用户自定义函数(UDF)是大多数SQL环境的一个关键特性,其主要用于扩展系统的内置功能。UDF允许开发人员通过抽象其低级语言实现在更高级语言(如SQL)中应用的新函数。Apache Spark也不例外,其为UDF与Spark SQL工作流集成提供了各种选项。
在本篇博文中,我们将回顾Python、Java和Scala上的Apache Spark UDF和UDAF(用户自定义的聚合函数)实现的简单示例。我们还将讨论重要的UDF API功能和集成点,包括各发行版本之间的当前可用性。总而言之,我们将介绍一些重要的性能注意事项,使您对应用程序中利用UDF的选择有所了解。
Spark SQL UDFs
UDF转换了表中单个行的数值,为每行生成单个对应的输出值。例如,大多数的SQL环境都提供了一个UPPER函数,同时返回了一个大写版本的字符串以作为输入。
自定义函数可以在Spark SQL中定义和注册为UDF,并具有可用于SQL查询的关联别名。下面我们将为您介绍一个简单的例子,我们将定义一个UDF将以下JSON数据中的温度值从摄氏度(Celsius)转换为华氏度(Fahrenheit):
下面的示例代码使用SQL别名CTOF注册我们的转换UDF,然后使用它从SQL查询中转换每个城市的温度值。为简洁起见,省略了SQLContext对象和其他样板代码的创建,并在每个代码段下面提供了完整列表的链接。
Python
Scala
Java
请注意,Spark SQL定义了UDF1~UDF22类别,支持包含最多22个输入参数的UDF。上面的例子中使用UDF1处理单个温度值作为输入。如果未能对Apache Spark源代码进行更新,使用数组(arrays)或结构体(structs)作为参数对于需要超过22个输入的应用程序可能很有帮助;从风格的角度来看,如果您发现自己使用的是UDF6或更高版本,这一方案可能是首选。
Spark SQL UDAF函数
用户自定义聚合函数(UDAF)可以同时处理多行,然后返回单个值作为结果,其通常与GROUP BY语句(例如COUNT或SUM)共同使用。为了让示例简单明了,我们将实现一个别名为SUMPRODUCT的UDAF按使用分组、给定价格和库存中的整数数量计算所有车辆的零售价值:
目前,Apache Spark UDAF的实现定义在扩展继承的了UserDefinedAggregateFunction类别中并有由Scala和Java语法支持。一旦定义好之后,我们可以在别名SUMPRODUCT下举例说明并注册我们的SumProductAggregateFunction UDAF对象,并从SQL查询中予以使用,这与前面示例中的CTOF UDF大致相同。
Scala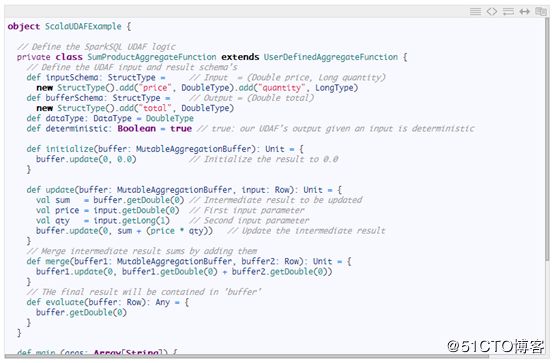
Apache Spark中的其他UDF支持
Spark SQL支持UDF、UDAF和UDTF等现有Hive(Java或Scala)函数实现的集成。顺便提醒一下,UDTFs(用户自定义表函数)可以返回多个列和行 – 这超出了本文的范围,但是我们可能在以后的博文中涉及。对于使用前面示例中强调的方法重新实现和注册相同逻辑,集成现有的Hive UDF是有价值的一种替代方法;从性能角度来看,该方法对于PySpark也是有帮助的,这将在下一节中讨论。通过包含Hive UDF函数实现的JAR文件利用spark-submit的-jars选项,可以从HiveContext中访问Hive函数;然后使用CREATE TEMPORARY FUNCTION对函数进行声明(如在Hive [1]中所做,包含一个UDF),具体示例如下所述:
Java 中的Hive UDF定义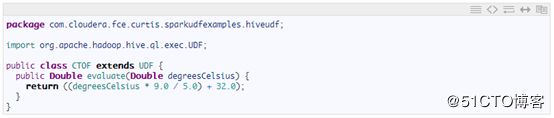
从Python访问HiveUDF 
请注意,如上文中我们实现的UDF和UDAF函数,Hive UDF只能使用Apache Spark的SQL查询语言进行调用 – 也就是说,不能与Dataframe API的域特定语言(DSL)一起使用。
