去年大概这个时候,我写了一篇超详细的微博模拟登陆分析和实现,那时候才刚开始在上写技术文章,以至于收获了一些喜欢和粉丝而激动不已。后面写了一篇关于如何以正确姿势科学上网的文章被屏蔽之后,就没怎么在上写技术文章了。自己的一些想法和一些技术上的积累也只放在个人博客上,但是感觉流量太小了,所以又打算回归写作。
今天我给大家讲讲如何模拟登陆百度云盘(该分析过程也适用于百度别的产品,比如模拟登陆百度搜索首页,它们的加密流程完全一样,只是提交参数有微小差别)。
阅读文章之前,有一些东西需要给大家阐述:
- 本文并没有对验证码识别进行分析,因为我觉得写爬虫最主要的不是识别验证码,而是如何规避验证码。
- 本文要求读者具有模拟登陆(主要是抓包和阅读js代码)和密码学的基本知识。
和模拟登陆微博的分析流程一样,我们首先要做的是以正常人的流程完整的登录一遍百度网盘。在打开浏览器之前,先打开抓包工具,以前我在win平台用的是fiddler,现在由于电脑是mac系统,所以选择charles进行抓包。如果有同学没有charles的使用经验,那么需要先了解如何让charles能抓取到本机的https数据包。由于使用charles抓包不是本文的重点,所以我就简略说一下:
- 安装charles证书。通过菜单'help'->'ssl proxying'->'install charles root certificate'进行安装,安装过后把证书设置为始终信任
- 修改charles的proxy settings。 选择proxy->proxy settings,然后勾选“enable transparent HTTP proxying”
- 修改Charles的SSL proxy settings。选择proxy->ssl proxy settings,在弹出的对话框中勾选"enable ssl proxying",并在location部分点击add,添加需要捕获的站点和443端口,如图:
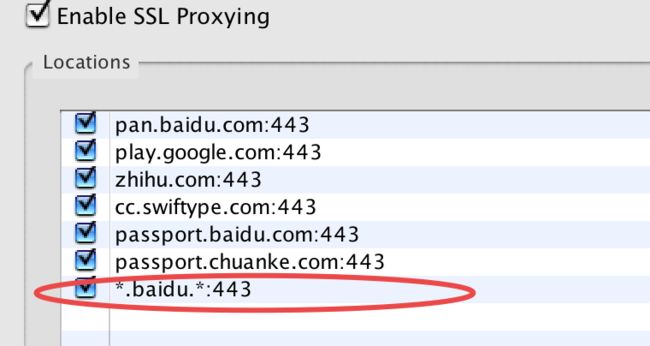
charles设置好了之后,我们再使用浏览器直接打开百度网盘首页 。注意打开之前如果以前登录过百度网盘,一定要先清除百度网盘的cookie,如果不清楚自己以前登录过没,那么最好把关于百度的cookie都清除了吧。如果清除得不彻底,很可能会错过很关键的一步,我先按下不表。通过抓包,我们可以看到请求百度网盘的首页,大概有这些请求:

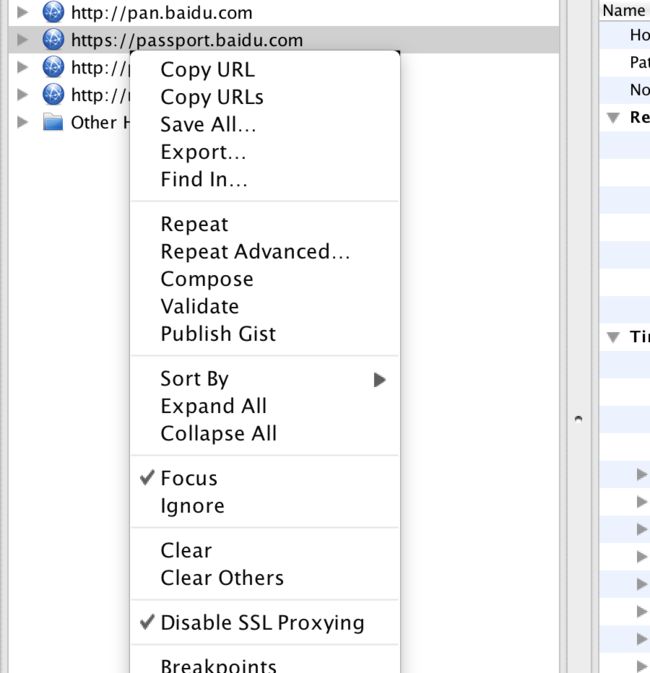
这里other hosts是本机别的请求,所以直接被我忽略了(通过设置请求为“focus”或者“ignore”)。下图给的是设置方法,主要是Focus和Disable SSL Proxying:
大家可以查看具体每个请求的内容和响应,由于篇幅限制,我就不啰嗦了。然后我们在登录页输入登录账号(先别输入密码和点击登录,如果有想不明白的同学可以阅读我的微博登陆分析),然后观察charles的请求,会发现又多了一条请求:

我们看看它返回的内容:

可以看到有效信息大概有两个: pubkey和key,它们的用途我们都还不知道,但是看命名可知大概pubkey是某种加密算法的公钥。
然后我们输入密码,点击登录,可以看到charles的请求:
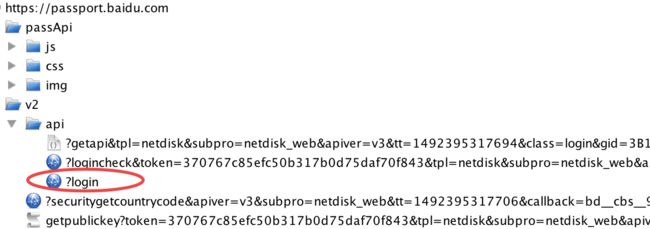
上图圈出来的请求就是提交的密码和登录账号等信息,这个只有大家自己挨着请求查看,才可以确定哪个是post的请求。我们查看post的参数:
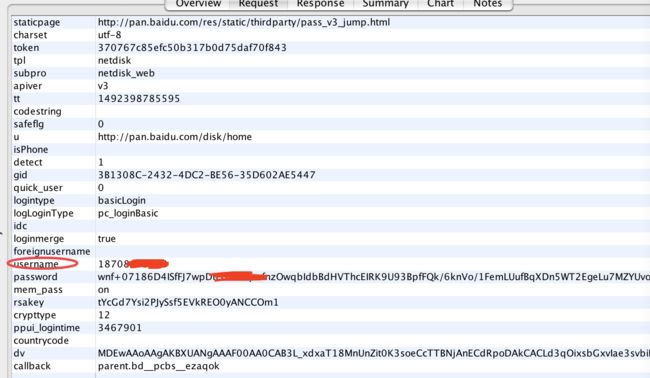
现在终于Get到重点了,主要就是要把这些提交的参数的生成方式弄清楚。如果有过模拟登陆或者爬虫编写经验的同学,都应该知道请求参数构造之前必须分析清楚哪些参数是变的,哪些参数是不变的,变的哪些参数比较有规律,哪些没有规律。这个分析过程是通过反复登录和抓包,对比post数据来完成的。我们通过反复登录和对比post的数据,可以发现:
staticpage、charset、 tpl、 subpro、apiver、codestring、 safeflg、u、 isPhone、detect、quick_user、logintype、logLoginType、idc、loginmerge、foreignusername、username、mem_pass、crypttype、countrycode、dv
等参数不会变化。所以我们只需要分析变化的参数。
变化的参数当中,tt看样子基本可以确定是请求时间戳(需要分析它是多少位,精确到毫秒还是秒),其它好像都没什么规律。由于微博模拟登陆的经验,我们基本可以判断出password这个参数是最难分析的(从账户安全角度上来说也应该是加密最复杂的),我们放到后面分析。
那么我们先来分析token字段吧。参数不可能凭空产生,来源只有两种可能:一种是通过服务端返回, 另外一种是通过请求回来的js构造。在分析token产生的时候,我们需要用到charles的查找功能(良心推荐,很强大),它可以查找到整个登录流程中,包含某个查找字符串的所有请求和响应。下图中的"望远镜"图标就是查找功能。
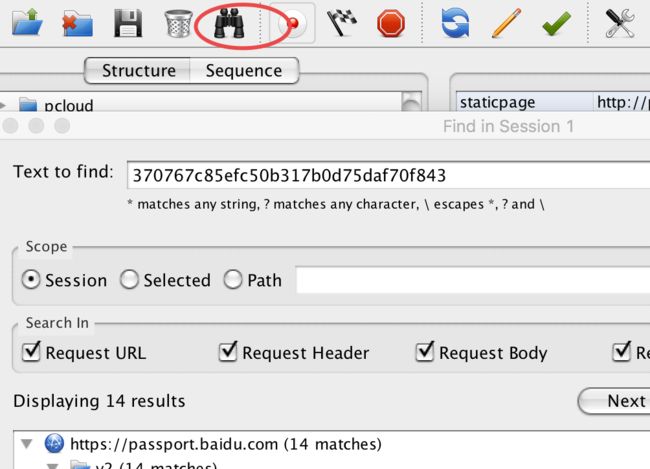
通过查找,我们可以看到有14个地方包含了token的值,我们发现基本都是使用token作为请求参数的,不过有一个结果是返回token值的:
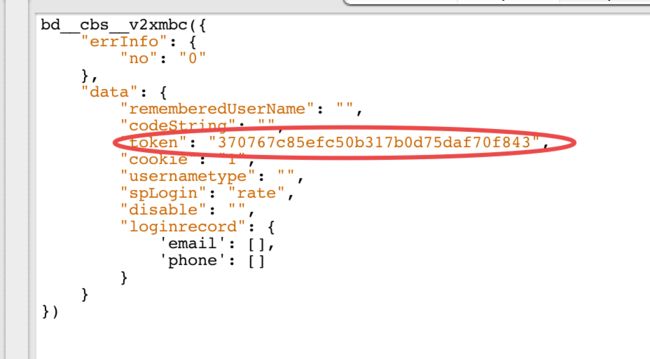
它的请求url是
https://passport.baidu.com/v2/api/?getapi&tpl=netdisk&subpro=netdisk_web&apiver=v3&tt=1492395317694&class=login&gid=3B1308C-2432-4DC2-BE56-35D602AE5447&logintype=basicLogin&callback=bd__cbs__v2xmbc
