数据参考模型DRM
数据参考模型的目标是通过标准的数据描述、通用数据的发现以及统一的数据管理实践的推广使得联邦政府实现跨机构的信息共享和重用。数据参考模型的适用范围很广,它可以用在一个机构内部,也可以用在某一个利益共同体(COI,Community of Interest,指的是一组为了实现共同利益和目标而相互合作的人或组织,而为了达成这一目标,他们需要一个共享的词汇表来实现信息共享)内或不同利益共同体之间。为了实现这一目的,数据参考模型采用了一种灵活的且基于标准的方式对数据的描述、分类和共享进行定义,因而数据参考模型的内容被划分为如下三个标准领域:

DRM标准领域及其关系
- 数据描述(Data Description):提供对于数据的统一描述方法,从而支持数据的发现和共享。
- 数据上下文(Data Context):采用某种分类法对数据进行归类,从而便于数据的发现。此外,数据上下文还使得定义一个利益共同体的权威数据资产(authoritative data assets)成为可能。
- 数据共享(Data Sharing):支持数据的访问和交换,其中数据访问是指单次性的特定请求(例如对于数据的查询),而数据交换指的是在不同团体之间经常性发生的针对于固定模式或需求的数据的往来交互事务(例如库存部门和审核部门之间经常需要对库存中的货物信息进行核对,虽然每次交互的货物信息的内容有所不同,但是其对于用于描述货物信息的数据模型却是早已确定好了的)。
数据参考模型作为一个参考模型为各机构提供了一套抽象的框架,而对于其具体实现就由各机构在符合参考模型原则的基础上自行决定了,从而为各机构对于数据方面的描述提供了巨大的灵活性。此外,由于各个机构可以将组成其数据架构的各种元素与该抽象框架相关联,从而使得原本隔绝的不同机构在数据方面得到了沟通途径,促进了不同机构之间的互操作。此数据参考模型所使用的抽象框架模型如下所示:

DRM抽象模型
数据参考模型的抽象模型为各机构用来进行信息集成、互操作、发现和共享的数据架构的优化提供了一套架构模式。为了达到这个目标,该抽象模型对数据架构概念元素以及他们之间的关系进行了明确定义,并且针对每个概念元素此抽象模型还分别定义了一系列的通用属性。此抽象模型按照上述三个标准区域被划分为三个部分,分别用于包含与这三个标准区域相关的概念元素及其关系。需要注意的是,由于这三个标准相互关联,因而上图所示的一些概念元素会出现多次,但是只有具有实线边框的概念元素才是其真正的定义,而虚线边框的概念元素则用来表示从其他标准区域“借用”而来的意义。
除了抽象模型之外,数据参考模型还包含了对于数据在安全和隐私方面的考虑。数据参考模型强调了在这三个标准区域中都需要遵循安全和隐私方面的策略,并允许现存的联邦安全和隐私策略被应用到这些标准区域中。
数据描述
数据描述标准区域的目标是为利益共同体提供关于数据结构(语法)和意义(语义)的共识。为了达成这一共识,利益共同体需要基于数据参考模型在这一标准区域中的内容创建各种相关的数据描述制品。关于数据标准领域的内容都已被定义在DRM抽象模型的相关部分中:

DRM数据描述模型
这一数据描述抽象模型在一个高度抽象的层次上对数据描述标准领域中涉及到的各种制品进行了抽象。从上面的数据描述模型中我们可以看出,数字数据资源(Digital Data Resource)可以分为两大类:
- 结构化数据:在数据描述模型中,结构化数据资源由数据模式(Data Schema)和结构化数据资源(Structured Data Resource)这两个部分组成。
- 数据模式为结构化数据资源的语法和语义进行了定义,可以说是结构化数据的元数据(Meta data)。在数据描述模型中,数据模式是通过实体(Entity)、属性(Attribute)、关系(Relationship)和数据类型(Data Type)这四个概念以及他们之间的关系来定义的。
- 结构化数据资源(Structured Data Resource)可以看作是遵守数据模式定义的实例化数据。
- 非结构化和半结构化数据(Unstructured /
Semi-structured Data Resource):除了结构化数据之外,现实中还存在着诸如视频数据、音频数据等非结构化数据,其与结构化数据的最大区别在于,非结构化数据的语义和语法与实例数据本身是紧密结合在一起的,因而一般来讲,其数据的组织结构和意义对外界并不具备很强的公开和交互性,而结构化数据与之相反,定义其数据结构和意义的数据模式信息可以独立于实例数据之外,用于在不同的数据交互团体之间进行针对语义和语法的交流。当然事实总不是那么绝对,数据参考模型的数据描述部分还定义了半结构化数据资源这一概念,用于代表同时包含结构化数据和非结构化数据的数据资源。在这部分模型中,一个名为文档(Document)的概念也被提了出来,而且还被定义为包含各种数字数据资源的容器。
