一、pandas介绍
本篇程序上篇内容,在numpy下面继续介绍pandas,本书的作者是pandas的作者之一。pandas是非常好用的数据预处理工具,pandas下面有两个数据结构,分别为Series和DataFrame,DataFrame之前我在一些实战案例中有用过,下面先对这两个数据结构做介绍。
二、Series
Series最简单的一个功能就是对一组数字打上ID,用法为下

可以看到Series会自动把数字打上0~3对应的ID,也可以对ID自定义名称

这样就可以用key-value的形式将序列里的值调出,也可透过索引来修改值,比如obj2['d'] = 2
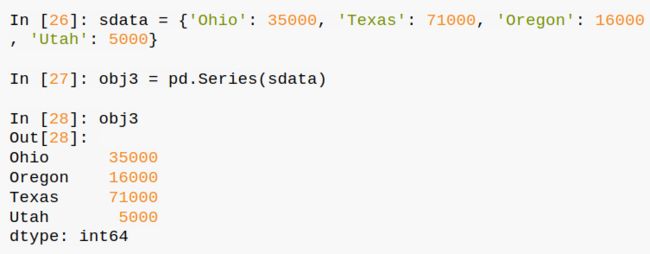
如果将字典导入,由于字典本身就是key-value对应的格式,所以Series也会继续沿用这种对应方式
三、DataFrame
1、表的基本操作
Dataframe同样也是可以将字典导入,并会对字典做索引,如下


对于数据量较大的资料,可以用head( )来查看前五项的数据。
使用frame['列名称']或是frame.列名称的方式查看某一列的数据。使用frame.loc['索引值']可以查看某一行的数据。而frame.values则可以看到完整的行列数据
可以对选取的值进行修改,例如frame['year'] = 2000会把年份都修改成2000,del frame['year']则会把year这一列删除, drop('1')会把这行数据删除
如果字典导入时某个值缺失了会用NaN来表示
另外如果导入的是嵌套式字典的话则会把第一层当做列,第二层的key为行,下面为嵌套式的案例


可以看到第一层的Nevada和Ohio为列,第二层的key 2000,2001,2002 为列,缺失的数据显示为NaN
DataFrame可以对行和列做编辑,frame = pd.DataFrame(np.arange(9).reshape(3,3), index = [ 'a', 'c', 'd' ], colume = ['Ohio', 'Texas', 'California']),就会成为下面的矩阵
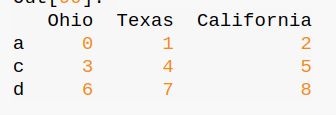
2、计算
当DataFrame对两个表进行运算时,假设一个表某个值要和另外一个表的值做计算,但是其中有一个值为空缺值(NaN),那运算的结果就会是空缺值(NaN),例如5+NaN = NaN,下面为范例说明



为了避免这种情况发生,我们会希望系统可以假设这个不存在的值为0,这样我们的缺失值才不会在计算过程中扩散,我们希望的是5+NaN = 5, 所以就需要让pandas在做运算的时候对缺失值补上数字,方法为在运算指令后面加上fill_value这个选项。
![]()
另外在做矩阵的计算时,如果是对单行做计算,则会使用广播,对每行都进行一次计算,如下图

3、排序
DataFrame也可以利用sort进行排序,默认的排序方式是由小到大,最后是NaN。可以指定以某列为基准进行排列,如下图就是以b这一列为基准进行排列

另外还有一种排序方式称为rank,他可以为Series里面的每个值大小做排序,并给与由小到大的评分(从1开始),如下图,由于第2行的-5最小,所以rank值为1,再依序增加。

4、重复标签索引
和关系型数据库的唯一索引不同,pandas可以使用重复的索引,可使用以下代码查看表索引是否有重复的值

使用索引查找数据时,pandas会将所有相同索引的值都返回

5、统计
pandas支援各式各样的统计,有常见的sum、mean、count等,可以可以查看图表的各种统计数据,下面为几个统计的指令
