本文转载自微信公众号“七牛云”。
在 1 月 5 日 ECUG 大会的分享中 ,我司创始人兼 CEO 刘奇为大家带来了主题为《Chaos Engineering at PingCAP》的精彩演讲,和大家分享了关于 Chaos Engineering 的有关内容和深度思考。以下为演讲实录。

在演讲的开始,我先提一下 TiDB。TiDB 是一个分布式数据库,可以对外支持 MySQL 协议和 Spark API。TiDB 是目前在 NewSQL 领域目前使用规模最大、用户最多也是最火的数据库之一。

TiDB 典型场景是这样的:比如大家要做分库分表,用 TiDB 就不用折腾了;再比如大家如果需要复杂的 workload, 譬如 OLTP + OLAP 同时在系统里面是并存的情况。通常大家用数据库的时候会考虑是 OLAP 还是 OLTP,但是对用户来说,不希望数据库的人去教育他什么是 OLAP,什么是 OLTP,SQL 能足够快跑出来就可以了,使用要尽可能简单。还有一些用户,比如日本、美国的用户,是从 Amazon Aurora 迁移到 TiDB 上面的,当规模到几十 T 的时候,Aurora 跑起来就很吃力了。

我们再来说 PingCAP 是一家什么样的公司?可能大家都知道 TiDB,不知道 PingCAP。其实 TiDB 是 PingCAP 开发的。
那 CNCF 又是什么呢?CNCF 全称是云原生计算基金会。可能很多人知道 K8s 但是不知道 CNCF,就像大家知道 TiDB 不知道 PingCAP 是一样的道理,Kubernetes 是 CNCF 下面最火的一个项目。目前在整个 CNCF 所有代码贡献里面,PingCAP 在里面全球排名第六,在我们下面排名第七的是华为,前八名里面只有两家中国的公司。

接下来,我们会以 TiDB 为例,来具体演示 Chaos Mesh 的使用。首先,我们需要关注的是 TiDB 的结构。下图是 TiDB 的结构,为什么会讲 TiDB 的结构?

如图,TiDB 大体上分成两层:
- 计算层,就是大家通常理解的 SQL 层。
- 存储层,包括一个支持行存模型的 TiKV 和一个支持列存模型的 TiFlash。
除此之外,还有一个调度器 PD,负责对整个系统进行全局控制。
做数据库这个事情,当时入坑的时候并不知道这么难,后来才知道怎么这么难,我讲完以后大家可能觉得这个事更难。这几年我们遇到了编译器的 bug,遇到了操作系统的 bug,遇到文件系统的 bug,也被坑到过造成了数据的丢失,好在最终修复了。可能这些问题大家平时遇到的相对比较少,但是在我们这儿都遇到了,我们还遇到了某云存储厂商采购的某批磁盘硬件驱动有问题,写进去的数据和读出来的数据有一部分是不一样的。我不知道大家有没有遇到这些神奇的现象,但是作为一个数据库厂商,在我们这儿都遇到过。

上图是 GitHub 的一个页面,大家应该都见过,一年它会挂几次,如果大家足够幸运,应该会看到。这张图告诉我们什么呢?告诉我们的是你重新刷新可能就好了。当他说这个的时候,意味着他对这个情况是有预期、有处理的。我们的系统是不是也有这样的机制呢?比如出现一个什么问题,在用户侧大致怎么操作一下,就可以恢复。但最近 GitHub 又挂了一次,这次好像花了好几个小时才恢复。