按照OMB的数据参考模型中所述,这一部分模型中所涉及到的各种概念元素定义如下:
- 数据模式(Data Schema):对于元数据的一种表述,经常采用诸如逻辑数据模型或概念数据模型的形式。数据模式概念组包含了与结构化数据的表述相关的各个概念元素。一份数据模式为数据共享提供了独立于其所描述的具体数据值的语义。数据模式与其它概念元素之间具有如下关系:
- 数据模式定义了结构化数据资源。由于在数据参考模型中数据资源是一种信息容器的概念(通常来讲就是文件),所以这里的“结构化数据资源”实际上指的是用于存放数据模式这一元数据信息的信息容器,例如模式文件等。
-
数据模式描述了一个结构化数据资产。与数据资源类似,数据资产也是一个信息容器,只不过它指代的是一个托管容器(managed container),在大多数情况下指的是关系数据库,当然它还可以代表网站、文件资源库、字典或者数据服务。
-
实体(Entity):针对现实世界中客观事物的抽象。实体与其它概念元素之间具有如下关系:
- 实体包含若干属性。
- 实体通过“关系”观念元素与其他实体建立关联。
- 数据类型(Data Type):对于一个属性的物理表述的类型约束。
- 属性(Attribute):针对实体某一特性的抽象。属性与其它概念元素之间具有如下关系:
- 一个属性的取值受约束于一个数据类型
- 关系(Relationship):用于描述实体间的关系。“关系”概念元素与其它概念元素之间具有如下关系:
- 关系概念元素关联了参与此关系意义的各个实例。
- 数字数据资源(Digital Data Resource):用于描述一个信息的数字容器,一般来讲就是“文件”。数字数据资源按照其包含的数据类型分为三类:结构化数据资源、非结构化数据资源和半结构化数据资源,同时由于元数据本质上也是数据,因而一个数字数据资源还可以作为元数据的容器。数字数据资源与其它概念元素之间具有如下关系:
- 数字数据资源可以描述半结构化数据资产。
- 数字数据资源可以描述非结构化数据资产。
- 结构化数据资源(Structured Data Resource):用于包含结构化数据的数字数据资源。一旦数据模式可知,那么被其描述的数据将可以通过一种统一且独立于数据值的方式进行访问。结构化数据资源与其它概念元素之间具有如下关系:
- 结构化数据资源是数字数据资源的一种。
- 非结构化数据资源(Unstructured Data Resource):用于包含非结构化数据的数字数据资源。非结构化数据是一系列可能被某些特定应用程序进行处理的数据值的集合。非结构化数据资源与其它概念元素之间具有如下关系:
- 非结构化数据资源是数字数据资源的一种。
- 半结构化数据资源(Semi-structured Data Resource):用于包含半结构化数据的数字数据资源,即其包含的数据中一部分是结构化数据而另一部份是非机构化数据。半结构化数据资源与其它概念元素之间具有如下关系:
- 半结构化数据资源是数字数据资源的一种。
- 文档(Document):用于指代用来容纳数字数据资源的文件。文档与其它概念元素之间具有如下关系:
- 文档可以包含结构化、非结构化或半结构化数据资源。
- 文档可以对实体进行引用。例如,一份文档引用了“人”这个实体,因而就可以进行这样的查询:“寻找引用了如下个人的所有文档”。
数据上下文
数据上下文用于为数据添加与其被使用和创建的目标相关的意义,从而便于具有不同视角的数据消费者对于数据的发现和使用。经过数据描述的定义,利益共同体内或者他们之间对于数据的描述将会产生共识,但是这并不意味着具有不同视角的数据消费者就对所有的数据实体或者数据实体的所有属性都关心,甚至即便是针对某个数据实体的实例数据,不同的数据消费者由于其视角的不同也可能只对其中部分实例数据感兴趣。举例来说,假设一个名为“人”的实体,它对人进行了抽象并在利益共同体内根据所有参与者的共识定义了符合所有数据消费者要求的属性,但是在使用过程中,可能有更关注于商业行为方面的数据消费者从顾客的角度来看待人,因而对他来说诸如头发颜色之类的信息并不一定关注,而对于执法机构方面的数据消费者却不然。由此我们可以看出,数据可以根据不同的方式进行分类,而针对分类方式的描述和定义就构成了“数据上下文”。除了关于数据的分类划分这一核心概念,在数据参考模型中数据上下文相关的各种制品至少要能回答如下几个具体问题:
- 数据资产中数据的主题是什么?
