
前言: 之前总结了 Spring Boot 入门相关的博文,后端开发自然离不开对数据库的操作,所以今天来对数据库操作进行总结。由于刚入门,选择一种使用简单的组件——Jpa。简单到我们不需要写一句 sql 语句。
下面引用官网对 Spring-Data-Jpa 的介绍:
Spring Data JPA 是 Spring Data 系列的一部分,可以轻松实现基于 JPA 的存储库。 该模块处理对基于 JPA 的数据访问层的增强的支持。 这使得使用数据访问技术构建Spring 的应用程序变得更加容易。
如果我们使用原生 JDBC 的方式来访问数据库,那么我们必须编写太多的样板代码。开发效率明显降低,Jpa 则定义了对象关系映射以及实体对象持久化的标准接口,也就是 ORM 框架,相信做过 Java /android 的 oop 编程的人都或多或少的接触过,以面向对象的方式来操作数据库,Spring Data JPA 则在基于 JPA 进一步简化了数据访问层的实现,它提供了一种类似于声明式编程的方式,开发者只需要编写数据访问接口(称为Repository),Spring Data JPA 就能基于接口中的方法命名自动地生成实现。
废话就到这了,注意正式开始使用之前,本地必须装有数据库,以及对数据库基本操作有一定的了解,这里我使用的是 MySql 数据库,安装过程请自行 google ,使用可以参考链接:mysql基本操作命令汇总--笔记
一、 首先添加依赖
org.springframework.boot
spring-boot-starter-data-jpa
mysql
mysql-connector-java
二、数据源配置
在配置文件 application.properties 中添加配置
spring.jpa.show-sql = true
spring.jpa.hibernate.ddl-auto=update
spring.datasource.url=jdbc:mysql://localhost:3306/db_users
spring.datasource.username=root//配置数据库账号
spring.datasource.password=root//配置数据库密码
spring.datasource.driver-class-name=com.mysql.jdbc.Driver//配置MySql驱动
配置解析:
-
spring.datasource.url:配置本地数据库访问地址,默认端口3306,数据库名:db_users -
spring.jpa.show-sql:设置为 true,当我们操作数据库时,会在控制台显示出我们操作对应的 sql 语句,false 则不行。 -
spring.jpa.hibernate.ddl-auto:设置为update,当我们更新数据库的时候,不会删除旧表,如果使用create,更新数据库时,会删除旧表重建,会造成数据丢失。
就这样配置就可以操作数据库了,当然还有更多的配置可以参考下官方文档,我们只需要关注 以spring.datasource,spring.jpa 开头的即可。
三、创建数据表
前面我们说了 Jpa 是 orm 映射型框架。只要我们声明实体类,实体类中的字段就会映射到数据库中自动生成数据表。
新建 User 类:
@Entity//自动映射数据表
public class User {
//id自增
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column
private String username;
@Column
private String password;
public User() {
}
public User(String username, String password) {
this.username = username;
this.password = password;
}
.......此处省略set get方法
}
分析:User 类包含三个字段:
- id作为唯一标识符,
@GeneratedValue(strategy=GenerationType.AUTO)表明id是一个自增字段。 -
username和password为普通字段,@Column注解可有可无 -
@Entity注解:标记在类上,当程序运行,User 类会自动映射到数据库中,生成以User名的数据表,User 类的字段自动映射为数据表的字段。 -
@Table(name = {数据表名}):可有可无,如果我们不喜欢默认用类名作为数据表名,可以使用注解自定义数据表名
运行项目,此时不出意外,服务器启动成功会自动生成```user``数据表