这只黑天鹅就是我们这几年的体验。差不多前面十年写程序遇不到的问题,这几年全部遇到了。大家见到黑天鹅之前会觉得这个世界上天鹅全是白的,直到编译器和操作系统的 bug 把我们坑到的时候,我们才觉得自己没有那么幸运。
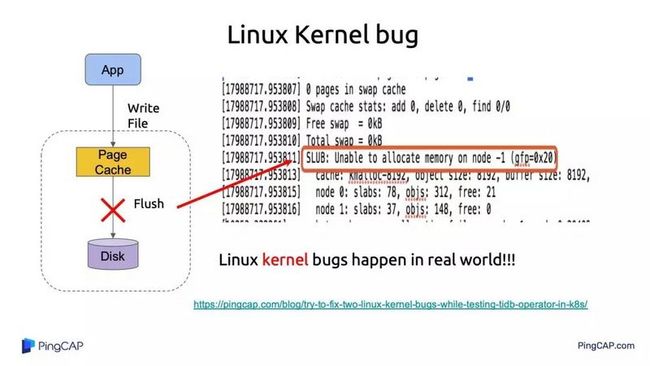
上图是我们遇到的一个操作系统 bug,我们后面还专门写了文章描述怎么找到这个 bug 的。大概意思是 Linux kernel 有一个 bug,明明有内存,但是内存分不出来,导致没法将 page cache 刷到磁盘上,丢失了数据。我想说的是操作系统 bug 离我们也挺近的,我们上面应用程序写得再好,后面也可能会在操作系统遇到问题。不过我们通常写程序的时候,这点考虑得比较少。
大家都觉得文件系统很稳定,应该没有遇到过文件系统的 bug,大家以前也不知道文件系统有这么脆弱,直到有一个工具出现了:它最早用来找安全漏洞,后来被用来找其他的系统漏洞。我们拿着这个工具去测试一下已有的文件系统,下图是遇到第一个 bug 的时间。

当时看来这些系统都是非常好的。Ext4 是被认为相当不错的,确实表现也不错,因为它扛了 2 小时才找到第一个 bug。最早我们推荐的两个文件系统是 Xfs 和 Ext4,后来有一次我们被 Xfs 坑到了,就把 Xfs 关掉不推荐了,所以我们现在只推荐 Ext4。这个工具很有意思,大家一目了然就知道文件系统成熟度是什么样的,谁能扛得最久,谁在现实中是最稳定的文件系统。所以有时候我们会在稳定性和性能之间,根据不同的业务要求来做选择。

说到 Chaos Engineering,我不知道大家会想起什么。Chaos 的中文翻译是混沌,可能混沌这个概念有点模糊,不过我们今天就来看它到底能解决什么问题。

上面是我刚刚创业的时候写的几篇文章,关于分布式系统测试的,当时就已经知道分布式系统测试无比困难。我记得我们要在几百个微服务里面找一个挂掉的微服务,这个很有意思,几百个微服务中那个抖动的微服务如果刚好是你存储相关的,或者和你登陆相关的,那么整个系统会是什么样的反应?用户就登陆不上去,或者登陆很卡,要么后面的操作会很卡。

这方面历史上的先行者是 Netflix,他们创建了一个叫做 Chaos monkey 的东西,就是在整个系统里面,随机地去 kill,比如几百几千个冗余服务,随机 kill 掉一个,来看系统会怎么样。
我不知道大家有没有人在线上真的做过这种测试,应该是没有的。之前我们提到过黑天鹅,当然不仅有黑天鹅还有墨菲定律,就是所有你觉得可能会出现的最后一定会出现。如果你自己不去 kill,它一定会被别人 kill 掉,各种意外都会有。
这里面比较有启发的一件事是 Netflix 在 2014 年创建了一个新的岗位,这个岗位就叫 Chaos engineer,是专门有个工程师做这件事,在线上去随机 kill 节点。到时候大家很可能面临的情况是,可能某一天半夜,研发突然被全部拉起来,所有人同时在查问题,却不知道问题在哪里。大家第一反应是「这不是我的问题」,甩锅一定要快。到底谁的问题呢?其实老板不关心到底是谁的问题,关心的是能不能尽快找到以及什么时候可以恢复。那么这个系统会帮你非常大的忙。
2019 年 12 月底,我们在 GitHub 上公开了这个项目,叫 Chaos Mesh,是目前 Star 数增长最快的一个项目之一。
它的思想很简单,通常情况下你系统有一个正常状态,所有人都知道,在这个正常状态下,你就开始做一些假设,比如说 kill 掉一个节点,我觉得应该出现什么情况。然后你去做实验,根据我的经验,通常大家假设都是不对的,你假设kill 这个节点以后,系统还是稳定的,过几秒它就恢复了,或者对系统没有什么多大影响,或者会稍微抖动一下。这个假设很可能是不靠谱的,因为它也许开始影响别人,别人又可能继续影响其他服务,在系统里面就像塞车一样,你发现塞车,只要它塞过的地方就会一直在塞车。
然后再去 verify 一下你刚才做的实验,你发现它是不靠谱的,然后去改进你的系统,再来一圈。这个思路很简单。