- 什么组织负责维护数据资产?
- 数据与业务参考模型的关系是什么?
- 用于访问数据资产的服务都有哪些?
数据上下文的定义实际上就是针对数据使用背景的分类法的定义。虽然用来进行分类的角度纷繁复杂,但是本质上来讲不论何种分类法都可以通过结构化的方式进行表述,而这也为不同团体之间对于分类法的语义和语法的获得共识提供了基础。借由经过结构化表述的分类法定义,数据消费者可以识别符合自己要求的数据资产是否存在,并检测其包含的数据是否符合他对信息的要求。站在数据上下文的角度,其实前面讲述过的各个参考模型也是一种分类方法,因而数据上下文也可以看成是联系数据参考模型与其他参考模型的桥梁(例如,可以将数据按照不同的业务线或子功能进行划分,从而将数据参考模型与业务参考模型结合在一起)。

DRM数据上下文模型
上图展示了数据参考模型的抽象模型的数据上下文部分,它对数据上下文相关制品进行了定义。从图中可知:
- 关于数据上下文的分类法(Taxonomy)包含若干主题(Topic),而且主题之间是具有相互联系的。分类法被描述为结构化数据并存放于结构化数据资源中。为了与其他参考模型建立联系,在此图中其他参考模型作为分类方法的具体实现被表述出来,当然这并不排除其他分类方法的定义。
- 每个分类法的主题被用来为数据资产进行分类,同时也可以为各种数字数据资产、访问点和信息交换包进行分类。
- 可以为数据资产指定一个数据管理负责人。
按照OMB的数据参考模型中所述,这一部分模型中所涉及到的各种概念元素定义如下:
- 分类法(Taxonomy):一个通过层次结构进行组织的受控词汇(controlled vocabulary terms)的集合。分类法提供了一种通过使用合理且定义良好的缔合结构对信息进行分类的方法。分类法与其它概念元素之间具有如下关系:
- 分类法包含若干主题。
- 分类法被表述为结构化数据资源。
-
主题(Topic):分类法中的一个分类,它是为数据赋予上下文的核心概念元素。主题与其它概念元素之间具有如下关系:
- 主题对数据资产进行分类。
- 主题可以对数字数据资源进行分类。
- 主题可以对访问点进行分类。
- 主题可以对交换信息包进行分类。
- 主题通过“关系”概念元素与别的主题建立关联。
- 关系(Relationship):用于描述主题间的关系。关系概念元素与其它概念元素之间具有如下关系:
- “关系”概念元素关联了参与此关系主题概念元素。
- 数据资产(Data Asset):用于代表数据的托管容器。在很多情况下,数据资产代表着关系数据库,然而数据资产还可以被用来代表网站、文档库、字典或者数据服务。数据资产与其它概念元素之间具有如下关系:
- 数据资产为数字数据资源提供管理上下文。例如,一份被某个数据资产(例如文档库)存储和管理的文档会具有管理上下文,而此管理上下文是通过与那个文档关联并存储于文档库中的元数据来提供的。
- 数据管理员(Data Steward):用来代表对数据资产的管理负责的人。数据管理员与其它概念元素之间具有如下关系:
- 数据资产可以被数据管理员进行管理。
- 其他联邦企业架构参考模型(Other FEA Reference Model):用于代表其他的联邦企业架构参考模型。通过将其他参考模型看作为具体的分类方法,该概念元素在数据参考模型和其他参考模型之间搭建了关联。此概念元素与其它概念元素之间具有如下关系:
- 其他联邦企业架构参考模型是分类方法的具体类型。
数据共享
在定义了数据描述和数据上下文之后,利益共同体就需要把精力放在规划和实现信息访问及相互交换方面上面,而在数据参考模型中数据共享标准区域为这一方面能力的实现提供了参考。所谓信息互交换通常是指在信息生产者和信息消费者之间所存在的相对固定且时常发生的信息交互过程,而针对信息的使用除了这种互交换的方式外,作为信息源的信息生产者往往还需要对外提供各种信息访问接口和服务,从而为各种不确定的外界信息消费者提供信息访问的能力,而这种通过各种信息访问接口和服务而获取信息的能力就是信息访问能力。

