matplotlib可视化练习
%matplotlib inline
import matplotlib as mpl
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
练习3:餐厅小费情况分析
- 小费和总消费之间的关系(散点图)
- 男性顾客和女性顾客,谁更慷慨(分类箱式图)
- 抽烟与否是否会对小费金额产生影响(分类箱式图)
- 工作日和周末,什么时候顾客给的小费更慷慨(分类箱式图)
- 午饭和晚饭,哪一顿顾客更愿意给小费(分类箱式图)
- 就餐人数是否会对慷慨度产生影响(分类箱式图)
- 性别+抽烟的组合因素对慷慨度的影响(分组柱状图)
data = sns.load_dataset("tips")
data.head()
# 总消费,小费,性别,吸烟与否,就餐星期,就餐时间,就餐人数

Paste_Image.png
小费和总消费之间的关系(散点图)
plt.figure(figsize=(10,10))
plt.scatter(data['total_bill'],data['tip'],color = 'r')

output_28_1.png
男性顾客和女性顾客,谁更慷慨(分类箱式图)
慷慨在这里我的理解仅仅是小费 你也可以画消费+消费的图
sexs = np.unique(data['sex'].values)
sex_money = []
for sex in sexs:
sex_money.append(data[data['sex'] == sex]['tip'].values)
sex_money
[array([ 1.01, 3.61, 5. , 3.02, 1.67, 3.5 , 2.75, 2.23, 3. ,
3. , 2.45, 3.07, 2.6 , 5.2 , 1.5 , 2.47, 1. , 3. ,
3.14, 5. , 2.2 , 1.83, 5.17, 1. , 4.3 , 3.25, 2.5 ,
3. , 2.5 , 3.48, 4.08, 4. , 1. , 4. , 3.5 , 1.5 ,
1.8 , 2.92, 1.68, 2.52, 4.2 , 2. , 2. , 2.83, 1.5 ,
2. , 3.25, 1.25, 2. , 2. , 2.75, 3.5 , 5. , 2.3 ,
1.5 , 1.36, 1.63, 5.14, 3.75, 2.61, 2. , 3. , 1.61,
2. , 4. , 3.5 , 3.5 , 4.19, 5. , 2. , 2.01, 2. ,
2.5 , 3.23, 2.23, 2.5 , 6.5 , 1.1 , 3.09, 3.48, 3. ,
2.5 , 2. , 2.88, 4.67, 2. , 3. ]),
array([ 1.66, 3.5 , 3.31, 4.71, 2. , 3.12, 1.96, 3.23,
1.71, 1.57, 3. , 3.92, 3.71, 3.35, 4.08, 7.58,
3.18, 2.34, 2. , 2. , 4.3 , 1.45, 2.5 , 3.27,
3.6 , 2. , 2.31, 5. , 2.24, 2.54, 3.06, 1.32,
5.6 , 3. , 5. , 6. , 2.05, 3. , 2.5 , 1.56,
4.34, 3.51, 3. , 1.76, 6.73, 3.21, 2. , 1.98,
3.76, 2.64, 3.15, 2.01, 2.09, 1.97, 1.25, 3.08,
4. , 3. , 2.71, 3. , 3.4 , 5. , 2.03, 2. ,
4. , 5.85, 3. , 3. , 3.5 , 4.73, 4. , 1.5 ,
3. , 1.5 , 1.64, 4.06, 4.29, 3.76, 3. , 4. ,
2.55, 5.07, 2.31, 2.5 , 2. , 1.48, 2.18, 1.5 ,
2. , 6.7 , 5. , 1.73, 2. , 2.5 , 2. , 2.74,
2. , 2. , 5. , 2. , 3.5 , 2.5 , 2. , 3.48,
2.24, 4.5 , 10. , 3.16, 5.15, 3.18, 4. , 3.11,
2. , 2. , 3.55, 3.68, 5.65, 3.5 , 6.5 , 3. ,
5. , 2. , 4. , 1.5 , 2.56, 2.02, 4. , 1.44,
2. , 2. , 4. , 4. , 3.41, 3. , 2.03, 2. ,
5.16, 9. , 3. , 1.5 , 1.44, 2.2 , 1.92, 1.58,
3. , 2.72, 2. , 3. , 3.39, 1.47, 3. , 1.25,
1. , 1.17, 5.92, 2. , 1.75])]
fig, ax = plt.subplots()
ax.boxplot(sex_money)