请求参数格式化一下,可能更方便查看:
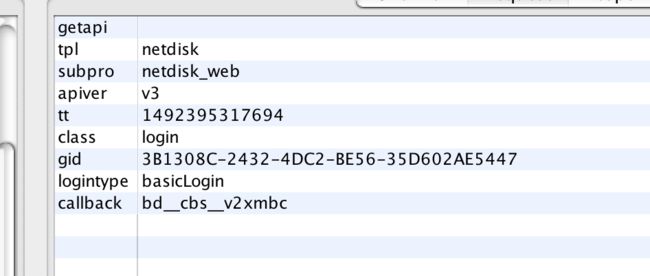
根据上面介绍的分析变量与不变量的思路,这里我们可以看到要获取到token,需要知道gid、callback的构造方法。然后用和分析token同样的方式,我们来分析gid的产生。通过在charles中查找gid的值,我们发现找到的结果全是在请求中,并没有在响应中找到该值,说明该值是通过js生成的而不是通过服务端返回的。既然是通过js生成的,我们需要找到该js文件。怎么找呢?我们在charles中输入gid,再来看看查找的结果,注意这次我们重点关注哪个js文件中出现gid,否则查找的结果太多,看起来会比较费力。通过查找,可以看到名为login_tangram_c36ce25.js这个文件中频繁出现了*gid这个参数,基本可以确定这个js文件很关键,这也是我先前说的在抓包分析之前需要把百度的cookie等历史数据清除的原因,否则该js文件可能已经缓存了,charles中就查不到该js。我们把该js文件下载下来,通过webstorm将其中的代码格式化,再查找gid,可以看到这段代码

其中的this.guideRandom函数就是生成gid的函数,因为我们在webstorm中查找gid字符串的时候,可以发现很多如下图所示的语句,只需要定位到guideRandom即可

我们现在找到了gid的生成方式了,如果读不懂这段js也没关系,可以直接使用pyv8或者pyexecjs等库将运行后的js结果返回给python使用。然后我们再回到获取token的请求参数那张图,发现还有个callback参数需要分析。同gid分析过程一样,我们先搜索callback的值bd__cbs__v2xmbc,发现只有请求中包含,基本可以确定它是通过js产生的,而加密js文件我们已经找到了。如果你害怕可能不是上面的那个js文件,我们也可以通过在charles中搜索callback这个字符串,可以发现就是该js文件。通过在webstorm中搜索callback关键词(通过前面多次登录抓包分析,可发现callback的bd__cbs_前缀不会改变,这个也可以是搜索依据),可以找到callback的生成方式
var i, r, o, a = this.url, s = document.createElement("SCRIPT"), u = "bd__cbs__", d = t || {},
l = d.charset, c = d.queryField || "callback", f = d.timeOut || 0,
p = new RegExp("(\?|&)" + c + "=([^&]*)");
// 下面就是callback的生成逻辑