上面是我们为整个系统设计的图,我不知道大家看到这个 monkey 的时候有什么感受。我当时第一反应是中外文化太一致了,因为国外叫 Chaos Monkey,国内叫什么?中国有四大名著,很厉害的那只猴子叫什么?天庭以前从来没有想到过,一只猴子可以造成这么大的影响,最后得改整个体系,以便让这只猴子能融入整个体系。
这个跟 Chaos Monkey 的想法是一模一样的,你会让这只猴子融入你的系统,最终,你会把它吸纳到你的体系来。你不得不为它单独建一个职位,单独建一个体系,单独建一个流程。所以这个过程中,是不是中国几千年的文化跟老外的文化突然有了共同点,大家都一样,都需要猴子,一只猴子的效果非常好。在猴子出现之前,杨戬是无敌的,天庭的蟠桃也从没被偷吃过。
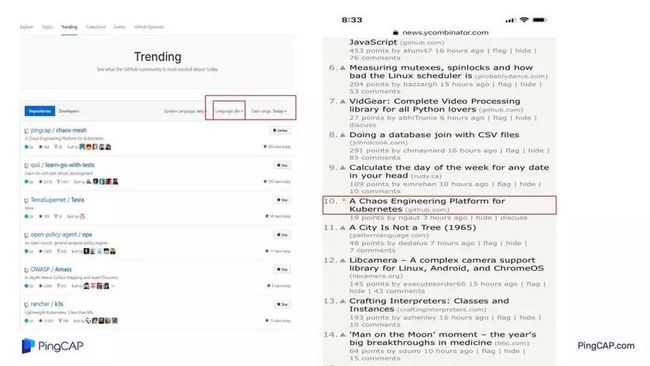
上图是我们开源之后的反应,马上就登上了 Go 语言的 trending 第一名,在 hacker news 上面也登上了首页,当时排名是第十。全世界人民都觉得这个很好,很欢欣很鼓舞,我们自己也是。
其实大家都想发明一只猴子,这只猴子可能是一般的猴子,也可能是孙悟空,到底我们需要什么样的猴子呢?所以,在做这个系统前我们做了一个调研,我们自己做的 Chaos Mesh 有哪些功能,我们做了哪些事。

比如 CPU burn,就是相当于,在一个系统里面你有一个进程把 CPU 都烧光,死循环,再不行,就多线程的死循环,总能把 CPU 吃得差不多,这个有点像什么呢?有点像 CPU 的过热,CPU 过热之后就开始降频,就是你的系统突然变慢了,很有可能是机房的通风不行,可能是一个小小的意外,你系统就变慢了,变慢了以后,你整个公司的业务是什么样的,没有人知道。最可怕的是老板不知道,老板不知道大家就比较辛苦,不管是谁的问题,全部叫起来。Mem burn 是内存分不出来,比如一个系统 20G 内存,突然一个程序占了 19G,你本来应该能够跑的没有内存了,这个很容易理解,让内存泄露,别的不擅长,这个太简单了。这些功能很好做,Chaos Mesh 目前还没有做而已,后面会马上支持。
讲了这么多好处,大家是不是想实战一下?我们很不好意思的贴出了一些猴子找到的 bug。