ax.set_xticklabels(sexs)
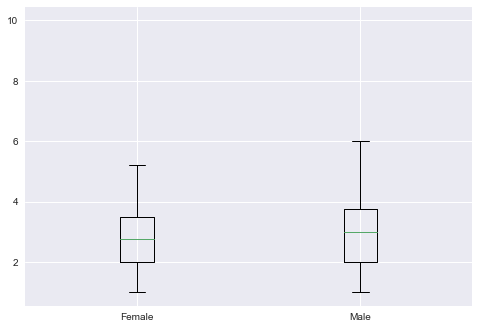
output_32_1.png
抽烟与否是否会对小费金额产生影响(分类箱式图)
smokers = np.unique(data['smoker'].values)
smoker_tip = []
for smoker in smokers:
smoker_tip.append(data[data['smoker'] == smoker]['tip'].values)
smoker_tip
[array([ 1.01, 1.66, 3.5 , 3.31, 3.61, 4.71, 2. , 3.12, 1.96,
3.23, 1.71, 5. , 1.57, 3. , 3.02, 3.92, 1.67, 3.71,
3.5 , 3.35, 4.08, 2.75, 2.23, 7.58, 3.18, 2.34, 2. ,
2. , 4.3 , 3. , 1.45, 2.5 , 3. , 2.45, 3.27, 3.6 ,
2. , 3.07, 2.31, 5. , 2.24, 2.54, 3.06, 1.32, 5.6 ,
3. , 5. , 6. , 2.05, 3. , 2.5 , 2.6 , 5.2 , 1.56,
4.34, 3.51, 1.5 , 6.73, 2.64, 3.15, 2.47, 2.01, 1.97,
3. , 2.2 , 1.25, 4. , 3. , 2.71, 3.4 , 1.83, 2.03,
5.17, 2. , 4. , 5.85, 3. , 3.5 , 3.25, 1.5 , 4.08,
3.76, 3. , 1. , 4. , 2.55, 4. , 3.5 , 5.07, 1.5 ,
1.8 , 2.92, 2.31, 1.68, 2.5 , 2. , 2.52, 4.2 , 1.48,
2. , 2. , 2.18, 1.5 , 2.83, 1.5 , 2. , 3.25, 1.25,
2. , 2. , 2.75, 3.5 , 6.7 , 5. , 5. , 2.3 , 1.5 ,
1.36, 1.63, 1.73, 2. , 2.5 , 2. , 2.74, 2. , 2. ,
5.14, 5. , 3.75, 2.61, 2. , 3.5 , 2.5 , 2. , 2. ,
3.48, 2.24, 4.5 , 5. , 1.44, 9. , 3. , 3. , 2.72,
3.39, 1.47, 1.25, 4.67, 5.92, 1.75, 3. ]),
array([ 3. , 1.76, 3.21, 2. , 1.98, 3.76, 1. , 2.09,
3.14, 5. , 3.08, 3. , 5. , 3. , 1. , 4.3 ,
4.73, 4. , 1.5 , 3. , 2.5 , 3. , 2.5 , 3.48,
1.64, 4.06, 4.29, 4. , 2. , 3. , 1.61, 2. ,
10. , 3.16, 5.15, 3.18, 4. , 3.11, 2. , 2. ,
4. , 3.55, 3.68, 5.65, 3.5 , 6.5 , 3. , 3.5 ,
2. , 3.5 , 4. , 1.5 , 4.19, 2.56, 2.02, 4. ,
2. , 5. , 2. , 2. , 4. , 2.01, 2. , 2.5 ,
4. , 3.23, 3.41, 3. , 2.03, 2.23, 2. , 5.16,
2.5 , 6.5 , 1.1 , 3. , 1.5 , 1.44, 3.09, 2.2 ,
3.48, 1.92, 1.58, 2.5 , 2. , 2.88, 2. , 3. ,
3. , 1. , 1.17, 2. , 2. ])]
fig, ax = plt.subplots()
ax.boxplot(smoker_tip)
ax.set_xticklabels(smokers)

output_35_1.png
工作日和周末,什么时候顾客给的小费更慷慨(分类箱式图)
data.groupby(data['day']).size()
day
Thur 62
Fri 19
Sat 87
Sun 76
dtype: int64
days = np.array(['workday','restday'])
day_tip = []
def change_day(data):
for day in data.values:
if day[4] == 'Sun':
day_tip.append(['restday',day[1]])
else:
day_tip.append(['workday',day[1]])
#
change_day(data)
day_tip = pd.DataFrame(day_tip,columns=['day','tip'])
day_tip

