原创文章~转载请注明出处哦。其他部分内容参见以下链接~
GraphSAGE 代码解析(一) - unsupervised_train.py
GraphSAGE 代码解析(二) - layers.py
GraphSAGE 代码解析(三) - aggregators.py
1. 类及其继承关系
Model / \ / \ MLP GeneralizedModel / \ / \ Node2VecModel SampleAndAggregate
首先看Model, GeneralizedModel, SampleAndAggregate这三个类的联系。
其中Model与 GeneralizedModel的区别在于,Model的build()函数中搭建了序列层模型,而在GeneralizedModel中被删去。self.ouput必须在GeneralizedModel的子类build()中被赋值。
class Model(object) 中的build()函数如下:
1 def build(self): 2 """ Wrapper for _build() """ 3 with tf.variable_scope(self.name): 4 self._build() 5 6 # Build sequential layer model 7 self.activations.append(self.inputs) 8 for layer in self.layers: 9 hidden = layer(self.activations[-1]) 10 self.activations.append(hidden) 11 self.outputs = self.activations[-1] 12 # 这部分sequential layer model模型在GeneralizedModel的build()中被删去 13 14 # Store model variables for easy access 15 variables = tf.get_collection( 16 tf.GraphKeys.GLOBAL_VARIABLES, scope=self.name) 17 self.vars = {var.name: var for var in variables} 18 19 # Build metrics 20 self._loss() 21 self._accuracy() 22 23 self.opt_op = self.optimizer.minimize(self.loss)
序列层实现的功能是,给输入,通过layer()返回输出,又将这个输出再次作为输入到下一个layer()中,最终,取最后一层layer的结果作为output.
2. class SampleAndAggregate(GeneralizedModel)
1. __init__():
(1) self.features的由来:
para: features tf.get_variable()-> identity features | | self.features self.embeds --> At least one is not None \ / --> Concat if both are not None \ / \ / self.features
(2) self.dims:
self.dims是一个list, 每一位记录各个神经网络层的维数。
self.dims[0]的值相当于self.features的列数 (0 if features is None else features.shape[1]) + identity_dim),(注意:括号里features为传入的参数,而非self.features)
之后各位为各层output_dim,也就是hidden units的个数。
(3) __init()__函数代码
1 def __init__(self, placeholders, features, adj, degrees, 2 layer_infos, concat=True, aggregator_type="mean", 3 model_size="small", identity_dim=0, 4 **kwargs): 5 ''' 6 Args: 7 - placeholders: Stanford TensorFlow placeholder object. 8 - features: Numpy array with node features. 9 NOTE: Pass a None object to train in featureless mode (identity features for nodes)! 10 - adj: Numpy array with adjacency lists (padded with random re-samples) 11 - degrees: Numpy array with node degrees. 12 - layer_infos: List of SAGEInfo namedtuples that describe the parameters of all 13 the recursive layers. See SAGEInfo definition above. 14 - concat: whether to concatenate during recursive iterations 15 - aggregator_type: how to aggregate neighbor information 16 - model_size: one of "small" and "big" 17 - identity_dim: Set to positive int to use identity features (slow and cannot generalize, but better accuracy) 18 ''' 19 super(SampleAndAggregate, self).__init__(**kwargs) 20 if aggregator_type == "mean": 21 self.aggregator_cls = MeanAggregator 22 elif aggregator_type == "seq": 23 self.aggregator_cls = SeqAggregator 24 elif aggregator_type == "maxpool": 25 self.aggregator_cls = MaxPoolingAggregator 26 elif aggregator_type == "meanpool": 27 self.aggregator_cls = MeanPoolingAggregator 28 elif aggregator_type == "gcn": 29 self.aggregator_cls = GCNAggregator 30 else: 31 raise Exception("Unknown aggregator: ", self.aggregator_cls) 32 33 # get info from placeholders... 