数据提供和使用矩阵
如图可见,在信息交换和信息访问之间,除了前者一般是经常性或周期性地发生,而后者的发生则更具随机性之外,他们之间最大差别还在于信息交换对于参与双方在交换发生前就已经得到了明确,而信息访问则只是数据生产者提供信息访问的接口和服务,而对于数据的消费者却并不明确,即前者更加主动,而后者则采用了被动方式。不过无论是信息交换还是信息访问,他们都是在不同的数据资产之间进行的信息共享过程,因而要对这些信息共享方式进行归纳和建模,首先需要明确参与信息共享的各种信息存储系统。为了这些系统,数据共享标准领域采用了数据提供和消费矩阵(data supplier-to-customer matrix),从而将用于存储信息的各种数据资产进行了归纳整理。此矩阵从两个维度将参与信息共享的数据资产分为四种:
- 这两种纬度分别是:
- 根据所存信息的类型,数据资产可以分为用于存储和操作结构化数据的系统(图中第一、二象限)和用于存储和操作非结构化数据的系统(如图中第三、四象限)。
- 根据对信息所能进行的操作类型,数据资产又可以分为能够对数据进行全权操作(创建、更新和删除)的系统(如图中第一、三象限)和仅能针对数据进行检索与分析的系统(如图中第二、四象限)
- 根据这两种维度,能够参与信息共享的数据资产被分为如下四种系统:
- 事务数据库(Transactional Database):此种数据库包含了用于支持业务流程和工作流的结构化数据对象,并且经过精心的设计,这些数据库的事务性能往往能够得到高度的规范化和优化。通常此种类型的数据信息库包括了支持联机事务处理系统(OLTP)、企业资源管理系统(ERP),以及其他用于实现核心业务流程和工作流的后台系统数据库。通常来讲,由于执行业务逻辑和引用完整性的需要,用户并不能对此数据信息库中的数据直接进行创建、读取、更新和删除操作,而需要通过由应用程序接口(API)提供的各种服务来达成。
- 分析数据库(Analytical Database):此种数据库包含了用于支持查询和分析的结构化数据,并且为了提高查询方便性和效率,这些结构化的数据库倾向于有目的性地去规范化和优化。在此数据信息库中的数据一般来自于一个或多个事务数据库,并且以某种结构联合在一起来支持回答与业务和/或任务利益相关的特定问题。此数据信息库包括了联机分析(OLAP)、数据仓库(Data warehouse)、数据集市(Data mart),以及目录(例如支持轻量目录访问协议(LDAP)或者X.500的信息库)。一般来讲,存储在这种信息库中的数据可以通过查询进行直接访问,而针对数据的创建、更新和删除操作通常会通过间接方法(例如,抽取、转换和加载(ETL)过程)来对相关的事务数据库来进行。
- 著作系统信息库(Authoring Systems Repository):在数据参考模型的背景下,“文档”这个词的概念范围非常大,它涵盖了广大范围内的各种信息对象,例如多媒体、嵌入图片的文本文档、XML模式或文档类型定义(DTD)等。通常来讲,在这个背景下“著作系统”也同样具有广阔的范围。从一个极端来讲,一个著作系统可以是一个数码照相机,而在相反的另一极端,一个著作系统也可以是用于产生正规出版物的一个复杂工作流。虽然著作系统范围广阔,但是不论在哪个极端,著作系统的产物都是“文档”,而且著作系统底层的信息库也包括了各种能够保存数据对象的系统(最常见的例子就是文件系统和关系数据库)。与事务数据库类似,对于著作系统的底层信息库中的数据进行直接访问和操作是不提倡的,因为忽略业务逻辑而对数据进行的操作往往会影响数据的完整性。
