的个数对MAC的影响,那么我应该控制FLOPS都是一致的。因此我们假设给定的输入input features size以及FLOPS,那么我们MAC式子进行转换可以得到:h * w * c_{1} + B * g / c_{1} + B / hw。可见Group个数越多那么MAC也就越大。回顾之前讨论shuffleNet v1的时候,在固定的features map和FLOPS上,group增加那么输出的channels(c_{2})也就应该同等比例增加。随之MAC的第一项h * w * (c_{1} + c_{2})也变大。
5.3 网络碎片化(例如 GoogLeNet 的多路径结构)会降低并行度
在论文当中的Appendix给出了一些碎片化的convolution:
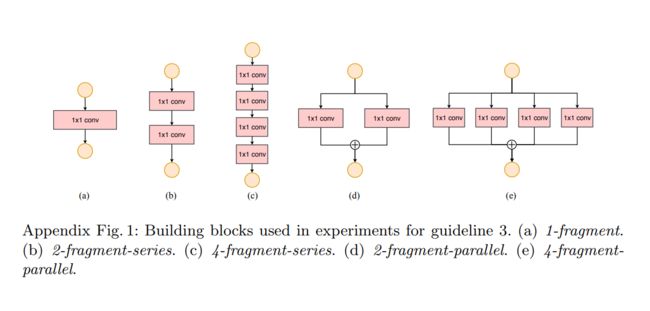
这种操作是将一个大kernels的conv转换为多个小kernels的conv。这样确实有助于提高模型的精度,但是这是通过模型的运行效率来交换的。这样效率的差异在并行计算强的硬件上是尤其突出。
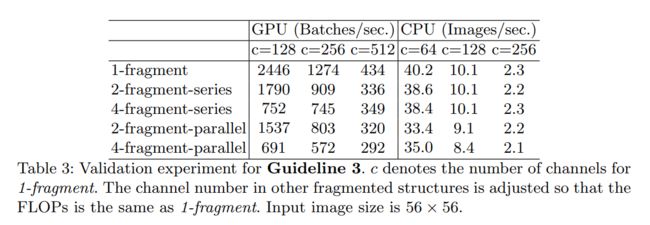
在GPU上差异是十分明显,但是在ARM就不是特别明显了。所以这个Guideline可以作为思考精度和效率的取舍点。
5.4 元素级运算不可忽视
一些Elements-wise的操作(如Add,ReLu),虽然这些FLOPS几乎是没小,但是它是存在大量的MAC,所以不能忽略其对效率的影响。
根据以上这个4条Guideline,作者设计出ShuffleNet v2:
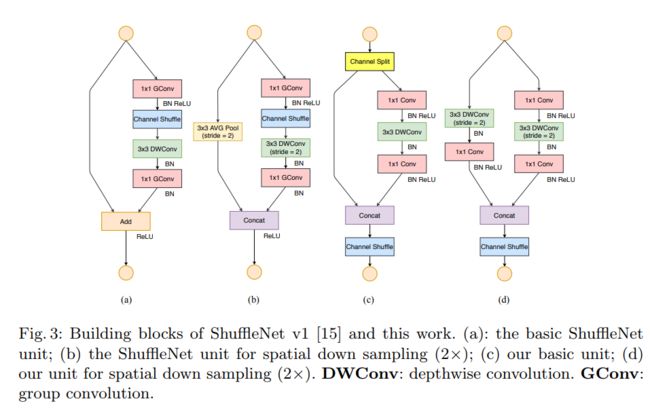
我们保证每个Conv的输入channels数量和输出channels数量是一致的(符合G1),我们这里没有使用Group convolution,而是采用channels split的操作(Group可以看作是2,其中论文为了简便两个branch的channel数量是一样的),尽可能减少了group的数量(符合G2),在图c当中,其中一个branch是identity没有减弱并行度(符合G3),最后我们在最后连接上没有用上Add和ReLU,而是Concat降低一定的MAC(符合G4)。首先这个构造是可以提高模型的运行效率的,我们可以看看下图的一小部分实验结果(有兴趣的同学可以看看论文的实验部分):
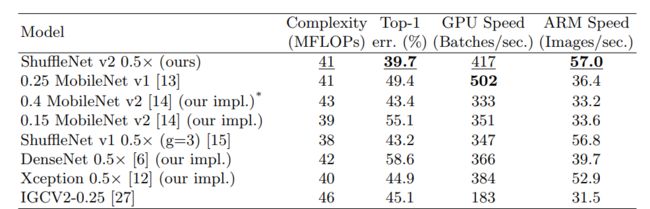
可见shuffleNet v2的效果是挺优秀的。
这里我们可以讨论一下为什么shuffleNet v2也能够在提高模型精度。
- 在同一样的FLOPS下,效率越高的模型,其可以将模型做得更深,精度自然也会上来。
- 在每一个block里面,我们都有一个branch(一般的feature map)是直接join到最后的结果的,它存在一种特征复用的效果。这一块有点类似于DenseNet。我们通过下图每一层权值的L1-norm对比得知:
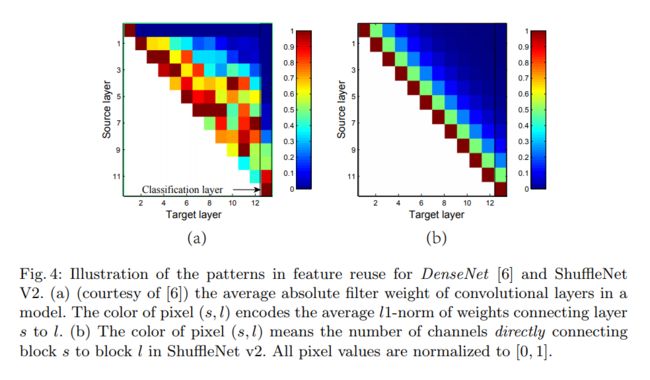
由于DenseNet把当前输出连接到后续的每一个blocks,所以它引入了冗余性,而ShuffleNet v2将特征从用虽然也是会传递到后续的每一层,但是传递的feature数量是呈指数递减的。在本论文当中,只有一半的feature map直接join到输出当中,再通过channels shuffle,本层传递到后两层的feature map的数量只有0.25,如此类推。那么重用率大约是r^{j - i},r为channel split当中identity的占比数量,而i,j代表目标层序号。
6. Summary
我觉得这些CNN的网络其实给我的感觉是设计符合自己业务需求的Guidelines。所以根据需求去选择符合自己的Guidelines便好,有空我会将这些模型都写一遍,让自己和大家都能够 get your hands dirty。讲真算法不能光看论文还需要落地的。
7. References
- MobileNet v1
- ShuffleNet v1
- MobileNet v2
- ShuffleNet v2
- https://blog.csdn.net/Dlyldxwl/article/details/79101293
- https://zhuanlan.zhihu.com/p/40824527