34 self.inputs1 = placeholders["batch1"] 35 self.inputs2 = placeholders["batch2"] 36 self.model_size = model_size 37 self.adj_info = adj 38 if identity_dim > 0: 39 self.embeds = tf.get_variable( 40 "node_embeddings", [adj.get_shape().as_list()[0], identity_dim]) 41 # self.embeds: record the neigh features embeddings 42 # number of features = identity_dim 43 # number of neighbors = adj.get_shape().as_list()[0] 44 else: 45 self.embeds = None 46 if features is None: 47 if identity_dim == 0: 48 raise Exception( 49 "Must have a positive value for identity feature dimension if no input features given.") 50 self.features = self.embeds 51 else: 52 self.features = tf.Variable(tf.constant( 53 features, dtype=tf.float32), trainable=False) 54 if not self.embeds is None: 55 self.features = tf.concat([self.embeds, self.features], axis=1) 56 self.degrees = degrees 57 self.concat = concat 58 59 self.dims = [ 60 (0 if features is None else features.shape[1]) + identity_dim] 61 self.dims.extend( 62 [layer_infos[i].output_dim for i in range(len(layer_infos))]) 63 self.batch_size = placeholders["batch_size"] 64 self.placeholders = placeholders 65 self.layer_infos = layer_infos 66 67 self.optimizer = tf.train.AdamOptimizer( 68 learning_rate=FLAGS.learning_rate) 69 70 self.build()
(2) sample(inputs, layer_infos, batch_size=None)
对于sample的算法描述,详见论文Appendix A, algorithm 2.
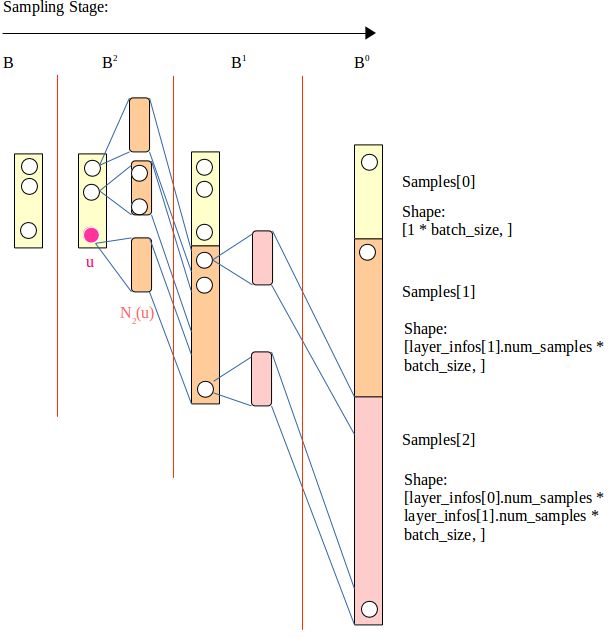
代码:
1 def sample(self, inputs, layer_infos, batch_size=None): 2 """ Sample neighbors to be the supportive fields for multi-layer convolutions. 3 4 Args: 5 inputs: batch inputs 6 batch_size: the number of inputs (different for batch inputs and negative samples). 7 """ 8 9 if batch_size is None: 10 batch_size = self.batch_size 11 samples = [inputs] 12 # size of convolution support at each layer per node 13 support_size = 1 14 support_sizes = [support_size] 15 16 for k in range(len(layer_infos)): 17 t = len(layer_infos) - k - 1 18 support_size *= layer_infos[t].num_samples 19 sampler = layer_infos[t].neigh_sampler 20 21 node = sampler((samples[k], layer_infos[t].num_samples)) 22 samples.append(tf.reshape(node, [support_size * batch_size, ])) 23 support_sizes.append(support_size) 24 25 return samples, support_sizes
sampler = layer_infos[t].neigh_sampler
当函数被调用时,layer_infos会被赋值,在unsupervised_train.py中,其中neigh_sampler被赋为UniformNeighborSampler,其在neigh_samplers.py中定义:class UniformNeighborSampler(Layer)。
目的是对于输入的samples[k] (即为上一步sample得到的节点,如上图依次得到黄色区域表示的samples[0],橙色区域表示的samples[1], 粉色区域表示的samples[2]。其中samples[k]是有由对samples[k - 1]中各节点的邻居采样而得),选取num_samples个数的邻居节点的序号(对应上图N(u))。(返回值是adj_lists, 即为被截断为num_samples列数的邻接矩阵。)
这里注意区别support_size与num_samples:
num_sample为当前深度每个节点u所选取的邻居节点的个数为num_samples;
