http://restapi.amap.com 是个URL,叫作统一资源定位符。HTTP称为协议,restapi.amap.com是一个域名,表示互联网上的一个位置。
HTTP版本区别
HTTP/0.9 只支持get请求
HTTP/1.0 增加版本号,请求头,MIME,代理连接
HTTP/1.1 默认持久连接,支持缓存,执行管道方式发送多个请求
HTTP请求的准备
浏览器会将restapi.amap.com这个域名发送给DNS服务器,让它解析为IP地址。那接下来是发送HTTP请求吗?
不是的,HTTP是基于TCP协议的,当然是要先建立TCP连接了,怎么建立呢?Socket网络编程 已经详细讲解了。
目前使用的HTTP协议大部分都是1.1。在1.1的协议里面,默认持久连接,也就是默认开启了Keep-Alive的,这样建立的TCP连接,就可以在多次请求中复用。
学习了TCP之后,你应该知道,TCP的三次握手和四次挥手,还是挺费劲的。如果好不容易建立了连接,然后就做了一点儿事情就结束了,有点儿浪费人力和物力。
HTTP请求的构建
建立了连接以后,浏览器就要发送HTTP的请求。
请求的格式如下: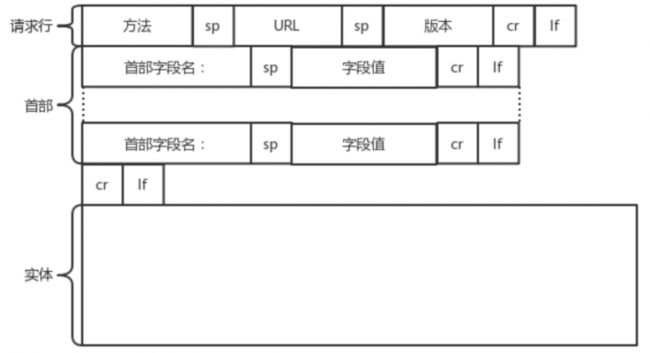
HTTP的报文大概分为三大部分。第一部分是请求行,第二部分是请求的首部,第三部分才是请求的正文实体。
GET /v3/weather/weatherInfo?city=110101&key=13cb58f5884f9749287abbead9c658f2 HTTP/1.1
Host: restapi.amap.com
第一部分:请求行
在请求行中,URL就是请求的地址 ,版本为HTTP 1.1。方法有几种类型,最常用的类型就是GET。
GET就是去服务器获取一些资源。另外一种类型是POST,它需要主动告诉服务端一些信息,而非获取,一般会将信息放在正文里面,正文可以有各种各样的格式,常见的格式也是JSON。
还有一种类型叫PUT,就是向指定资源位置上传最新内容。但是,HTTP的服务器往往是不允许上传文件的,所以PUT和POST就都变成了要传给服务器东西的方法。
再有一种常见的就是DELETE这个顾名思义就是用来删除资源的。
第二部分:首部字段
首部是key: value,通过冒号分隔。这里面,往往保存了一些非常重要的字段。
如,Accept-Charset,表示客户端可以接受的字符集。防止传过来的是另外的字符集,从而导致出现乱码。
如,Content-Type是指正文的格式。我们进行POST的请求,如果正文是JSON,那么我们就应该将这个值设置为JSON。
Content-Type: application/json如,Content-Length是指正文的长度。
Content-Length: 0接下俩重点说一下的就是缓存。
为什么要有缓存呢? 使用缓存可以减少冗余的数据传输,节省了网络费用;还可以缓解网络瓶颈的问题,不需要更多的网络宽带就能更快的加载页面,同时降低了对原始服务器的要求,服务器可以更快的响应。
例如,我浏览一个商品的详情,里面有这个商品的价格、库存、展示图片、使用手册等等。商品的展示图片会保持较长时间不变,而库存会根据用户购买的情况经常改变。如果图片非常大,而库存数非常小,如果我们每次要更新数据的时候都要刷新整个页面,对于服务器的压力就会很大。
对于这种高并发场景下的系统,在真正的业务逻辑之前,都需要有个接入层,将这些静态资源的请求拦在最外面。

对于静态资源,有Vanish缓存层。当缓存过期的时候,才会访问真正的Tomcat应用集群。
在HTTP头里面,Cache-control是用来控制缓存的。当客户端发送的请求中包含max-age指令时,如果判定缓存层中,资源的缓存时间数值比指定时间的数值小,那么客户端可以接受缓存的资源;当指定max-age值为0,那么缓存层通常需要将请求转发给应用集群。包含no-cache指令时,无缓存指令(Cache-control: no-cache)。