- 文档信息库(Document Repository):与分析数据库类似,文档信息库的目标也是为了优化信息检索而对数据进行存储。此种信息库包括了网站的文件系统、内容管理系统之下的关系数据库,XML注册和信息库。同样与分析数据库类似,针对此种信息库中数据的操作一般只倾向于对其中数据的查询,而创建、更新和删除操作则通常并不对最终用户开放,而是通过一个由著作系统执行的发布功能来实现。
通过数据提供和消费矩阵针对上述四种数据系统的归纳,我们可以将数据交换和数据访问进行更进一步的具体化:
- 所谓数据交换就是在上述四种数据系统之间所进行的内容定义相对固定且时常发生的交换数据过程。这些数据交换过程以及他们所适用情景描述如下:
- 抽取、转换和加载(从结构化数据到结构化数据):在抽取、转换和加载(ETL)过程中,首先数据源中的结构化数据对象被读取(抽取)出来,然后将这些被抽取出来的数据的结构转换为符合目标数据库要求的结构(转换),最后使用转换后的数据更新目标数据库(加载)。用于执行ETL过程的各种服务可以非常复杂也可以是非常简单,同时他们也可以是其他服务的一个组成部分。这种类型的数据交换服务的信息载体是结构化数据。
- 发布(从结构化数据或文档到聚集后的文档):“发布”是一个将若干文档片段按照需要的格式组合在一起,并最终存入目标数据库的过程。此种类型的数据交换服务的信息载体是文档。
- 实体/关系抽取(从非结构化文档到结构化文档或结构化数据对象):实体/关系抽取是一个从文档中识别并抽取出特定元素的过程。在这个过程中,实体是指代特定的人、地点或事物的名词,而关系代表了实体之间的关联。一般来讲,在此过程中识别出来的实体可以作为元数据而合并到源文档之中,或被插入到一个独立的文档或结构化数据库中。此种类型的数据交换服务的信息载体是结构化数据。
- 文档翻译(从文档到文档):文档翻译是为了支持目标应用的需要,而将文档从一种形式转换为另一种的过程。这种转换可以是基于结构的,也可以是面向语言或其他特定目标的。此种类型的数据交换服务的信息载体是文档
| 数据交换服务 |
数据提供者 |
数据消费者 |
| 抽取、转换和加载 |
事务数据库 |
事务数据库 |
| 事务数据库 |
分析数据库 |
|
| 事务数据库 |
著作系统 |
|
| 分析数据库 |
事务数据库 |
|
| 分析数据库 |
分析数据库 |
|
| 分析数据库 |
著作系统 |
|
| 著作系统 |
事务数据库 |
|
| 著作系统 |
分析数据库 |
|
| 发布 |
事务数据库 |
文档信息库 |
| 分析数据库 |
文档信息库 |
|
| 著作系统 |
著作系统 |
|
| 著作系统 |
文档信息库 |
|
| 实体/关系抽取 |
文档信息库 |
事务数据库 |
| 文档信息库 |
分析数据库 |
|
| 文档翻译 |
文档信息库 |
著作系统 |
| 文档信息库 |
文档信息库 |
- 所谓数据访问就是上述各数据系统为了便于外界访问自身数据而对外提供的各种服务。
- 上下文获知服务(Context Awareness Services):此服务允许用户可以对利益共同体数据资产的上下文信息进行快速获取。上下文信息可以被存放在一个正规化的数据架构、元数据注册表或者是独立的数据库之中。上述所有的数据系统都应该提供这项服务。
- 结构获知服务(Structural Awareness Services):此服务允许数据架构师和数据库管理员能够快速地识别出存在于数据资产中的数据结构。数据描述信息可以被存放于一个正规化的数据架构、元数据注册表或者是独立的数据库之中。上述所有的数据系统都应该提供这项服务。