support_size表示当前节点u的embedding受多少节点信息的影响。其既受当前层num_samples个直接邻居的影响,其邻居也受更先前深度num_samples个邻居的影响,以此类推。故support_size是到目前深度为止的各深度下num_samples的连乘积。则对于batch_size个输入节点,总的support个数为: support_size * batch_size。
最后将support_size存进support_sizes的数组中。
sample() 函数最终返回包含各深度下采样点的samples数组与各深度下各点受支持节点数目的support_sizes数组。
2. def _build(self):
1 self.neg_samples, _, _ = (tf.nn.fixed_unigram_candidate_sampler( 2 true_classes=labels, 3 num_true=1, 4 num_sampled=FLAGS.neg_sample_size, 5 unique=False, 6 range_max=len(self.degrees), 7 distortion=0.75, 8 unigrams=self.degrees.tolist()))
(1) tf.nn.fixed_unigram_candidate_sampler:
按照用户提供的概率分布进行采样。 如果类别服从均匀分布,我们就用uniform_candidate_sampler; 如果词作类别,我们知道词服从 Zipfian, 我们就用 log_uniform_candidate_sampler; 如果能够通过统计或者其他渠道知道类别满足某些分布,用 nn.fixed_unigram_candidate_sampler; 如果实在不知道类别分布,我们还可以用 tf.nn.learned_unigram_candidate_sampler。 (2) Paras: a. num_sampled: sampling_candidates的元素是在没有替换(如果unique = True)的情况下绘制的, 或者是从基本分布中替换(如果unique = False)。 unique = True 可以看作无放回抽样;unique = False 可以看作有放回抽样。 b. distortion: distortion used the word2vec freq energy table formulation f^(3/4) / total(f^(3/4)) in word2vec energy counted by freq; in graphsage energy counted by degrees so in unigrams = [] each ID recored each node's degree c. unigrams: 各个节点的度。 (3) Returns: a. sampled_candidates: A tensor of type int64 and shape [num_sampled]. The sampled classes. b. true_expected_count: A tensor of type float. Same shape as true_classes. The expected counts under the sampling distribution of each of true_classes. c. sampled_expected_count: A tensor of type float. Same shape as sampled_candidates. The expected counts under the sampling distribution of each of sampled_candidates.
-------addtional---------------
1. self.__class__.__name__.lower()
1 if not name:
2 name = self.__class__.__name__.lower()
self.__class__.__name__.lower(): https://stackoverflow.com/questions/36367736/use-name-as-attribute
1 class MyClass:
2 def __str__(self):
3 return str(self.__class__)
>>> instance = MyClass()
>>> print(instance)
__main__.MyClass
That is because the string version of the class includes the module that it is defined in. In this case, it is defined in the module that is currently being executed, the shell, so it shows up as __main__.MyClass. If we use self.__class__.__name__, however:
1 class MyClass:
2 def __str__(self):
3 return self.__class__.__name__
4
5 instance = MyClass()
6 print(instance)
it outputs:
MyClass
The __name__ attribute of the class does not include the module.
Note: The __name__ attribute gives the name originally given to the class. Any copies will keep the name. For example:
1 class MyClass:
2 def __str__(self):
3 return self.__class__.__name__
4
5 SecondClass = MyClass
6
7 instance = SecondClass()
8 print(instance)
output:
MyClass
That is because the __name__ attribute is defined as part of the class definition. Using SecondClass = MyClass is just assigning another name to the class. It does not modify the class or its name in any way.