baidu.lang.isFunction(e) ? (i = u + Math.floor(2147483648 * Math.random()).toString(36)
截至目前,我们已经弄清楚了gid和callback的生成方式了,这样我们就可以通过构造请求来获取到token了。我们再返回post参数这张图片,可以看到还有password、rsakey、ppui_logintime这三个字段还需要分析。而通过搜索rsakey的值,可以看到其实它就是 图片输入账号后服务端返回的内容 中的key的值,我们可以通过
https://passport.baidu.com/v2/getpublickey?token=370767c85efc50b317b0d75daf70f843&tpl=netdisk&subpro=netdisk_web&apiver=v3&tt=1492398777745&gid=3B1308C-2432-4DC2-BE56-35D602AE5447&callback=bd__cbs__3pnrh5
这个请求获取到。请求的参数如图,都是我们前面分析过并且能够得到的参数:
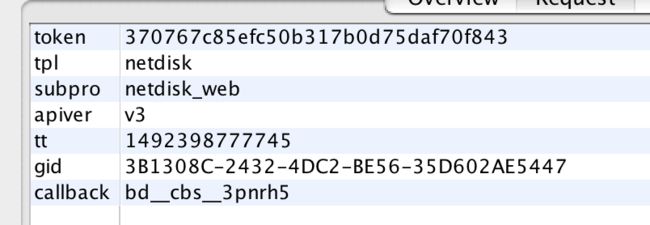
现在我们就只有ppui_logintime和password两个字段没分析了。
老规矩,我们先在charles中搜索ppui_logintime的值,发现只有一个请求中出现了。那么它肯定是js生成的,它是如何生成的呢?我们又在我们获取的login_tangram_c36ce25.js文件中搜索ppui_logintime这个字符串,可以发现这段代码:
login: {
memberPass: "mem_pass",
safeFlag: "safeflg",
isPhone: "isPhone",
timeSpan: "ppui_logintime",
logLoginType: "logLoginType"
}
然后我们再看
timeSpan是如何生成的。可以看到这段代码
r.timeSpan = (new Date).getTime() - e.initTime
大概是一个时间差:当前时间-初始化时间。当前时间容易获取,那么初始化时间到底是什么初始化呢?继续追踪initTime可以发现这段代码
_initApi: function (e) {
var t = this;
t.initialized = !0, t.initTime = (new Date).getTime(), passport.data.getApiInfo({
apiType: "login",
gid: t.guideRandom || "",
loginType: t.config && t.config.diaPassLogin ? "dialogLogin" : "basicLogin"
})
.....