Paste_Image.png
day_tips = []
for day in days:
day_tips.append(day_tip[day_tip['day'] == day]['tip'].values)
day_tips
[array([ 3.35, 4.08, 2.75, 2.23, 7.58, 3.18, 2.34, 2. ,
2. , 4.3 , 3. , 1.45, 2.5 , 3. , 2.45, 3.27,
3.6 , 2. , 3.07, 2.31, 5. , 2.24, 3. , 1.5 ,
1.76, 6.73, 3.21, 2. , 1.98, 3.76, 2.64, 3.15,
2.47, 1. , 2.01, 2.09, 1.97, 3. , 3.14, 5. ,
2.2 , 1.25, 3.08, 4. , 3. , 2.71, 3. , 3.4 ,
1.83, 5. , 2.03, 5.17, 2. , 4. , 5.85, 3. ,
3. , 3.5 , 1. , 4.3 , 3.25, 4.73, 4. , 1.5 ,
3. , 1.5 , 2.5 , 3. , 2.5 , 3.48, 4.08, 1.64,
4.06, 4.29, 3.76, 4. , 3. , 1. , 1.5 , 1.8 ,
2.92, 2.31, 1.68, 2.5 , 2. , 2.52, 4.2 , 1.48,
2. , 2. , 2.18, 1.5 , 2.83, 1.5 , 2. , 3.25,
1.25, 2. , 2. , 2. , 2.75, 3.5 , 6.7 , 5. ,
5. , 2.3 , 1.5 , 1.36, 1.63, 1.73, 2. , 1.61,
2. , 10. , 3.16, 4.19, 2.56, 2.02, 4. , 1.44,
2. , 5. , 2. , 2. , 4. , 2.01, 2. , 2.5 ,
4. , 3.23, 3.41, 3. , 2.03, 2.23, 2. , 5.16,
9. , 2.5 , 6.5 , 1.1 , 3. , 1.5 , 1.44, 3.09,
2.2 , 3.48, 1.92, 3. , 1.58, 2.5 , 2. , 3. ,
2.72, 2.88, 2. , 3. , 3.39, 1.47, 3. , 1.25,
1. , 1.17, 4.67, 5.92, 2. , 2. , 1.75, 3. ]),
array([ 1.01, 1.66, 3.5 , 3.31, 3.61, 4.71, 2. , 3.12, 1.96,
3.23, 1.71, 5. , 1.57, 3. , 3.02, 3.92, 1.67, 3.71,
3.5 , 2.54, 3.06, 1.32, 5.6 , 3. , 5. , 6. , 2.05,
3. , 2.5 , 2.6 , 5.2 , 1.56, 4.34, 3.51, 4. , 2.55,
4. , 3.5 , 5.07, 2.5 , 2. , 2.74, 2. , 2. , 5.14,
5. , 3.75, 2.61, 2. , 3.5 , 2.5 , 2. , 2. , 3. ,
3.48, 2.24, 4.5 , 5.15, 3.18, 4. , 3.11, 2. , 2. ,
4. , 3.55, 3.68, 5.65, 3.5 , 6.5 , 3. , 5. , 3.5 ,
2. , 3.5 , 4. , 1.5 ])]
fig, ax = plt.subplots()
ax.boxplot(day_tips)
ax.set_xticklabels(days)