- 事务服务(Transactional Services):此服务使得在维护业务和引用完整性规则时,针对底层数据存储库的事务的创建、更新和删除操作成为可能。此服务允许外界服务或最终用户将执行数据相关的功能作为工作流或业务流程的一部分。在事务数据库和著作系统中需要提供此服务。
- 数据查询服务(Data Query Services):此服务允许用户、服务或者应用直接对信息库中的数据进行查询。在事务数据库和分析数据库中需要提供此服务。
- 内容搜索和发现服务(Content Search and Discovery Services):此服务允许自由文本搜索或者对信息库中各文档所包含的元数据的搜索,并且这些可进行搜索的元数据还应该包括数据上下文。在著作系统和文档信息库系统中需要提供此服务。
- 检索服务(Retrieval Services):此服务允许一个应用可以通过某一个唯一标识(例如URL)来请求返回信息库中的一份特定文档。在著作系统和文档信息库系统中需要提供此服务。
- 订阅服务(Subscription Services):此服务允许其他服务或最终用户在符合某预定义的策略或配置的前提下可以对自己进行提名,从而对新加入到信息库的文档进行自动化接收。在著作系统和文档信息库系统中需要提供此服务。
- 通知服务(Notification Services):此服务会依据某预定义的策略或配置,将信息库内容的变化通知给其他服务或最终用户。在事务数据库、著作系统和文档信息库系统中需要提供此服务。
| 访问服务 |
事务数据库 |
分析数据库 |
著作系统 |
文档信息库 |
| 上下文获知服务 |
√ |
√ |
√ |
√ |
| 结构获知服务 |
√ |
√ |
√ |
√ |
| 事务服务 |
√ |
× |
√ |
× |
| 数据查询服务 |
√ |
√ |
× |
× |
| 内容搜索和发现服务 |
× |
× |
√ |
√ |
| 检索服务 |
× |
× |
√ |
√ |
| 订阅服务 |
× |
× |
√ |
√ |
| 通知服务 |
√ |
× |
√ |
√ |
通过上述的关于数据系统的分类,以及针对他们之间进行信息交换和对外提供信息访问能力所需的各种服务的描述,利益共同体可以将各种数据资产和进行信息共享所需的各种服务进行分类总结,从而明确企业数据架构中关于信息共享这部分的内容。与数据描述和数据上下文一样,数据共享中所涉及到的各种制品的定义也体现在了数据参考抽象模型的数据共享部分:
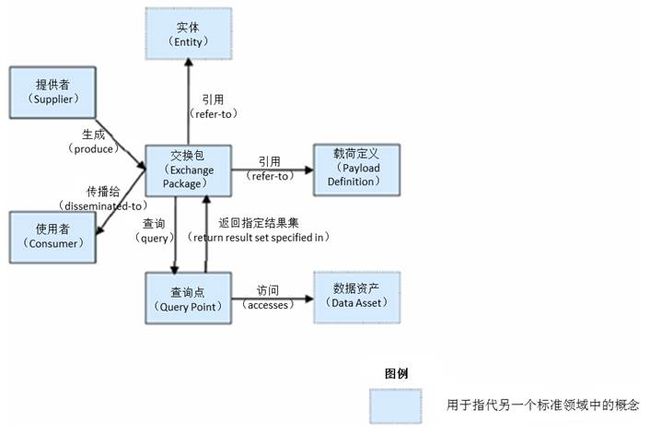
DRM数据共享模型
- 交换包(Exchange Package):用于表述产生于数据提供者和数据消费者之间的经常性的数据交换。交换包中包含了与交换过程相关的各种信息(例如数据提供者ID、数据消费者ID、数据有效期等),以及对于进行交换的数据载体的引用。交换包还可以被用来定义在一次信息交换中被某个查询点(Query point)接受与处理的查询结果的格式。交换包与其它概念元素之间具有如下关系:
- 交换包引用了实体。
- 交换包被传播给数据消费者。
- 交换包对查询点进行查询。
- 交换包引用了针对交换数据载体的定义。
- 数据提供者(Supplier):用于代表提供数据给数据消费者的实体。数据提供者与其它概念元素之间具有如下关系:
- 数据提供着产生交换包。
- 数据消费者(Consumer):用于代表对数据提供者产生的数据进行使用的实体。
- 数据载体定义(Payload Definition):用于代表针对在数据提供者和消费者之间进行交换的数据载体的需求而制定的电子化定义。
- 查询点(Query Point):用于代表为访问和查询数据资产而提供接口的端点。一个查询点的具体表达可以是一个特定的用于引发Web服务的URL。查询点与其概念元素之间具有如下关系:
- 查询点访问数据资产。