前几天写好了字典,又刚好重温了KMP算法,恰逢遇到朋友吐槽最近被和谐的词越来越多了,于是突发奇想,想要自己实现一下敏感词屏蔽。
基本敏感词的屏蔽说起来很简单,只要把字符串中的敏感词替换成“***”就可以了。对于子串的查找,就KMP算法就可以了。但是敏感词这么多,总不能一个一个地遍历看看里面有没有相应的词吧!
于是我想到了前几天写的字典树。如果把它改造一下,并KMP算法结合,似乎可以节约不少时间。
首先说明一下思路:
对于KMP算法,这里不过多阐述。对于敏感词库,如果把它存进字典树,并在每个节点存上它的next值。在进行匹配的时候,遍历主串,提取出单个字(对于UTF-8编码,可以是任何国家的字),然后去字典树的根结点的unordered_map中进行查找是否存在。如果不存在,则对下一个字进行相同处理;如果存在,则进入该子节点,然后继续查找。字典树结构如下图:

1~6是编号,后面说明一些东西的时候用到。
Root节点里不存任何数据,只是提供一个词典的起始位置。那个表格用的是unordered_map。
对于一个树型结构,如果直接用KMP算法中的next值来确定下一个应该在哪个节点进行查找似乎会有点问题。比如,对于5号节点,next值为1,但是要怎么用这个"1"进入要查找的节点呢?
由于每个节点只需要知道自己如果匹配失败应该跳到哪个节点,我想了以下两种方案:
1、把next改成存着节点的地址,类似线索二叉树,这样可以很方便地进行节点转换。
2、用栈,每次进入子节点,就对原节点的地址进行压栈,next中存的值是要从栈中弹出几个元素。
由于之前的字典树在遍历的时候采用list实现的栈来确定下一个词是哪个,于是我选择用第二种方案。
方案有了,就是如何实现的事了。
我先对字典树的数据结构进行修改:
DictionaryData.h
1 #ifndef __DICTIONARYDATA_H__ 2 #define __DICTIONARYDATA_H__ 3 4 #include <string> 5 #include6 #include 7 8 namespace ccx{ 9 10 using std::string; 11 using std::unordered_map; 12 using std::shared_ptr; 13 14 struct DictElem 15 { 16 string _word; 17 bool _isend;//是否到词尾 18 int _next;//KMP next值 此处有修改,存的是弹栈数量 19 unordered_map<string, shared_ptr > _words; 20 }; 21 22 typedef shared_ptr pDictElem; 23 24 } 25 26 #endif
相应地,字典树的成员函数也要进行修改。
Dictionary.h
1 #ifndef __DICTIONARY_H__ 2 #define __DICTIONARY_H__ 3 4 #include "DictionaryData.h" 5 #include "DictionaryConf.h" 6 7 #include8 #include 9 #include 10 11 namespace ccx{ 12 13 using std::shared_ptr; 14 using std::vector; 15 using std::list; 16 using std::pair; 17 18 class Dictionary 19 { 20 typedef pair<int, int> Loc; 21 typedef unordered_map<string, pDictElem>::iterator WordIt; 22 public: 23 Dictionary(); 24 void push(const string & word);//插入 25 void push(vector<string> & words);//插入 26 bool search(const string & word);//查找 27 bool associate(const string & word, vector<string> & data);//联想 28 string Kmp(const string & word); 29 30 private: 31 bool Kmp(vector<string> & word, vector
& loc); 32 void getKmpNext(const vector<string> & characters, vector<int> & next); 33 void AddWord(const string & word); 34 void splitWord(const string & word, vector<string> & characters);//把词拆成字 35 int search(vector<string> & data, pDictElem & pcur); 36 pDictElem _dictionary; 37 DictionaryConf _conf; 38 39 //遍历 40 public: 41 string getCurChar(); 42 string getCurWord(); 43 bool isEnd(); 44 void resetIt(); 45 void next(); 46 private: 47 void resetPoint(pDictElem pcur); 48 void next(pDictElem & pcur, list & stackWord, list & stackDict); 49 void nextWord(pDictElem & pcur, list & stackWord, list & stackDict); 50 string getCurWord(list & stackWord); 51 52 pDictElem _pcur; 53 WordIt _itcur; 54 55 //用list实现栈,遍历时方便 56 list _stackWord; 57 list _stackDict; 58 59 //导入导出 60 public: 61 void leading_in(); 62 void leading_out(); 63 }; 64 65 } 66 67 #endif