output_40_1.png
午饭和晚饭,哪一顿顾客更愿意给小费(分类箱式图)
times = np.unique(data['time'].values)
times
array(['Dinner', 'Lunch'], dtype=object)
time_tips = []
for time in times:
time_tips.append(data[data['time'] == time]['tip'].values)
time_tips
[array([ 1.01, 1.66, 3.5 , 3.31, 3.61, 4.71, 2. , 3.12,
1.96, 3.23, 1.71, 5. , 1.57, 3. , 3.02, 3.92,
1.67, 3.71, 3.5 , 3.35, 4.08, 2.75, 2.23, 7.58,
3.18, 2.34, 2. , 2. , 4.3 , 3. , 1.45, 2.5 ,
3. , 2.45, 3.27, 3.6 , 2. , 3.07, 2.31, 5. ,
2.24, 2.54, 3.06, 1.32, 5.6 , 3. , 5. , 6. ,
2.05, 3. , 2.5 , 2.6 , 5.2 , 1.56, 4.34, 3.51,
3. , 1.5 , 1.76, 6.73, 3.21, 2. , 1.98, 3.76,
2.64, 3.15, 2.47, 1. , 2.01, 2.09, 1.97, 3. ,
3.14, 5. , 2.2 , 1.25, 3.08, 3. , 3.5 , 1. ,
4.3 , 3.25, 4.73, 4. , 1.5 , 3. , 1.5 , 2.5 ,
3. , 2.5 , 3.48, 4.08, 1.64, 4.06, 4.29, 3.76,
4. , 3. , 1. , 4. , 2.55, 4. , 3.5 , 5.07,
2.5 , 2. , 2.74, 2. , 2. , 5.14, 5. , 3.75,
2.61, 2. , 3.5 , 2.5 , 2. , 2. , 3. , 3.48,
2.24, 4.5 , 1.61, 2. , 10. , 3.16, 5.15, 3.18,
4. , 3.11, 2. , 2. , 4. , 3.55, 3.68, 5.65,
3.5 , 6.5 , 3. , 5. , 3.5 , 2. , 3.5 , 4. ,
1.5 , 3.41, 3. , 2.03, 2.23, 2. , 5.16, 9. ,
2.5 , 6.5 , 1.1 , 3. , 1.5 , 1.44, 3.09, 3. ,
2.72, 2.88, 2. , 3. , 3.39, 1.47, 3. , 1.25,
1. , 1.17, 4.67, 5.92, 2. , 2. , 1.75, 3. ]),
array([ 4. , 3. , 2.71, 3. , 3.4 , 1.83, 5. , 2.03, 5.17,
2. , 4. , 5.85, 3. , 1.5 , 1.8 , 2.92, 2.31, 1.68,
2.5 , 2. , 2.52, 4.2 , 1.48, 2. , 2. , 2.18, 1.5 ,
2.83, 1.5 , 2. , 3.25, 1.25, 2. , 2. , 2. , 2.75,
3.5 , 6.7 , 5. , 5. , 2.3 , 1.5 , 1.36, 1.63, 1.73,
2. , 4.19, 2.56, 2.02, 4. , 1.44, 2. , 5. , 2. ,
2. , 4. , 2.01, 2. , 2.5 , 4. , 3.23, 2.2 , 3.48,
1.92, 3. , 1.58, 2.5 , 2. ])]
fig, ax = plt.subplots()
ax.boxplot(time_tips)
ax.set_xticklabels(times)

output_44_1.png
就餐人数是否会对慷慨度产生影响(分类箱式图)
size = np.unique(data['size'].values)
size
array([1, 2, 3, 4, 5, 6], dtype=int64)
size_tips = []
for number in size:
size_tips.append(data[data['size'] == number]['tip'].values)
size_tips
[array([ 1. , 1.83, 1. , 1.92]),
array([ 1.01, 3.31, 2. , 1.96, 3.23, 1.71, 1.57, 3.02, 3.92,
4.08, 2.75, 2.23, 3.18, 2. , 2. , 4.3 , 3. , 1.45,
3. , 3.27, 2.54, 3.06, 1.32, 3. , 5. , 3. , 2.5 ,
2.6 , 1.56, 3.51, 1.5 , 1.76, 3.21, 2. , 1.98, 2.47,
2.01, 2.09, 1.97, 3.14, 5. , 2.2 , 1.25, 3.08, 3. ,
2.71, 3. , 3.4 , 5. , 2.03, 2. , 4. , 5.85, 3. ,
3. , 3.5 , 1. , 4.3 , 3.25, 4. , 1.5 , 3. , 1.5 ,
2.5 , 3. , 3.48, 4.08, 1.64, 4.06, 4.29, 3.76, 4. ,
3. , 2.55, 3.5 , 1.5 , 1.8 , 2.31, 1.68, 2.5 , 2. ,
2.52, 1.48, 2. , 2. , 1.5 , 2.83, 1.5 , 2. , 3.25,
1.25, 2. , 2. , 2. , 2.75, 3.5 , 2.3 , 1.5 , 1.63,
1.73, 2. , 2.5 , 2. , 2.61, 2.5 , 2. , 3. , 2.24,
1.61, 2. , 3.16, 5.15, 3.18, 4. , 3.11, 2. , 2. ,
4. , 3.55, 5.65, 3. , 1.5 , 4.19, 2.56, 2.02, 4. ,
1.44, 2. , 2. , 2. , 2.01, 2. , 2.5 , 2.03, 2.23,
2.5 , 1.1 , 1.5 , 1.44, 2.2 , 3.48, 1.58, 2.5 , 2. ,
2.72, 2.88, 3.39, 1.47, 3. , 1.25, 1. , 1.17, 2. ,
2. , 1.75, 3. ]),
array([ 1.66, 3.5 , 1.67, 3.71, 3.5 , 3.35, 3.6 , 2. ,
3.07, 2.31, 5. , 2.24, 2.05, 2.64, 3.15, 3. ,
2.5 , 4. , 4. , 2.18, 1.36, 2.74, 2. , 3.48,
10. , 3.5 , 3.5 , 3.5 , 4. , 4. , 3.23, 3.41,
2. , 6.5 , 3. , 3. , 4.67, 5.92]),
array([ 3.61, 4.71, 3.12, 5. , 3. , 7.58, 2.34, 2.5 , 2.45,
5.6 , 6. , 5.2 , 4.34, 3. , 6.73, 3.76, 4. , 5.17,
4.73, 5.07, 2.92, 2. , 2. , 3.75, 2. , 3.5 , 4.5 ,
3.68, 6.5 , 5. , 4. , 3. , 5.16, 9. , 3.09, 3. , 2. ]),
array([ 5. , 5.14, 5. , 2. , 3. ]),
array([ 4.2, 6.7, 5. , 5. ])]
fig, ax = plt.subplots()
ax.boxplot(size_tips)
ax.set_xticklabels(size)