我们之前有个同事发了一条关于 Chaos Mesh 的朋友圈,他是这么说的,『以前我觉得自己写代码挺牛逼的』。我问了一句,『后来呢?』他说『不说了,连续几周都在修 bug』。相信我,大家的应用程序跑上来,不会有什么意外,都一样,因为你们从来没有测过这种情况,在这种情况下它的表现正常才奇怪,因为你都没定义这种情况正常是什么。大家有没有想过,你写进磁盘,在磁盘上读,读出来的数据不一样,程序什么表现?很可怕,有人程序没有挂,因为他自己写的东西他没有校验,写出来的数据在后面没有加一个校验符,下次读出来直接用了,天知道这是个什么结果。然后关键是它还没死,在系统里面接着跑,跑了以后影响别的,就像一个病毒在系统里面复制,结果是不可预期的。怎么办?这个系统都可以帮大家搞定。下面是我们自己找的一些 bug。
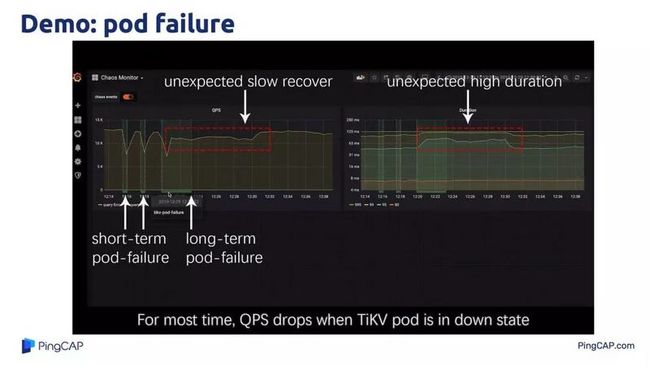
上图是一个 pod 跑数据库的过程,跑的过程中我们 kill 掉了前面大图里面的一个存储节点,我们的预期是 QPS 肯定会掉下来,后面会恢复。我们看起来好像是的,QPS 会掉 0,到 0 之后,大概过几秒钟好像又恢复了,看起来一切都正常。直到我们去观察整个系统的时候,会发现 QPS 的恢复花了相当长的一段时间,整个持续了大概有 10 分钟才恢复到正常值。我们的预期是 kill 掉之后很快应该能够恢复到正常值,但是它实际上没有做到。毫无疑问后来我们发现了一个 bug。


上图是它的用法,像一般的开源项目一样,先克隆下来,当然 K8s 有个好处,安装比较方便,三部曲就完了。完了以后就开始设定行为,比如说我整个系统里面想随机 kill 掉一些节点或者 kill 掉某一些节点,我应该怎么做,我选择我 kill 掉哪些标签的节点,kill 的方式什么样呢?每隔 2 分钟一次,这个配置很好理解。我们只要部署一下刚才的 YAML 文件就行,当我们不想做实验的时候,只要停掉整个实验,这个时候通常我们的系统应该是恢复的,这个时候是大家最紧张的时候,因为大概率你的系统是没有恢复的。这是我们的经验,总是能找到问题。

这是我们每隔 5 分钟 kill 掉一个节点的图,看起来 QPS 是这样的,最终都能回来。希望大家的线上系统看起来是这样,看起来还是正常的。
接下来是比较难的一部分,很多人可能对 K8s 是什么不太清楚,其实 K8s 相当于是一个操作系统,node 是相当于一台机器,operator 是相当于 systemd,pod 相当于 process,sidecar 相当于 thread,最后一个需要一点时间来理解。
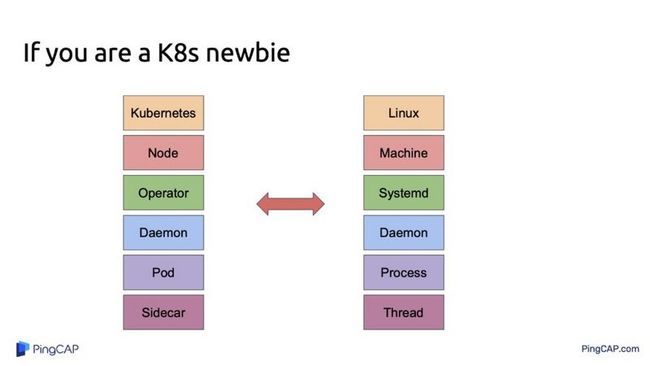
其实上面这么多,总结下来一句话就是 All in K8s,整个系统是完全基于 K8s 在用的,如果你的系统没有用 K8s,你没有办法用这套系统在上面做实验。有个很有意思的事,我们在美国跟用户聊,你用什么部署方式,我说我们用 Ansible。再问你们有没有 K8s?要是没有,那我就不看了。在美国就是这样,K8s 是一个政治正确的选择了,如果你的系统不是跑在 K8s 上面,就不用聊了,大家 match 不上。就像相亲一样,有车吗?有房吗?如果没有,再见。所以还没学的同学赶紧学一下,要不然以后跟美国人交流有困难。