首先是对插入新词进行修改:
1 void Dictionary::AddWord(const string & word) 2 { 3 vector<string> characters; 4 splitWord(word, characters); 5 vector<int> kmpnext; 6 getKmpNext(characters, kmpnext); 7 8 vector<int>::iterator it_int; 9 it_int = kmpnext.begin(); 10 vector<string>::iterator it_char; 11 it_char = characters.begin(); 12 pDictElem root; 13 root = _dictionary; 14 for(; it_char != characters.end(); ++it_char, ++it_int) 15 { 16 WordIt it_word; 17 it_word = root->_words.find(*it_char); 18 19 if(it_word == root->_words.end()) 20 { 21 pair<string, pDictElem> temp; 22 temp.first = *it_char; 23 pDictElem dictemp(new DictElem); 24 dictemp->_word = *it_char; 25 dictemp->_next = *it_int; 26 dictemp->_isend = false; 27 temp.second = dictemp; 28 root->_words.insert(temp); 29 root = dictemp; 30 }else{ 31 root = it_word->second; 32 } 33 } 34 if(!root->_isend) 35 { 36 root->_isend = true; 37 } 38 }
这里的getKmpNext方法是新加入的,用来求next值:
1 void Dictionary::getKmpNext(const vector<string> & characters, vector<int> & kmpnext) 2 { 3 int size = characters.size(); 4 for(int i = 0; i < size; ++i) 5 { 6 kmpnext.push_back(0); 7 } 8 9 int i = -1; 10 int j = 0; 11 kmpnext[0] = -1; 12 while(j < size) 13 { 14 if(i == -1 || kmpnext[i] == kmpnext[j]) 15 { 16 ++i; 17 ++j; 18 kmpnext[j] = i; 19 }else{ 20 i = kmpnext[i]; 21 } 22 } 23 for(i = 0; i < size; ++i) 24 { 25 kmpnext[i] = i - kmpnext[i]; 26 } 27 }
第4~7行可以用vector 的resize方法,直接修改它的容量。
22行之前就是用来求KMP算法的next数组的,后几行是求弹栈数量的。
举个例子:
对于模式串“编程软件”,next数组为:-1 0 0 0,弹栈数量为1 1 2 3。如:
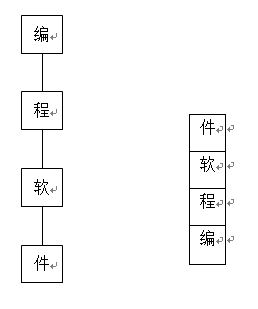 字典树 栈
字典树 栈
此时若匹配不成功,则要把“件”、“软”、“程”全弹出来。当“编”也不匹配时,弹出,重新在root中的unordered_map中查找。
进行匹配的代码如下:
1 bool Dictionary::Kmp(vector<string> & word, vector& loc) 2 { 3 pDictElem root = _dictionary; 4 list stackDict; 5 6 int start = 0; 7 int size = word.size(); 8 int i = 0; 9 while(i < size) 10 { 11 WordIt it_word; 12 it_word = root->_words.find(word[i]); 13 if(it_word == root->_words.end()) 14 { 15 if(stackDict.size()) 16 { 17 int num = root->_next; 18 for(int j = 0; j < num - 1; ++j) 19 { 20 stackDict.pop_back(); 21 } 22 root = stackDict.back(); 23 stackDict.pop_back(); 24 start += num; 25 }else{ 26 ++i; 27 start = i; 28 } 29 continue; 30 }else{ 31 stackDict.push_back(root); 32 root = it_word->second; 33 if(root->_isend) 34 { 35 Loc loctemp; 36 loctemp.first = start; 37 loctemp.second = i; 38 loc.push_back(loctemp); 39 start = i + 1; 40 } 41 } 42 ++i; 43 } 44 return loc.size(); 45 }
形参中,word是把主串拆成字后的集合,loc是要传出的参数,参数内容为所有的敏感词的起始位置与结束位置。外层还有一层封装:
1 string Dictionary::Kmp(const string & word) 2 { 3 vector<string> temp; 4 splitWord(word, temp); 5 vectorloc; 6 7 if(!Kmp(temp, loc)) 8 { 9 return word; 10 } 11 int size = loc.size(); 12 for(int i = 0; i < size; ++i) 13 { 14 for(int j = loc[i].first; j <= loc[i].second; ++j) 15 { 16 temp[j] = "*"; 17 } 18 } 19 string ret; 20 for(auto & elem : temp) 21 { 22 ret += elem; 23 } 24 return ret; 25 }
在这里,调用之前写的splitWord方法对主串进行分字操作,并且把敏感词替换成“*”,然后把结果传出。
这些写完差不多就可以用了。以下是测试内容:
敏感词设定为“好好玩耍”、“编程软件”、“编程学习”、“编程学习网站”、“编程训练”、“编程入门”六个词。
主串设定为“我不要好好玩耍好好进行编程学习然后建一个编程编程编程学习网站给编程纩编程软件者使用进行编程训练与编程学习”。
测试结果如下:
我不要好好玩耍好好进行编程学习然后建一个编程编程编程学习网站给编程纩编程软件者使用进行编程训练与编程学习
我不要****好好进行****然后建一个编程编程******给编程纩****者使用进行****与****
那么,如果机智的小伙伴在敏感词中间加了空格要怎么办呢?
我又想到两种方案:
方案一,在分字之后删除空格。
空格只占一个字节,但是在splitWord中也会被当成字存进vector,此时用erase+remore_if删除即可:
1 bool deleterule(string & word) 2 { 3 return word == " "; 4 } 5 6 string Dictionary::Kmp(const string & word) 7 { 8 vector<string> temp; 9 splitWord(word, temp); 10 11 temp.erase(std::remove_if(temp.begin(), temp.end(), deleterule)); 12 13 vectorloc; 14 15 if(!Kmp(temp, loc)) 16 { 17 return word; 18 } 19 int size = loc.size(); 20 for(int i = 0; i < size; ++i) 21 { 22 for(int j = loc[i].first; j <= loc[i].second; ++j) 23 { 24 temp[j] = "*"; 25 } 26 } 27 string ret; 28 for(auto & elem : temp) 29 { 30 ret += elem; 31 } 32 return ret; 33 }
测试如下:
我不要好好 玩耍好好进行编程学习然后建一个编程编程编程学 习网站给编程纩编程软件者使用进行编程训练与编程学习
我不要****好好进行****然后建一个编程编程******给编程纩****者使用进行****与****
方案二,在匹配的时候读到空格就跳过:
1 bool Dictionary::Kmp(vector<string> & word, vector& loc) 2 { 3 pDictElem root = _dictionary; 4 list stackDict; 5 6 int start = 0; 7 int size = word.size(); 8 int i = 0; 9 while(i < size) 10 { 11 if(word[i] == " ") 12 { 13 ++i; 14 if(!stackDict.size()) 15 { 16 ++start; 17 } 18 continue; 19 } 20 WordIt it_word; 21 it_word = root->_words.find(word[i]); 22 if(it_word == root->_words.end()) 23 { 24 if(stackDict.size()) 25 { 26 int num = root->_next; 27 for(int j = 0; j < num - 1; ++j) 28 { 29 stackDict.pop_back(); 30 } 31 root = stackDict.back(); 32 stackDict.pop_back(); 33 start += num; 34 }else{ 35 ++i; 36 start = i; 37 } 38 continue; 39 }else{ 40 stackDict.push_back(root); 41 root = it_word->second; 42 if(root->_isend) 43 { 44 Loc loctemp; 45 loctemp.first = start; 46 loctemp.second = i; 47 loc.push_back(loctemp); 48 start = i + 1; 49 } 50 } 51 ++i; 52 } 53 return loc.size(); 54 }
测试:
我不要好好 玩耍好好进行编程学习然后建一个编程编程编程学 习网站给编程纩编程软件者使用进行编程训练与编程学习
我不要*****好好进行****然后建一个编程编程**********给编程纩****者使用进行****与****
一开始的时候的BUG:
1、“编程编程编程学习”无法提取出“编程学习”
2、敏感词起始位置乱七八糟
3、弹栈时机乱七八糟
4、敏感词中同时存在“编程学习”与“编程学习网站”时会发生段错误
5、4解决了之后,会出现只匹配“编程学习”,而“网站”二字没有替换
1~4 BUG调整一下就可以了,至于5嘛,莫明其妙就可以了,我也不知道怎么回事。
Dictionary.cc
