上一篇写了如何从DB获取预期、实际结果,这一篇分别对不同情况说下怎么进行对比。
PS:这部分在JSON对比中也适用。
1、结果只有一张表,只有一条数据
数据格式:因为返回的是dicts_list的格式,因此一条数据时,格式为[dict],可以通过list[0]的方式取到dict,也可以for循环遍历list取dict。
预期结果:id_预期 + 录入的数据 + 代码自动生成的:如createtime
实际结果:id_实际 + 录入的数据 + 代码自动生成的:如createtime
很显然,录入的数据部分是要校验的内容,那么在实现上可以有两种思路:
PS:下面dict1、dict2假设为取到的预期、实际结果
1)新建两个dict,要校验哪些字段,分别从预期结果、实际结果中取那些字段,分别塞入两个dict中,然后进行校验


PS:dict是无序的,因此上面图中dict4故意先把key2放前面,但dict3和dict4还是相等的。
2)把多余的字段从预期结果、实际结果中移除,然后对比剩下的值
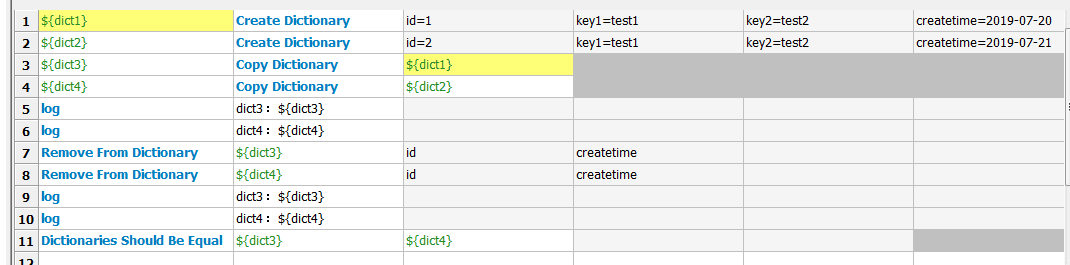
这里我们先通过Copy Dictionary复制一下dict1、2,不去动原dict,然后移除dict3、4中的id、createtime,然后做对比,看一下结果

上面展示了数据一致的情况,我们改一下数据,看一下数据不同时,脚本的提示,先改掉预期结果中key2对应的value

执行结果如下图,可以看到问题定位很清晰

2、结果只有一张表,多条数据,容易排序
数据格式:因为返回的是dicts_list的格式,因为是可以排序的,所以预期、实际结果的数据顺序可以一致,假设都为[dict1,dict2……]
先仿照下结果:


其中dict部分同单条数据,也是要校验其中录入的数据部分。
分别处理预期、实际结果中的dict,处理思路同单条数据,这里只拿一种来说明

结果如下
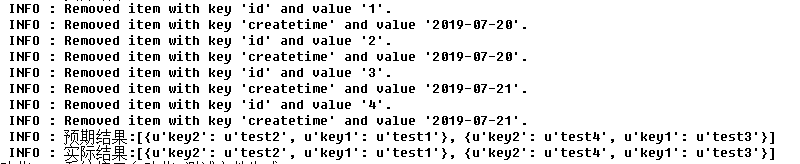
断言,因为是list,所以可以用Lists Should Be Equal
数据一致,case执行通过

我们也一样改一下数据,看下遇到不一致时的提示,先给实际结果加一条数据,即实际数据比预期数据多一条

结果如下图,提示还是比较清楚
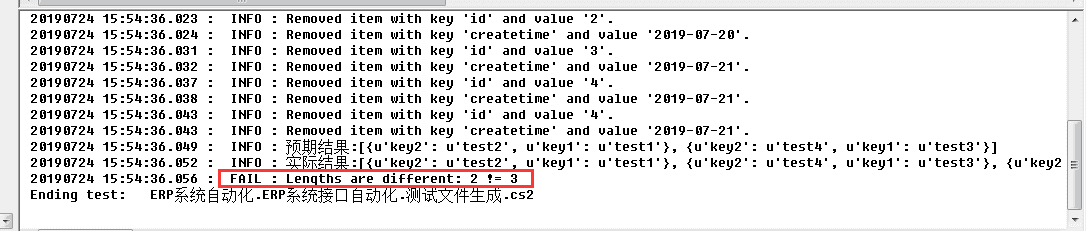
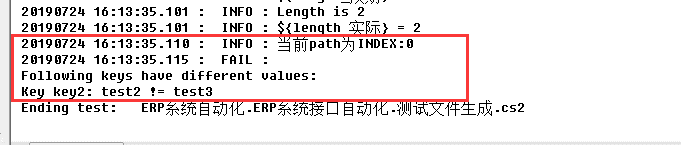
再试下一样的条数,但是其中数据不一致的情况,如下图,把dict实际_2的key2的值改成了test3