命令行查看,user 数据表已经创建成功~
四、数据表增删改查操作
前面我们提到 Spring-Data-Jpa 提供了一种类似于声明式编程的方式,开发者只需要编写数据访问接口(称为Repository),Spring Data JPA就能基于接口中的方法命名自动地生成实现。
定义 UserRepository 接口,继承JpaRepository,此接口是 Spring-Data-Jpa 内部定义好的泛型接口,第一个参数实体类,第二个参数是ID。已经帮我们实现了基本的增删改查的功能,现在只要持有 UserRepository 就能操作数据表,哈哈~就是如此神奇。。
public interface UserRepository extends JpaRepository{
}
源码分析:进入源码查看接口的继承结构发现 JpaRepository继承自PagingAndSortingRepository继承自CrudRepository继承自Repository
-
Repository:泛型接口,第一个参数是实体类,第二个参数是实体类ID,最顶层接口,不包含任何方法,目的是为了统一所有的Repository的类型,且能让组件扫描的时候自动识别。
public interface Repository {
}
-
CrudRepository:Repository的子接口,封装数据表的 CRUD 方法。
public interface CrudRepository extends Repository {
S save(S var1);//存储一条数据实体
Iterable save(Iterable var1);//批量存储数据
T findOne(ID var1);//根据id查询一条数据实体
boolean exists(ID var1);//判断指定id是否存在
Iterable findAll();//查询所有的数据
Iterable findAll(Iterable var1);//根据一组id批量查询实体
long count();//返回数据的条数
void delete(ID var1);//根据id删除数据
void delete(T var1);//删除数据
void delete(Iterable var1);//批量删除数据
void deleteAll();//删除所有数据
}
-
PagingAndSortingRepository:CrudRepository的子接口,扩展了分页和排序功能。
public interface PagingAndSortingRepository extends CrudRepository {
Iterable findAll(Sort var1);//根据某个排序获取所有数据
Page findAll(Pageable var1);//根据分页信息获取某一页的数据
}
-
JpaRepository:PagingAndSortingRepository的子接口,增加一些实用的功能, 如批量操作
public interface JpaRepository extends PagingAndSortingRepository {
List findAll(); //获取所有数据,以List的方式返回
List findAll(Sort var1); //根据某个排序获取所有数据,以List的方式返回
List findAll(Iterable var1); //根据一组id返回对应的对象,以List的方式返回
List save(Iterable var1); //将一组对象持久化到数据库中,以List的方式返回
void flush(); //将修改更新到数据库
S saveAndFlush(S var1); //保存数据并将修改更新到数据库
void deleteInBatch(Iterable var1); //批量删除数据
void deleteAllInBatch(); //批量删除所有数据
T getOne(ID var1); //根据id查找并返回一个对象
}
五、实际应用
定义完接口之后,只要拿到接口引用,我们就能轻松完成基本的数据表操作了,现在来试试写几个 url 接口玩玩,体验一下。写接口之前建议先看下文章 Spring Boot 学习总结之 Controller 注解
- 将
UserRepository引用注入UserController,编写POST请求的 url 接口,提交一条表单数据保存到数据表中。
@RestController//处理http请求,返回json格式
@RequestMapping(value = "/users")//配置url,让该类下的所有接口url都映射在/users下
public class UserController {
@Autowired//注入实例
UserRepository userRepository;
@PostMapping(value = "/save")
public User saveUser(@RequestParam(value = "username", required = false, defaultValue = "张少林") String username,
@RequestParam(value = "password", required = false, defaultValue = "123456") String password) {
User user = new User(username, password);
return userRepository.save(user);//保存数据到数据表中,并返回
}
}
此时 url 接口地址可以为:http://127.0.0.1:8080/users/save?username=张少林&password=123456,请求方法:post,结果在界面上显示 json 格式数据:
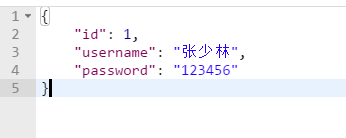
查看数据表 数据已经存入成功:
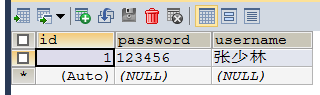
- 我们手动往数据表中添加三条数据,测试一下 查询方法
编写查询所有用户数据 url 接口
@GetMapping(value = "/all")
public List findAll() {
return userRepository.findAll();//查询所有数据并返回
}
url 接口地址:http://127.0.0.1:8080/users/all 请求方法 :GET,结果如下

注意:实体类 User 必须添加空构造方法,否则这里查询会报错
其他的方法就不一一举例了,按照上面源码中的方法依葫芦画瓢就能操作数据表了。那么问题来了,Jpa 内部只帮我们实现了简单的
Crud方法,那么遇到较为复杂自定义条件查询操作咋办呢?,这时候就要用到 Spring-Data 的内建查询机制了。
六、内建查询机制
Spring Data 会识别出find...By, read...By和get...By这样的前缀,从后面的命名中解析出查询的条件。方法命名的的第一个By表示查询条件的开始,多个条件可以通过And和Or来连接。

在 UserRepository 中声明查询方法:
public interface UserRepository extends JpaRepository {
/**
* \根据用户名批量查询用户数据
*
* @param username
* @return
*/
List findByUsername(String username);
}
就是如此简单,只需要在接口中声明对应的查询方法,不需要去实现它,Spring-Data-Jpa 会根据方法名帮我们智能解析为 sql 语句,并且执行查询。
测试:数据库中再手动添加两条相同用户数据,编写 url 请求接口
@GetMapping(value = "/findByUsername")
public List findByUsername(@RequestParam(value = "username", required = false,
defaultValue = "张少林") String username) {
return userRepository.findByUsername(username);//根据用户名批量查询用户数据
}
配置 url 地址 返回结果为:

可以看到控制台打印了 sql 语句:

这也印证了我们之前的观点, Spring-Data-Jpa 自动根据方法名智能帮我们解析 sql 语句并执行查询功能。
除了And和Or,表示查询条件的属性表达式中还可以通过Between 、LessThan、GreaterThan和Like等操作符。 可以使用IngoreCase来忽略属性的大小写,也可以使用AllIgnoreCase来忽略全部属性的大小写。
可以使用OrderBy来进行排序查询,排序的方向是Asc跟Desc。
Spring-Data 为我们提供的关键字见下面表格:
| 关键字 | 例子 | 对应的JPQL语句 |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age ⇐ ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ?1 |
| True | findByActiveTrue() | … where x.active = true |
| False | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
结语:至此,
Spring-Data-Jpa的基本使用总结先告一段落了,虽然还有很多东西没涉及到,但是基于此,再结合 Spring Boot 学习总结之 Controller 注解 我们写简单的后台 json 数据接口已经没啥问题了。
一点点学习总结,一点点思考,如果喜欢,给个赞,谢谢!
如需转载,请注明出处:http://www.jianshu.com/u/52ccd7428abe
参考:
- Spring Data JPA——参考文档
- http://www.cnblogs.com/dreamroute/p/5173896.html
更多原创文章会在公众号第一时间推送,欢迎扫码关注 张少林同学
