首先需要安装Java
下载安装并配置Spark
从官方网站Download Apache Spark™下载相应版本的spark,因为spark是基于hadoop的,需要下载对应版本的hadoop才行,这个页面有对hadoop的版本要求,点击Download Spark: spark-2.3.1-bin-hadoop2.7.tgz就可以下载压缩包了,对应的hadoop版本要在Hadoop2.7及其以后。

这里解压到D:\spark-2.3.1-bin-hadoop2.7,为了后续操作简便,这里将解压以后的文件夹名称改为spark,这样解压的路径就是D:\spark
配置环境变量
右键我的电脑,依次点击属性-高级系统设置-环境变量
新建用户变量 SPARK_HOME D:\spark

找到系统变量Path 点击按钮新建,然后添加文本%SPARK_HOME%\bin,按回车enter,继续新建一个,添加文本%SPARK_HOME%\sbin,按键回车,一直点击确定,就保存了更改,这样就将bin、sbin文件夹中的程序放到了系统变量中
pyspark:到这里spark的配置完成了一部分,还有pyspark需要配置,pyspark等anaconda安装后在下文中讨论,pyspark的安装有几种方式,其中解压以后的spark文件夹中就有pyspark库,可以安装到python的库当中去;还可以不复制,pyspark可以通过pip单独安装,还有一种是单独下载pyspark的安装包,解压以后安装到python库当中去。
安装并配置Hadoop
上面安装spark的时候有对hadoop的版本要求,这里要求的是2.7及以后的版本,进入官方网站Apache Hadoop Releases下载2.7.6 binary版本,其中source版本是该版本hadoop的源代码,下载以后解压到D:\hadoop-2.7.6,为了后续操作方便,解压以后修改文件夹名称为hadoop,这样文件夹就是D:\hadoop

配置环境变量:
右键我的电脑,依次点击属性-高级系统设置-环境变量

新增用户变量 HADOOP_HOME D:\hadoop
然后找到系统变量Path 点击按钮新建,然后添加文本%HADOOP%\bin,按回车enter,继续新建一个,添加文本%HADOOP%\sbin,按键回车,一直点击确定,就保存了更改,这样就将bin、sbin文件夹中的程序放到了系统变量中

从网站中下载点击打开链接一个压缩包,然后解压出来,复制其中的winutils.exe和winutils.pdb到hadoop的安装文件夹中,复制目录为:D:\hadoop\bin,复制到这个目录中
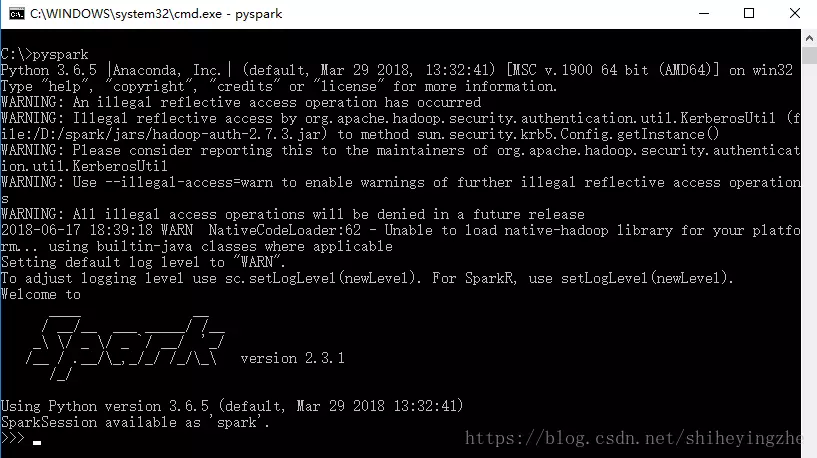
当输入命令pyspark出现以下结果时表明spark安装配置完成了
安装并配置anaconda
在anaconda官方网站中下载并安装对应版本的anaconda,安装路径这里的是C:\Anaconda3.5.2.0,其中需要注意的一点是,需要勾选第一个将anaconda加入环境变量的选项,这样就不需要我们自己将它的路径加入到环境变量中去了
安装anaconda不是必须的,必须安装的是python,单独只安装python也是可以的,但是anaconda当中集成了很多需要用到的库,为了方便起见,这里安装的是anaconda。