initApi中的initTime大概就是页面请求完成的时间,所以ppui_time应该就是登录页面初始化完成到点击登录按钮的时间差,为了方便,我们只需要取抓包获取的值即可。
现在分析password参数,这个参数也是分析难度最大的参数了。这次我们直接在加密js文件中搜索password关键词,可以搜索到很多地方有password这个字符串,那么如何做筛选呢?需要我们有一点js的基础知识,在每个匹配到password的地方都读读源码,大概知道它做什么的就行了。最后,我们可以定位到这段代码:
var r = baidu.form.json(e.getElement("form"));
r.token = e.bdPsWtoken, passport.data.setContext(baidu.extend({}, e.config)), r.foreignusername && (r.foreignusername = e._SBCtoDBC(r.foreignusername)), r.userName = e._SBCtoDBC(r.userName), r.verifyCode = e._SBCtoDBC(r.verifyCode);
var o = e._SBCtoDBC(e.getElement("password").value);
if (e.RSA && e.rsakey) {
var a = o;
a.length < 128 && !e.config.safeFlag && (r.password = baidu.url.escapeSymbol(e.RSA.encrypt(a)), r.rsakey = e.rsakey, r.crypttype = 12)
}
var s, u = e.getElement("submit"), d = 15e3;
上述代码既有rsakey、form又有password关键字,那么十有八九就是加密password的方法了。主要加密语句是:
e.RSA.encrypt(a)
我们查看encrypt()的实现
Jn.prototype.encrypt = function (e) {
try {
return xn(this.getKey().encrypt(e))
} catch (t) {
return !1
}
}
这里的过程大概就是先用this.getKey()返回的对象对e进行加密,然后再进行一次xn(),这里js的代码十分复杂,如果想把对应的js转化为python实现,需要很深的js和python功底,但是这个转换已经有人帮我们做了。这里的encrypt()即是使用rsa非对称加密算法对密码进行加密。而xn()是base64编码方法。判断encrypt()是rsa加密算法的依据是该js文件中出现了多次rsakey,并且也有
fn.prototype.getPrivateKey = function () {
var e = "-----BEGIN RSA PRIVATE KEY-----\n";
return e += this.wordwrap(this.getPrivateBaseKeyB64()) + "\n", e += "-----END RSA PRIVATE KEY-----"
}, fn.prototype.getPublicKey = function () {
var e = "-----BEGIN PUBLIC KEY-----\n";
return e += this.wordwrap(this.getPublicBaseKeyB64()) + "\n", e += "-----END PUBLIC KEY-----"
}
这类代码作为佐证。判断后者是base64算法的依据是
xn()函数中出现了
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
这类字符串,它是base64编码的一个基础部分。
所以说这里的分析需要大家有基本的密码学知识,否则分析会比较困难。这里友情提示一句,目前主流的大中型网站都会使用rsa算法对密码进行加密,所以大家需要有这个意识。但是不要求大家会实现rsa等加密算法,因为无论是python还是js还是java都有相关的实现了,我们只需要会分析会使用就行了。
到这里所有的参数分析就结束了,我们可以通过代码进行验证。
上面详细介绍了百度整个登录流程。我们来总结一下:
- 先通过加密js文件获取到
gid,callback参数 - 根据
https://passport.baidu.com/v2/api/?getapi&...这个(get)请求获取到token - 根据
https://passport.baidu.com/v2/getpublickey?token=...这个(get)请求获取到rsakey和pubkey - 根据获取到的
pubkey对password进行加密,然后再进行base64编码操作 - 将所有固定和构造的参数进行post请求,post请求的url为
https://passport.baidu.com/v2/api/?login,如果该post返回err_no=0,那么模拟登陆就成功了,否则则失败,会返回响应的err_no
前面费了这么大的力气分析百度的登录流程,如果实在是想走捷径的,可以使用selenium自动化的方式登录,这个我也给了相关实现。读过我的新浪微博模拟登陆的同学大概对介于直接登录和使用selenium自动化登录之间的方法还有一些印象吧,这里我并没有使用该方法,因为如果要使用该方法的话,需要改动一些js来使代码跑通。有兴趣的同学可以试试,应该比较有意思。
如果有同学感觉本文有一些难度,可以尝试一些简单的模拟登陆,比如知乎和CSDN等,我写过一篇关于CSDN模拟登陆的文章,微博模拟登陆应该比本文的分析难度稍微要小一点,如果有兴趣,也可以读读。
我把代码放到我的开源项目smart_login上了,点击这里可以查看百度模拟登陆流程的实现,如果有不清楚的同学,建议对照代码再来读本文,可能会更加清晰,如果实际动手按本文的分析流程
走一遍,那么可能会有一些收获。
如果大家觉得本文对大家有帮助,不妨点个喜欢,如果代码对大家有帮助,也不妨点个star,以表示对我的鼓励吧。爱给别人点赞的孩子,运气始终不会太差。