执行结果如下图,发现提示了错误,但是提示定位不够清晰,可以想象,如果字段数到了10几,20几,就很难找到哪里错了。如果可以像1中,提示具体是哪个字段错就比较好了。
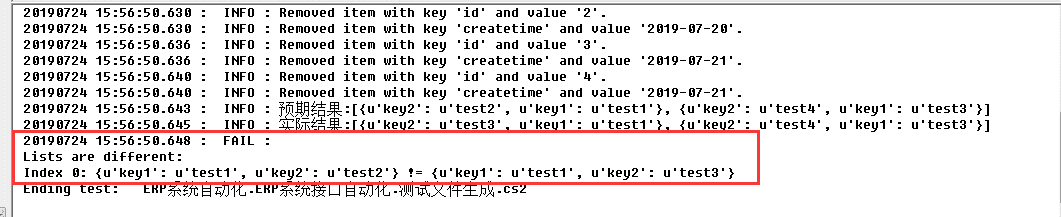
我们修改下判断,先分别获取两个list的长度,判断长度是否一致,然后在for循环遍历list,对dict进行判断
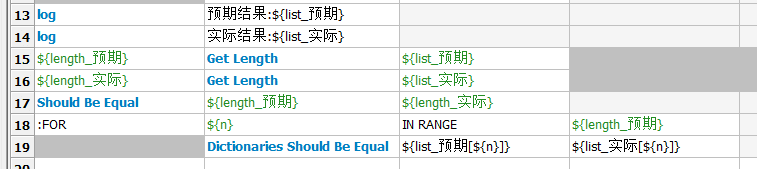
结果如下图,发现成功定位了哪个字段不同,但是又有个问题,看不出来是哪条数据的这个字段不等

在断言前面,加个index的log看下

结果如下,定位比较清晰了
3、结果只有一张表,多条数据,数据乱序,难排序,但是可以获取到他们id间的关联关系
先构造下场景,如下图,预期_1的数据对应实际_2,预期_2的数据对应实际_1,他们之间通过id关联

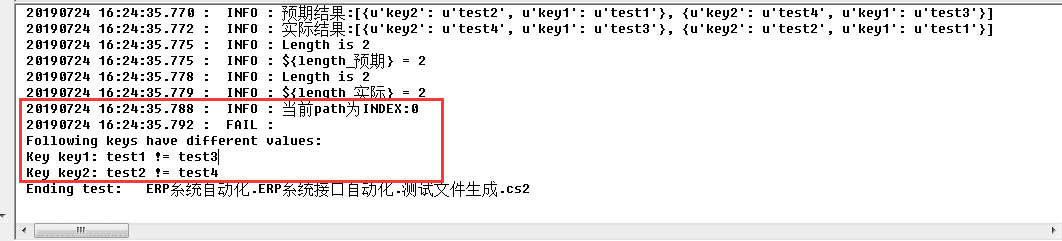
1)依然考虑排序
因为list是有序的,因此用2中的方法,执行后报如下错
我们做下调整(下面实现方法比较笨,如果有好的方法,请大佬们指教)
先把预期、实际结果改成{id1:dict1,id2:dict2……}格式的dict

结果如下图
然后根据预期、实际结果的关联关系,即${dict_预期_实际_关联},对数据做下排序

排序后则判断方式同2,结果如下

2)不考虑排序
for循环遍历其中一个list,若值在另一个list中,则两个list都移除该值,则两个list留下的都是对方没有的值。

两个list有值不等时,结果如下

4、多表多数据,这里就不细分不能排序的场景了,同3,当做全部都是正常排序
1)第一种方式:分别对各张表对比,则同1、2、3
2)第二种方式:把所有数据组成复杂json,一起判断(多层json嵌套,递归的方式详细判断完整json,该方式也适合接口返回的json串全量判断),考虑内容有点多,再分一篇写。
上一篇 8、大型项目的接口自动化实践记录----DB分别获取预期结果、实际结果
下一篇 9-2、大型项目的接口自动化实践记录----递归判断两个json串是否相等