1 #include "Dictionary.h" 2 #include3 #include 4 #include 5 #include <string> 6 #include 7 8 #define PLAN1 9 10 namespace ccx{ 11 12 using std::endl; 13 using std::cout; 14 using std::pair; 15 using std::ofstream; 16 using std::ifstream; 17 18 Dictionary::Dictionary() 19 : _dictionary(new DictElem) 20 , _conf() 21 { 22 _dictionary->_isend = false; 23 _dictionary->_next = 0; 24 _pcur = _dictionary; 25 } 26 27 void Dictionary::splitWord(const string & word, vector<string> & characters) 28 { 29 int num = word.size(); 30 int i = 0; 31 while(i < num) 32 { 33 int size = 1; 34 if(word[i] & 0x80) 35 { 36 char temp = word[i]; 37 temp <<= 1; 38 do{ 39 temp <<= 1; 40 ++size; 41 }while(temp & 0x80); 42 } 43 string subWord; 44 subWord = word.substr(i, size); 45 characters.push_back(subWord); 46 i += size; 47 } 48 } 49 50 void Dictionary::getKmpNext(const vector<string> & characters, vector<int> & kmpnext) 51 { 52 int size = characters.size(); 53 for(int i = 0; i < size; ++i) 54 { 55 kmpnext.push_back(0); 56 } 57 58 int i = -1; 59 int j = 0; 60 kmpnext[0] = -1; 61 while(j < size) 62 { 63 if(i == -1 || kmpnext[i] == kmpnext[j]) 64 { 65 ++i; 66 ++j; 67 kmpnext[j] = i; 68 }else{ 69 i = kmpnext[i]; 70 } 71 } 72 for(i = 0; i < size; ++i) 73 { 74 kmpnext[i] = i - kmpnext[i]; 75 } 76 } 77 78 void Dictionary::AddWord(const string & word) 79 { 80 vector<string> characters; 81 splitWord(word, characters); 82 vector<int> kmpnext; 83 getKmpNext(characters, kmpnext); 84 85 vector<int>::iterator it_int; 86 it_int = kmpnext.begin(); 87 vector<string>::iterator it_char; 88 it_char = characters.begin(); 89 pDictElem root; 90 root = _dictionary; 91 for(; it_char != characters.end(); ++it_char, ++it_int) 92 { 93 WordIt it_word; 94 it_word = root->_words.find(*it_char); 95 96 if(it_word == root->_words.end()) 97 { 98 pair<string, pDictElem> temp; 99 temp.first = *it_char; 100 pDictElem dictemp(new DictElem); 101 dictemp->_word = *it_char; 102 dictemp->_next = *it_int; 103 dictemp->_isend = false; 104 temp.second = dictemp; 105 root->_words.insert(temp); 106 root = dictemp; 107 }else{ 108 root = it_word->second; 109 } 110 } 111 if(!root->_isend) 112 { 113 root->_isend = true; 114 } 115 } 116 117 void Dictionary::push(const string & word) 118 { 119 AddWord(word); 120 } 121 122 void Dictionary::push(vector<string> & words) 123 { 124 int size = words.size(); 125 for(int i = 0; i < size; ++i) 126 { 127 push(words[i]); 128 } 129 } 130 131 bool Dictionary::search(const string & word) 132 { 133 pDictElem root = _dictionary; 134 vector<string> temp; 135 splitWord(word, temp); 136 137 int ret = search(temp, root); 138 int size = temp.size(); 139 if(ret != size) 140 { 141 return false; 142 } 143 return true; 144 } 145 146 int Dictionary::search(vector<string> & characters, pDictElem & root) 147 { 148 vector<string>::iterator it_char; 149 it_char = characters.begin(); 150 root = _dictionary; 151 int i = 0; 152 for(; it_char != characters.end(); ++it_char, ++i) 153 { 154 WordIt it_word; 155 it_word = root->_words.find(*it_char); 156 157 if(it_word == root->_words.end()) 158 { 159 break; 160 }else{ 161 root = it_word->second; 162 } 163 } 164 return i; 165 } 166 167 bool Dictionary::associate(const string & word, vector<string> & data) 168 { 169 pDictElem root = _dictionary; 170 vector<string> temp; 171 splitWord(word, temp); 172 173 int ret = search(temp, root); 174 int size = temp.size(); 175 if(ret != size) 176 { 177 return false; 178 } 179 180 list stackWord; 181 list stackDict; 182 next(root, stackWord, stackDict); 183 while(root) 184 { 185 string temp = getCurWord(stackWord); 186 data.push_back(temp); 187 next(root, stackWord, stackDict); 188 } 189 190 if(!data.size()) 191 { 192 return false; 193 } 194 return true; 195 } 196 197 #ifdef PLAN1 198 //敏感词中带空格的第一种方案 199 bool deleterule(string & word) 200 { 201 return word == " "; 202 } 203 #endif 204 205 string Dictionary::Kmp(const string & word) 206 { 207 vector<string> temp; 208 splitWord(word, temp); 209 210 #ifdef PLAN1 211 temp.erase(std::remove_if(temp.begin(), temp.end(), deleterule)); 212 #endif 213 214 vector loc; 215 216 if(!Kmp(temp, loc)) 217 { 218 return word; 219 } 220 int size = loc.size(); 221 for(int i = 0; i < size; ++i) 222 { 223 for(int j = loc[i].first; j <= loc[i].second; ++j) 224 { 225 temp[j] = "*"; 226 } 227 } 228 string ret; 229 for(auto & elem : temp) 230 { 231 ret += elem; 232 } 233 return ret; 234 } 235 236 bool Dictionary::Kmp(vector<string> & word, vector & loc) 237 { 238 pDictElem root = _dictionary; 239 list stackDict; 240 241 int start = 0; 242 int size = word.size(); 243 int i = 0; 244 while(i < size) 245 { 246 #ifdef PLAN2 247 //敏感词中带空格的第二种方案 248 if(word[i] == " ") 249 { 250 ++i; 251 if(!stackDict.size()) 252 { 253 ++start; 254 } 255 continue; 256 } 257 #endif 258 WordIt it_word; 259 it_word = root->_words.find(word[i]); 260 if(it_word == root->_words.end()) 261 { 262 if(stackDict.size()) 263 { 264 int num = root->_next; 265 for(int j = 0; j < num - 1; ++j) 266 { 267 stackDict.pop_back(); 268 } 269 root = stackDict.back(); 270 stackDict.pop_back(); 271 start += num; 272 }else{ 273 ++i; 274 start = i; 275 } 276 continue; 277 }else{ 278 stackDict.push_back(root); 279 root = it_word->second; 280 if(root->_isend) 281 { 282 Loc loctemp; 283 loctemp.first = start; 284 loctemp.second = i; 285 loc.push_back(loctemp); 286 start = i + 1; 287 } 288 } 289 ++i; 290 } 291 return loc.size(); 292 } 293 294 //遍历用 295 296 void Dictionary::resetPoint(pDictElem pcur) 297 { 298 _pcur = pcur; 299 if(_stackDict.size()) 300 { 301 _stackDict.clear(); 302 } 303 if(_stackWord.size()) 304 { 305 _stackWord.clear(); 306 } 307 next(); 308 } 309 310 void