或者,通过包含实现jar文件(使用含有spark-submit的-jars选项),以Scala和Java语言实现的UDF可以从PySpark中进行访问,然后通过SparkContext对象的私有引用执行器JVM、底层Scala或装载在jar文件中的Java UDF实现来访问UDF定义。Holden Karau在一次精彩的演讲中[2]对这种方法进行了探讨。请注意,在此技术中所使用的一些Apache Spark私有变量不是正式面向终端用户的。这样做还带来了额外的好处,允许将UDAF(目前必须在Java和Scala中定义)用于PySpark,下文中的示例中使用了前面在Scala中定义的SUMPRODUCT UDAF进行证明:
Scala UDAF定义
Scala UDAF from PySpark 
UDF相关的功能正在连续不断地添加至Apache Spark的每一个版本中。例如2.0版本在R中增加了对UDF的支持。作为参考,下表总结了本文中讨论的各版本的关键特性: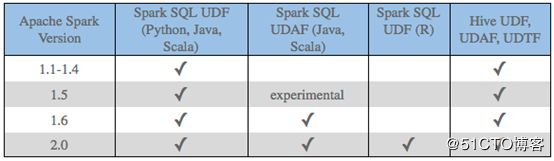
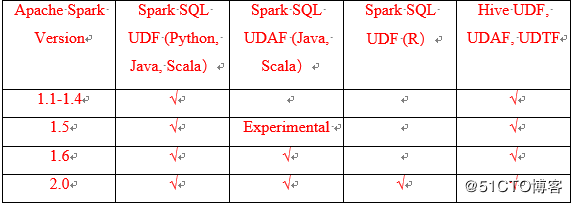

表格中汇总了目前为止本博客中介绍过的相关版本的关键特性。
性能注意事项
了解Apache Spark UDF功能的性能影响是非常重要的。例如,Python UDF(比如我们的CTOF函数)导致数据在运行UDF逻辑的执行器JVM和Python注释器之间被序列化 - 与Java或Scala中的UDF实现相比,这大大降低了性能。缓解这种序列化瓶颈的潜在解决方案包括以下方面:
- 如上一节所述,从PySpark中访问Hive UDF。Java UDF实现可以由执行器JVM直接访问。请再次注意,这种方法只用于从Apache Spark的SQL查询语言访问UDF。
- 这种方法的使用也可以参考PySpark访问在Java或Scala中执行的UDF,如我们之前定义的Scala UDAF示例所示。
一般来说,UDF逻辑应尽可能的精简,因为可能每一行都会被调用。例如,在扩展到10亿行时,UDF逻辑中的一个步骤需要耗费100毫秒的时间才能完成,从而很快就会导致重大的要性能问题。
Spark SQL的另一个重要组成部分是Catalyst查询优化器。这一功能随着每个版本而扩展,通常可以为Spark SQL查询提供显著的性能改进;然而,任意UDF实现代码对于Catalyst而言可能不是很好理解(虽然分析字节码的未来功能[3]被认为可以解决这一问题)。因此,使用Apache Spark内置SQL查询函数功能通常可以带来最佳性能,并且应该是在避免引入UDF时考虑的第一种方法。高级用户寻求利用Catalyst与其代码更紧密地结合,可以参考以下Chris Fregly的演讲[4],该演讲人使用Expression.genCode优化UDF代码,并且使用了新的Apache Spark 2.0实验功能[5],其为定制Catalyst优化程序规则提供了一个可即插即用的API。
结论
当Spark SQL的内置功能需要扩展时,UDF是一个非常有用的工具。本篇博文中提供了一次UDF和UDAF实现的演练,并讨论了其集成步骤,以在Spark SQL中利用Spark SQL中现有的Java Hive UDF。UDF可以在Python、Scala、Java和(在Spark 2.0中)R中实现,同时UDAF 可以在以及Scala和Java的UDAF中实现。当在PySpark中使用UDF时,必须考虑数据序列化成本,并且应该考虑采用上文所讨论的两个策略来解决这个问题。最后,我们探讨了Spark SQL的Catalyst优化器,以及基于性能考虑的因素,在解决方案中引入UDF之前坚持使用内置SQL函数的性能考虑因素。
代码https://github.com/curtishoward/sparkudfexamples
CDH版本:5.8.0(Apache Spark 1.6.0)