这是它的整个结构,重点看 CRD 里面,可以构造的几种常见的错误,像网络分区、网络丢包、网络重发、带宽限制等等。然后是文件系统,我们可以进行文件操作,写出来的数据和读出来的数据不一样。或者是写入失败,或者读取失败。
Kubernetes 有 API Server,很好理解,你可以认为有 N 只猴子,每只猴子只做一件事,比如有一只猴子只做网络相关的,有一只就只做 I/O 相关的,本身都是 CRD。网络相关的使用的是 iptables,大家都知道 iptables 可以做网络上的各种操作,比如说隔离,比如说让数据只能进不能出等等,I/O 这边用的是 fuse。

这是常见的几种错误,这里看看 I/O delay,我们曾经遇到一个问题,某云盘,一次写入操作花了 5 秒,你知道大概率是哪里有个 bug,但是你不知道具体哪里有 bug。你就是起个虚拟机挂了个盘,最后一个操作 flush 5 秒,就一点点数据,肯定是哪里有个 bug,通常情况下大家觉得这个 disk 是本地的,没有问题。我印象中有人写过一篇文章说,比磁盘损坏更可怕的是什么?是不知道为什么一个磁盘读写速度只有原来的 1/10,就是它突然掉速了,这比坏掉更可怕。
下面这些图我们可以看出它是怎么 work 的。



再来谈下未来的计划,我们未来计划有 verifier,verifier 这边可以添加更多的功能,比如我可以在某个时间点可以做什么操作,甚至我中间替换数据然后再去观察系统状态是不是不对。当然也会增加一个好看好用的界面,现在整个是通过命令行去操作的。另外也希望能够支持多云的错误注入,大家也不要假设云上的服务都是 OK 的。程序都是人写的,黑天鹅一定会出现的。

最后说一下整个系统可观测性的重要性,我不知道大家有没有做过数据库运维,通常业务那边说我有一个什么问题,我的第一反应是你是什么 workload。对方跟你讲了半天,你问对方你是读多还是写多,读是写的多少倍。对方说我也不是太清楚,这时候怎么办?这时候就需要有一套系统,能够在不需要业务侧给你解释的时候,你就知道业务侧做的是什么事,因为业务侧给你解释也不一定准确,因为他有自己的理解,每个人理解不一样。这个很可怕,这时候如果有一套系统,能够很好地去观测,你什么也不用跟我讲了。
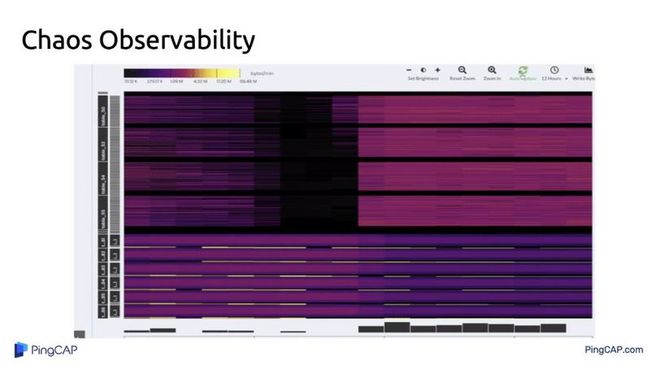
这个系统大概什么意思呢?大家可以看一下上图。这里面最亮黄色是什么意思呢?是整个系统的写入热点,写入热点是什么概念?它是一条这样倾斜的斜线,这条线告诉我们的是什么?我后面怎么操作数据库不用管,看一眼就知道,这代表这个系统里面现在有 6 个表一直在做追加数据的操作。比如我们看到上面一大片紫色的分布很均匀,意味着它的写入相对比较随机,所以数据库这一侧,你不用跟别人聊,你一看就知道你要做什么操作,几个表在追加,几个表在随机写,几个表在随机读,还是有几个热点,这个好处是什么?当出现问题的时候快速定位,有这样一套系统就清楚了
这是整个项目在 GitHub 上的 pingcap/chaos-mesh 上,也欢迎大家关注我们的 Twitter:chaos_mesh,以上就是我为大家带来的分享,谢谢大家。
原文阅读:https://mp.weixin.qq.com/s/dYv7neg6Pewbt1Mih_6c6Q?scene=25#wechat_redirect