2. allowed_kwargs = {'name', 'logging', 'model_size'}
其中name,logging,model_size指什么?
name: String, defines the variable scope of the layer.
logging: Boolean, switches Tensorflow histogram logging on/off
model_size: small / big 见aggregates.py: small: hidden_dim =512; big: hidden_dim = 1024
3. python 中参数*args, **kwargs
https://blog.csdn.net/anhuidelinger/article/details/10011013
1 def foo(*args, **kwargs):
2 print 'args = ', args
3 print 'kwargs = ', kwargs
4 print '---------------------------------------'
5
6 if __name__ == '__main__':
7 foo(1,2,3,4)
8 foo(a=1,b=2,c=3) 9 foo(1,2,3,4, a=1,b=2,c=3) 10 foo('a', 1, None, a=1, b='2', c=3) 11 12 # Output: 13 # args = (1, 2, 3, 4) 14 # kwargs = {} 15 16 # args = () 17 # kwargs = {'a': 1, 'c': 3, 'b': 2} 18 19 # args = (1, 2, 3, 4) 20 # kwargs = {'a': 1, 'c': 3, 'b': 2} 21 22 # args = ('a', 1, None) 23 # kwargs = {'a': 1, 'c': 3, 'b': '2'}
1. 可以看到,这两个是python中的可变参数。
*args表示任何多个无名参数,它是一个tuple;
**kwargs表示关键字参数,它是一个 dict。
并且同时使用*args和**kwargs时,必须*args参数列要在**kwargs前.
像foo(a=1, b='2', c=3, a', 1, None, )这样调用的话,会提示语法错误“SyntaxError: non-keyword arg after keyword arg”。
2. 何时使用**kwargs:
Using **kwargs and default values is easy. Sometimes, however, you shouldn't be using **kwargs in the first place.
In this case, we're not really making best use of **kwargs.
1 class ExampleClass( object ):
2 def __init__(self, **kwargs):
3 self.val = kwargs.get('val',"default1")
4 self.val2 = kwargs.get('val2',"default2")
The above is a "why bother?" declaration. It is the same as
1 class ExampleClass( object ):
2 def __init__(self, val="default1", val2="default2"):
3 self.val = val
4 self.val2 = val2
When you're using **kwargs, you mean that a keyword is not just optional, but conditional. There are more complex rules than simple default values.
When you're using **kwargs, you usually mean something more like the following, where simple defaults don't apply.
1 class ExampleClass( object ):
2 def __init__(self, **kwargs):
3 self.val = "default1"
4 self.val2 = "default2"
5 if "val" in kwargs:
6 self.val = kwargs["val"]
7 self.val2 = 2*self.val
8 elif "val2" in kwargs: 9 self.val2 = kwargs["val2"] 10 self.val = self.val2 / 2 11 else: 12 raise TypeError( "must provide val= or val2= parameter values" )
3. logging = kwargs.get('logging', False) : default value: false
https://stackoverflow.com/questions/1098549/proper-way-to-use-kwargs-in-python
You can pass a default value to get() for keys that are not in the dictionary:
1 self.val2 = kwargs.get('val2',"default value")
However, if you plan on using a particular argument with a particular default value, why not use named arguments in the first place?
1 def __init__(self, val2="default value", **kwargs):
4. tf.variable_scope()
https://blog.csdn.net/IB_H20/article/details/72936574
5. masked_softmax_cross_entropy ? 见metrics.py
1 # Cross entropy error
2 if self.categorical:
3 self.loss += metrics.masked_softmax_cross_entropy(self.outputs, self.placeholders['labels'],
4 self.placeholders['labels_mask'])
1 def masked_logit_cross_entropy(preds, labels, mask):
2 """Logit cross-entropy loss with masking."""
3 loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=preds, labels=labels)
4 loss = tf.reduce_sum(loss, axis=1)
5 mask = tf.cast(mask, dtype=tf.float32)
6 mask /= tf.maximum(tf.reduce_sum(mask), tf.constant([1.]))
7 loss *= mask 8 return tf.reduce_mean(loss)
=======================================


感谢您的打赏!
(梦想还是要有的,万一您喜欢我的文章呢)