另外,If-Modified-Since也是一个关于缓存的。也就是说,如果服务器的资源在某个时间之后更新了,那么客户端就应该下载最新的资源;如果没有更新,服务端会返回“304 Not Modified”的响应,那客户端就不用下载了,也会节省带宽。同Last-Modified。
If-None-Match 客户端存取的该资源的检验值,在服务器上某个时段是唯一标识的。同ETag
到此为止,我们仅仅是拼凑起了HTTP请求的报文格式,接下来,浏览器会把它交给下一层传输层。怎么交给传输层呢?其实也无非是用Socket这些东西,只不过用的浏览器里,这些程序不需要你自己写,有人已经帮你写好了。
HTTP请求的发送
HTTP协议是基于TCP协议的,所以它使用面向连接的方式发送请求,通过stream二进制流的方式传给对方。当然,到了TCP层,它会把二进制流变成一个的报文段发送给服务器。
在发送给每个报文段的时候,都需要对方有一个回应ACK,来保证报文可靠地到达了对方。如果没有回应,那么TCP这一层会进行重新传输,直到可以到达。同一个包有可能被传了好多次,但是HTTP这一层不需要知道这一点,因为是TCP这一层在埋头苦干。
TCP层发送每一个报文的时候,都需要加上自己的地址(即源地址)和它想要去的地方(即目标地址),将这两个信息放到IP头里面,交给IP层进行传输。
IP层需要查看目标地址和自己是否是在同一个局域网。如果是,就发送ARP协议来请求这个目标地址对应的MAC地址,然后将源MAC和目标MAC放入MAC头,发送出去即可;如果不在同一个局域网,就需要发送到网关,还要需要发送ARP协议,来获取网关的MAC地址,然后将源MAC和网关MAC放入MAC头,发送出去。
网关收到包发现MAC符合,取出目标IP地址,根据路由协议找到下一跳的路由器,获取下一跳路由器的MAC地址,将包发给下一跳路由器。
这样路由器一跳一跳终于到达目标的局域网。这个时候,最后一跳的路由器能够发现,目标地址就在自己的某一个出口的局域网上。于是,在这个局域网上发送ARP,获得这个目标地址的MAC地址,将包发出去。
目标的机器发现MAC地址符合,就将包收起来;发现IP地址符合,根据IP头中协议项,知道自己上一层是TCP协议,于是解析TCP的头,里面有序列号,需要看一看这个序列包是不是我要的,如果是就放入缓存中然后返回一个ACK,如果不是就丢弃。
TCP头里面还有端口号,HTTP的服务器正在监听这个端口号。于是,目标机器自然知道是HTTP服务器这个进程想要这个包,于是将包发给HTTP服务器。HTTP服务器的进程看到,原来这个请求是要访问一个网页,于是就把这个网页发给客户端。
HTTP返回的构建
HTTP的返回报文也是有一定格式的。这也是基于HTTP 1.1的。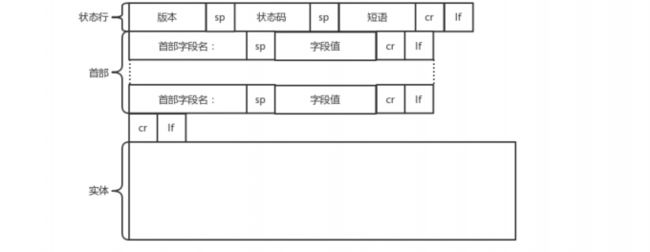
HTTP/1.1 200 OK
Server: Tengine
Date: Thu, 26 Dec 2019 06:52:14 GMT
Content-Type: application/json;charset=UTF-8
Content-Length: 252
Connection: close
X-Powered-By: ring/1.0.0
gsid: 011025248187157734313415200030229349471
sc: 0.006
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: *
Access-Control-Allow-Headers: DNT,X-CustomHeader,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,key,x-biz,x-info,platinfo,encr,enginever,gzipped,poiid
{"status":"1","count":"1","info":"OK","infocode":"10000","lives":[{"province":"北京","city":"东城区","adcode":"110101","weather":"晴","temperature":"2","winddirection":"西","windpower":"≤3","humidity":"23","reporttime":"2019-12-26 14:36:44"}]}状态码会反应HTTP请求的结果。“200”意味着请求成功;而“404”,也就是“服务端无法响应这个请求”