配置pyspark库 anaconda包含pyspark
之前在安装spark的时候,提到过pyspark库的安装有几种方法,一种方法是直接将spark自带的pyspark库安装到python的库当中去;一种是使用命令pip install pyspark安装;还有一种是单独下载pyspark的安装包,解压以后安装到python库当中去。这几种方法,这里都会进行讲解。
将spark自带的pyspark库安装到python:
以管理员身份打开cmd,按一下键盘上的window键,依次选中Windows 系统,右键命令提示符,点击更多,点击以管理员身份运行
进入spark安装目录的python文件夹,cd D:\spark\python
C:\>cd D:\spark\python
C:\>d:
D:\spark\python>
输入命令 python setup.py install,等待安装完成,
D:\spark\python>python setup.py install
出现这个图时pyspark就安装好了

pip install pyspark命令行方式安装:
同上面打开cmd的方式相同,需要以管理员身份运行,按一下键盘上的window键,依次选中Windows 系统,右键命令提示符,点击更多,点击以管理员身份运行
输入命令 pip install pyspark,等待安装完成,这里需要注意的是,pyspark本身的安装包占用磁盘空间很多,有几百M,这种方式安装需要在线下载pyspark,网速不错的话,是非常推荐的,这种方式最简单,只需要一行命令就行了。
单独下载安装pyspark:
进入pyspark的PyPI的网站,点击左侧的Download files,下载pyspark的安装包,然后解压好,这里解压的路径是D:\pyspark-2.3.1
同上面打开cmd的方式相同,需要以管理员身份运行,按一下键盘上的window键,依次选中Windows 系统,右键命令提示符,点击更多,点击以管理员身份运行
进入解压以后文件夹的目录
输入命令行 python setup.py install ,等待安装完成,pyspark就安装完成了
D:\pyspark-2.3.1>python setup.py install
以上几种方式都可以安装pyspark,其中最方便的方式是使用命令行 pip install pyspark,下面将讲解pycharm的安装配置过程,并演示一个python编写spark的示例。
安装并配置Pycharm
在Pycharm的官方网站中下载pycharm的community版本,这个版本是免费的,按照默认配置安装就可以
安装好以后打开pycharm,根据自己的喜好配置界面,到这一步时,可以安装一些插件,这里安装的是Markdown
进入打开界面时打开settings
选择好Project Interpreter,点击右侧的下拉链,然后点击show all

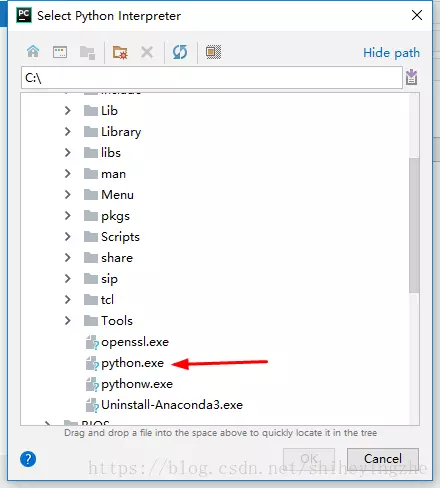
点击+号,添加项目解释器,选中其中的Conda Environment,然后点击Existing environment,点击右侧的选择按钮,进入目录C:\Anaconda3.5.2.0,选中其中的python.exe文件,然后一直点击OK

等待库载入完成以后,点击OK,就完成了Project Interpreter的配置,等待更新完成,或者让它在后台运行




这个是在最开始的时候配置Project Interpreter,进入界面以后,可以在File-Settings或者File-Default_Settings中设置
设置自己的字体,在File-Settings-Editor-Font当中设置
使用python来编写spark的WordCount程序实例流程
新建一个项目,编辑好项目的存放目录以后,需要注意选择Existing interpreter,而不是New interpreter,上一步就是在配置Project interpreter,需要点击选择已经配置好的解释器。新建一个项目还依次点击按钮File-Setting-New Project
等待pycharm配置好,右下角会有提示的,等这个任务完成以后,就可以新建python文件了
点击Create就创建好了一个项目,鼠标放在左侧项目然后右键,依次点击New-Python File,创建一个python文件WordCount.py
进入WordCount.py文件写入如下代码,就是中文版WordCount,很经典的分布式程序,需要用到中文分词库jieba,去除停用词再进行计数
新建两个文件

jieba分词https://pypi.org/project/jieba/#files

下载完后将导入项目中

from pyspark.contextimport SparkContext
import jieba
sc = SparkContext("local", "WordCount")#初始化配置
data = sc.textFile(r"D:\WordCount.txt")#读取是utf-8编码的文件
with open(r'd:\中文停用词库.txt','r',encoding='utf-8')as f:
x=f.readlines()
stop=[i.replace('\n','')for iin x]
print(stop)
stop.extend([',','的','我','他','','。',' ','\n','?',';',':','-','(',')','!','1909','1920','325','B612','II','III','IV','V','VI','—','‘','’','“','”','…','、'])#停用标点之类
data=data.flatMap(lambda line: jieba.cut(line,cut_all=False)).filter(lambda w: wnot in stop).\
map(lambda w:(w,1)).reduceByKey(lambda w0,w1:w0+w1).sortBy(lambda x:x[1],ascending=False)
print(data.take(100))

转自:https://www.jianshu.com/p/c5190d4e8aaa