Dictionary::resetIt() 311 { 312 resetPoint(_dictionary); 313 } 314 315 void Dictionary::next() 316 { 317 next(_pcur, _stackWord, _stackDict); 318 } 319 320 void Dictionary::next(pDictElem & pcur, list & stackWord, list & stackDict) 321 { 322 while(pcur) 323 { 324 nextWord(pcur, stackWord, stackDict); 325 if(!pcur || pcur->_isend) 326 { 327 break; 328 } 329 } 330 } 331 332 void Dictionary::nextWord(pDictElem & pcur, list & stackWord, list & stackDict) 333 { 334 if(pcur) 335 { 336 if(pcur->_words.size()) 337 { 338 stackDict.push_back(pcur); 339 stackWord.push_back(pcur->_words.begin()); 340 pcur = stackWord.back()->second; 341 }else{ 342 ++(stackWord.back()); 343 } 344 while(stackWord.back() == stackDict.back()->_words.end()) 345 { 346 stackDict.pop_back(); 347 stackWord.pop_back(); 348 if(!stackDict.size()) 349 { 350 pcur = NULL; 351 } 352 ++(stackWord.back()); 353 } 354 if(pcur) 355 { 356 pcur = stackWord.back()->second; 357 } 358 } 359 } 360 361 string Dictionary::getCurChar() 362 { 363 return _pcur->_word; 364 } 365 366 string Dictionary::getCurWord() 367 { 368 return getCurWord(_stackWord); 369 } 370 371 string Dictionary::getCurWord(list & stackWord) 372 { 373 string temp; 374 list ::iterator it_word; 375 it_word = stackWord.begin(); 376 377 for(; it_word != stackWord.end(); ++it_word) 378 { 379 temp += (*it_word)->first; 380 } 381 return temp; 382 } 383 384 bool Dictionary::isEnd() 385 { 386 return _pcur == NULL; 387 } 388 389 void Dictionary::leading_in()//导入,失败没必要退出程序 390 { 391 ifstream ifs; 392 const char * path = _conf.getDictionaryPath().c_str(); 393 ifs.open(path); 394 if(!ifs.good()) 395 { 396 cout << "open Dictionary.json error(leading_in)" << endl; 397 }else{ 398 Json::Value root; 399 Json::Reader reader; 400 401 if(!reader.parse(ifs, root, false)) 402 { 403 cout << "json read Dictionary.json error" << endl; 404 }else{ 405 int size = root.size(); 406 for(int i = 0; i < size; ++i) 407 { 408 string word = root[i]["Word"].asString(); 409 AddWord(word); 410 } 411 } 412 } 413 } 414 415 void Dictionary::leading_out() 416 { 417 Json::Value root; 418 Json::FastWriter writer; 419 420 resetIt(); 421 422 while(!isEnd()) 423 { 424 Json::Value elem; 425 elem["Word"] = getCurWord(); 426 root.append(elem); 427 next(); 428 } 429 430 string words; 431 words = writer.write(root); 432 433 ofstream ofs; 434 const char * path = _conf.getDictionaryPath().c_str(); 435 ofs.open(path); 436 if(!ofs.good()) 437 { 438 cout << "open Dictionary.json error(leading_out)" << endl; 439 ofs.open("Dictionary.tmp"); 440 if(!ofs.good()) 441 { 442 exit(EXIT_FAILURE); 443 } 444 } 445 446 ofs << words; 447 ofs.close(); 448 } 449 450 }
github:https://github.com/ccx19930930/KMP_with_Dictionary
结论:我的词典真的成了胖接口了!!!