然后就是返回首部的key: value
其中Retry-After表示,告诉客户端应该在多长时间以后再次尝试一下。“503错误”是说“服务暂时不再和这个值配合使用”。
在返回的头部里面也会有Content-Type,表示返回的是HTML,还是JSON。
构造好了返回的HTTP报文,接下来就是把这个报文发送出去。还是交给Socket去发送,还是交给TCP层,让TCP层将返回的HTML,也分成一个个小的段,并且保证每个段都可靠到达。
这些段加上TCP头后会交给IP层,然后把刚才的发送过程反向走一遍。虽然两次不一定走相同的路径,但是逻辑过程是一样的,一直到达客户端。
客户端发现MAC地址符合、IP地址符合,于是就会交给TCP层。根据序列号看是不是自己要的报文段,如果是,则会根据TCP头中的端口号,发给相应的进程。这个进程就是浏览器,浏览器作为客户端也在监听某个端口。
当浏览器拿到了HTTP的报文。发现返回“200”,一切正常,于是就从正文中将HTML拿出来。HTML是一个标准的网页格式。浏览器只要根据这个格式,展示出一个绚丽多彩的网页。
这就是一个正常的HTTP请求和返回的完整过程。
DNS协议
如果要记得住网站的名称,但是很难记住网站的IP地址,因而也需要一个地址簿,就是DNS服务器。
由此可见,DNS在日常生活中多么重要。每个人上网,都需要访问它,但是同时,这对它来讲也是非常大的挑战。一旦它出了故障,整个互联网都将瘫痪。另外,上网的人分布在全世界各地,如果大家都去同一个地方访问某一台服务器,时延将会非常大。因而,DNS服务器,一定要设置成高可用、高并发和分布式的。
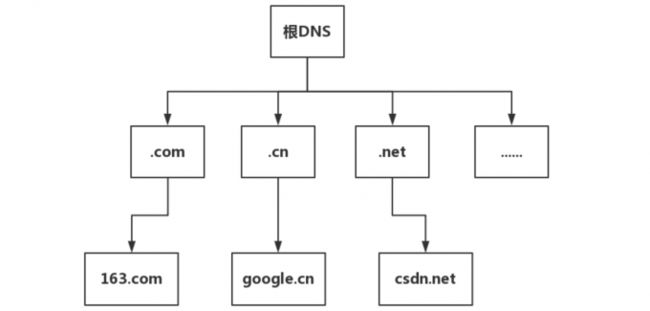
- 根DNS服务器 :返回顶级域DNS服务器的IP地址
- 顶级域DNS服务器:返回权威DNS服务器的IP地址
- 权威DNS服务器 :返回相应主机的IP地址
DNS解析流程
为了提高DNS的解析性能,很多网络都会就近部署DNS缓存服务器。于是,就有了以下的DNS解析流程。
- 电脑客户端会发出一个DNS请求,问www.163.com的IP是啥啊,并发给本地域名服务器 (本地DNS)。那本地域名服务器 (本地DNS) 是什么呢?如果是通过DHCP配置,本地DNS由你的网络服务商(ISP),如电信、移动等自动分配,它通常就在你网络服务商的某个机房。
- 本地DNS收到来自客户端的请求。你可以想象这台服务器上缓存了一张域名与之对应IP地址的大表格。如果能找到 www.163.com,它直接就返回IP地址。如果没有,本地DNS会去问它的根域名服务器:“老大,能告诉我www.163.com的IP地址吗?”根域名服务器是最高层次的,全球共有13套。它不直接用于域名解析,但能指明一条道路。
- 根DNS收到来自本地DNS的请求,发现后缀是 .com,说:“哦,www.163.com啊,这个域名是由.com区域管理,我给你它的顶级域名服务器的地址,你去问问它吧。”
- 本地DNS转向问顶级域名服务器:“老二,你能告诉我www.163.com的IP地址吗?”顶级域名服务器就是大名鼎鼎的比如 .com、.net、 .org这些一级域名,它负责管理二级域名,比如 163.com,所以它能提供一条更清晰的方向。
- 顶级域名服务器说:“我给你负责 www.163.com 区域的权威DNS服务器的地址,你去问它应该能问到。”
- 本地DNS转向问权威DNS服务器:“您好,www.163.com 对应的IP是啥呀?”163.com的权威DNS服务器,它是域名解析结果的原出处。为啥叫权威呢?就是我的域名我做主。
- 权限DNS服务器查询后将对应的IP地址X.X.X.X告诉本地DNS。
- 本地DNS再将IP地址返回客户端,客户端和目标建立连接。

如果我的文章对您有帮助,不妨点个赞鼓励一下(^_^)