output_48_1.png
group = data.groupby([data['sex'], data['smoker']])
group_list = np.unique(group.size().index)
group_list
array([('Female', 'No'), ('Female', 'Yes'), ('Male', 'No'), ('Male', 'Yes')], dtype=object)
data['myindex']= data.apply(lambda x:tuple([x[2],x[3]]),axis=1)
data.head()

Paste_Image.png
data_sex_smoker = data[['myindex','tip']]
data_sex_smoker.head()

Paste_Image.png
sex_smoker_tips = []
for group in group_list:
sex_smoker_tips.append(data_sex_smoker[data_sex_smoker['myindex'] == group]['tip'].values)
sex_smoker_tips
[array([ 1.01, 3.61, 5. , 3.02, 1.67, 3.5 , 2.75, 2.23, 3. ,
3. , 2.45, 3.07, 2.6 , 5.2 , 1.5 , 2.47, 3. , 2.2 ,
1.83, 5.17, 3.25, 4.08, 1. , 4. , 3.5 , 1.5 , 1.8 ,
2.92, 1.68, 2.52, 4.2 , 2. , 2. , 2.83, 1.5 , 2. ,
3.25, 1.25, 2. , 2. , 2.75, 3.5 , 5. , 2.3 , 1.5 ,
1.36, 1.63, 5.14, 3.75, 2.61, 2. , 3. , 4.67, 3. ]),
array([ 1. , 3.14, 5. , 1. , 4.3 , 2.5 , 3. , 2.5 , 3.48,
4. , 3. , 1.61, 2. , 4. , 3.5 , 3.5 , 4.19, 5. ,
2. , 2.01, 2. , 2.5 , 3.23, 2.23, 2.5 , 6.5 , 1.1 ,
3.09, 3.48, 2.5 , 2. , 2.88, 2. ]),
array([ 1.66, 3.5 , 3.31, 4.71, 2. , 3.12, 1.96, 3.23, 1.71,
1.57, 3. , 3.92, 3.71, 3.35, 4.08, 7.58, 3.18, 2.34,
2. , 2. , 4.3 , 1.45, 2.5 , 3.27, 3.6 , 2. , 2.31,
5. , 2.24, 2.54, 3.06, 1.32, 5.6 , 3. , 5. , 6. ,
2.05, 3. , 2.5 , 1.56, 4.34, 3.51, 6.73, 2.64, 3.15,
2.01, 1.97, 1.25, 4. , 3. , 2.71, 3.4 , 2.03, 2. ,
4. , 5.85, 3. , 3.5 , 1.5 , 3.76, 3. , 4. , 2.55,
5.07, 2.31, 2.5 , 2. , 1.48, 2.18, 1.5 , 6.7 , 5. ,
1.73, 2. , 2.5 , 2. , 2.74, 2. , 2. , 5. , 2. ,
3.5 , 2.5 , 2. , 3.48, 2.24, 4.5 , 5. , 1.44, 9. ,
3. , 2.72, 3.39, 1.47, 1.25, 5.92, 1.75]),
array([ 3. , 1.76, 3.21, 2. , 1.98, 3.76, 2.09, 3.08,
3. , 5. , 3. , 4.73, 4. , 1.5 , 3. , 1.64,
4.06, 4.29, 2. , 10. , 3.16, 5.15, 3.18, 4. ,
3.11, 2. , 2. , 3.55, 3.68, 5.65, 3.5 , 6.5 ,
3. , 2. , 4. , 1.5 , 2.56, 2.02, 4. , 2. ,
2. , 4. , 4. , 3.41, 3. , 2.03, 2. , 5.16,
3. , 1.5 , 1.44, 2.2 , 1.92, 1.58, 2. , 3. ,
3. , 1. , 1.17, 2. ])]
fig, ax = plt.subplots()
ax.boxplot(sex_smoker_tips)
ax.set_xticklabels(group_list)

output_55_1.png